Two AI variants: rule-based and corpus-based
In the preceding post, I mentioned the two fundamental approaches to attempting to imbue computers with intelligence, namely the rule-based approach and the corpus-based approach. In a rule-based system, the intelligence is situated in a rule pool that is deliberately designed by people. In the corpus-based method, the knowledge is contained in the corpus, i.e. in a data collection which is analysed by a sophisticated program.
The performance of both methods has been massively boosted since the 1990s. The most impressive boost has been achieved with the corpus-based method, which is now regarded as the artificial intelligence proper and is making headlines across the board today. What, then, are the crucial improvements of the two methods? To begin with, we’ll have a look at how corpus-based AI works.
How does corpus-based AI work?
Corpus-based AI (c-AI) consists of two parts:
- the corpus,
- algorithms (neural network).
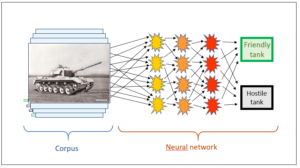
The corpus, which is also called learning corpus, is a collection of data. This can consist of photographs of tanks or faces, but also of collections of search queries, for instance of Google. What is important is that the corpus already contains the data in a weighted form. In the tank example, it has been written into the corpus whether the tanks are friendly or hostile. The collection of faces contains information about the owners of those faces. In the case of the search queries, Google records the links that a searcher clicks, i.e. which suggestion offered by Google is successful. Thus the learning corpus contains knowledge which the corpus-based AI is going to use.
Now the c-AI has to learn. The aim is for the AI to be able to categorise a new tank image, a new face or a new query correctly. For this purpose, the c-AI makes use of the knowledge in the corpus, i.e. the pictures of the tank collection, where it is noted for each image whether the tank is ours or foreign – as represented in Fig. 1.
Now the second component of the c-AI comes into play: the algorithm. Essentially, this is a neural network. It consists of several layers of “neurons” which pick up the input signals, process them and then transmit their own signals to the next higher level. Fig. 1 shows how the first (yellow) neuron layer picks up the signals (pixels) from the image and, after processing them, forwards its own signals to the next (orange) layer until finally, the network arrives at the result of “our tank” or “foreign tank”.
When the neural network is now shown a new image that has not been assessed yet, the process is precisely the same as with the other picture. If the network has been trained well, the program should be able to categorise on its own, i.e. the neural network should be able to discern whether the tank is ours or someone else’s
The significance of the data corpus for corpus-based AI
A corpus-based AI finds its detailed knowledge in the corpus that has been specially compiled for it and evaluates the connections which it discovers there. The corpus therefore contains the knowledge which the c-AI evaluates. In our example, the knowledge consists in the connection of the photograph, i.e. a set of wildly arranged pixels, with a simple binary piece of information (our tank/foreign tank). This knowledge is already part of the corpus before the algorithms conduct an evaluation. The algorithms of the c-AI thus do not detect anything that is not already in the corpus. However, the c-AI is now also able to apply the knowledge found in the corpus to new, unassessed cases.
The challenges for corpus-based AI
The challenges for c-AI are unequivocal:
- Corpus size: the more images there are in the corpus, the higher the certainty of the categorisation. A corpus that is too small will result in faulty results. The size of the corpus is crucial for the precision and reliability of the results.
- Hardware: the processing power required by a c-AI is very high and becomes higher the more precise the method is intended to be. Hardware performance is the decisive factor for the practical applicability of the method.
This quickly clarifies how c-AI has been able to improve its performance so impressively in the last two decades:
- The data volumes which Google and other organisations are capable of collecting in the internet have increased drastically. In this respect, Google profits from quite an important amplification effect: the more queries Google receives, the better the corpus and thus its hit rate. The better the hit rate, the more queries Google will receive.
- The hardware that is required to evaluate the data is becoming less expensive and more performant. Today, internet companies and other organisations operate huge server farms, without which the processor-intensive evaluations would not be possible in the first place.
Besides the corpus and the hardware, the sophistication of the algorithms naturally also plays a part. However, the algorithms were not bad even decades ago. In comparison with the other two factors – hardware and corpus – the progress made in the field of algorithms only plays a modest part in the impressive success of c-AI.
The success of corpus-based AI
The challenges for c-AI were tackled by the big corporations and organisations extremely successfully.
The above description of the operating mode of c-AI, however, should also reveal the weaknesses immanent in the system, which are accorded less media attention. I will discuss them in more detail in a later post.
Next we will have a look at the challenges for rule-based AI.
This is a post about artificial intelligence.
Translation: Tony Häfliger and Vivien Blandford