Examples of information reduction
In previous texts we looked at examples of information reduction in the following areas:
- Coding / classification
- Sensory perception
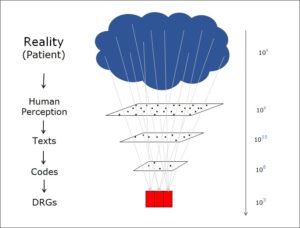
- DRG (Flat rate per case)
- Opinion formation
- Thermodynamics
What do they have in common?
Micro and macro state
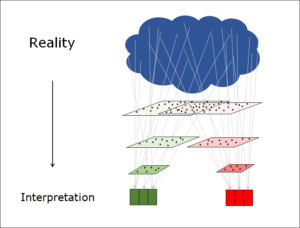
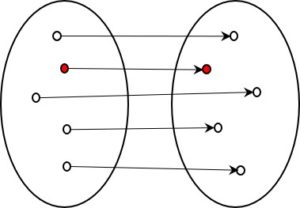
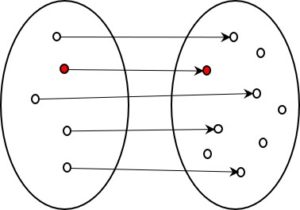
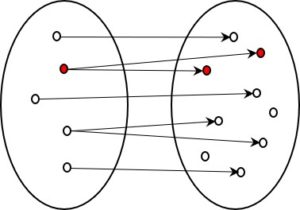
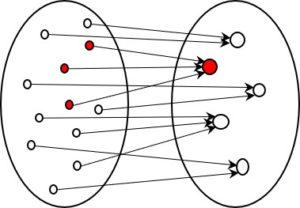
What all these examples have in common is that, in terms of information, there are two states: a micro state with a great many details and a macro state with much less information. One very clear example that many of us will remember from our school days is the relationship between the two levels in thermodynamics.
The two states exist simultaneously, and have less to do with the object itself than with the perspective of the observer. Does he need to know everything, down to the last detail? Or is he more interested in the essence, i.e. the simplified information of the macro state?
Micro and macro state in information theory
The interplay of micro and macro states was first recognised in thermodynamics. In my opinion, however, this is a general phenomenon, which is closely linked to the process of information reduction. It is particularly helpful to differentiate between the two states when investigating information processing in complex situations.
Wherever the amount of information is reduced, a distinction can be drawn between a micro and a macro state. The micro state is the one that contains more information, the macro state less. Both describe the same object, but from different perspectives.
The more detailed micro state is considered to be ‘more real’
We tend to think we are seeing something more clearly if we can discern more details. So we regard the detailed micro state as the actual reality and the macro state as either an interpretation or a consequence of this.
… but the low-information macro state is more interesting
Remarkably, however, the low-information state is of more interest to us than the micro state. In the micro state, there are simply too many details. These are either irrelevant to us (thermodynamics, sensory perception) or they obstruct our clear view of the goal represented by the macro state (coding, classification, opinion-forming, flat rate per case).
Strange antagonism
There is thus a strange antagonism between the two states, with one seeming more real and the other more relevant, as if these two qualities were somehow at odds with one another. The more detailed the information, the less the many single data points have to do with the overall perspective, which thus increasingly disappears from sight. On the other hand: the more intensively the view strives for relevance, the more it detaches itself from the details of reality. This paradoxical relationship between micro and macro state is characteristic of all information reduction relationships and highlights both the importance of, and the challenges associated with, such processes.
Are there differences between the various processes of information reduction?
Absolutely. The only thing they have in common is that it is possible to display the data at a detailed micro level or at a macro level containing little information, with the latter usually being more relevant.
Such processes always involve a reduction in information, but the way in which it is reduced differs. At this point it would be illuminating to examine the differences – which play a decisive role in many issues – more closely. Read more in next post.
This is a page about information reduction — see also overview.
Translation: Tony Häfliger and Vivien Blandford
 A glass of water contains a huge amount of water molecules, all moving at different speeds and in different directions. These continuously collide with other water molecules, and their speed and direction of travel changes with each impact. In other words, the glass of water is a typical example of a real object that contains more information than an external observer can possibly deal with.
A glass of water contains a huge amount of water molecules, all moving at different speeds and in different directions. These continuously collide with other water molecules, and their speed and direction of travel changes with each impact. In other words, the glass of water is a typical example of a real object that contains more information than an external observer can possibly deal with.