AI in the last century
AI is a big buzzword today but was already of interest to me in my field of natural language processing in the 1980s and 1990s. At that time, there were two methods which were occasionally labelled AI, but they could not have been more different from each other. The exciting thing is that these two different methods still exist today and continue to be essentially different from each other.
AI-1: vodka
The first method, i.e. the one already used by the very first computer pioneers, was purely algorithmic, i.e. rule-based. Aristotle’s syllogisms are a paradigm of this type of rule-based system:
Premise 1: All human beings are mortal.
Premise 2: Socrates is a human being.
Conclusion: Socrates is mortal.
The expert posits premises 1 and 2, the system then draws the conclusion autonomously. Such systems can be underpinned mathematically. Set theory and first-order logic are often regarded as a safe mathematical basis. Theoretically, such systems were thus waterproof. In practice, however, things looked somewhat different. Problems were caused by the fact that even the smallest details had to be included in the rule system; if they were not, the whole system would “crash”, i.e. draw completely absurd conclusions. The correction of these details increased disproportionately to the extent of the knowledge that was covered. At best, the systems worked for small special fields for which clear-cut rules could be found; when it came to wider fields, however, the rule bases were too large and were no longer maintainable. A further serious problem was the fuzziness which is peculiar to many expressions and which is difficult to grasp with such hard-coded systems.
Thus this type of AI came in for increasing criticism. The following translation attempt may serve as an example of why this was the case. An NLP program translated sentences from English into Russian and then back again. The input of the biblical passage “The spirit is willing but the flesh is weak.” resulted in the retranslation “The vodka is good but the meat is rotten.”
This story may or may not have happened precisely like this, but it demonstrates the difficulties encountered in attempts to capture language with rule-based systems. This example demonstrates the difficulties encountered in attempts to capture language with rule-based systems. The initial euphoria associated with the “electronic brain” and “machine intelligence” since the 1950s fizzled out, the expression “artificial intelligence” became obsolete and was replaced by the term “expert system”, which sounded less pretentious.
Later, in about 2000, the stalwarts of rule-based AI were buoyed up again, however. Tim Berners-Lee, the pioneer of the WWW, launched the Semantic Web initiative with the purpose of improving the usability of the internet. The experts of rule-based AI, who had been educated at the world’s best universities, were ready and willing to establish knowledge bases for him, which they now called ontologies. With all due respect to Berners-Lee and his efforts to introduce semantics to the net, it must be said that after almost 20 years, the Semantic Web initiative has not substantially changed the internet. In my view, there are good reasons for this: the methods of classic mathematical logic are too rigid to map the complex processes of thinking – more about this in other posts, particularly on static and dynamic logic. At any rate, both the classic rule-based expert systems of the 20th century and the Semantic Web initiative have fallen short of the high expectations.
AI-2: tanks
However, there were alternatives which tried to correct the weaknesses of rigid propositional logic as early as the 1990s. For this purpose, the mathematical toolkit was extended.
Such an attempt was fuzzy logic. A statement or a conclusion was now no longer unequivocally true or false; rather, its veracity could be weighted. Besides set theory and predicate logic, probability calculus was now also included in the mathematical toolkit of the expert systems. Yet some problems remained: again, there had to be precise and elaborate descriptions of the rules that were applicable. Thus fuzzy logic was also part of rule-based AI, even though is was equipped with probabilities. Today, such programs work perfectly well in small, well-demarcated technical niches, beyond which they are insignificant.
At that time, another alternative was constituted by the neural networks. The were considered to be interesting; however, their practical applications tended to attract some derision. To illustrate this, the following anecdote was bandied about:
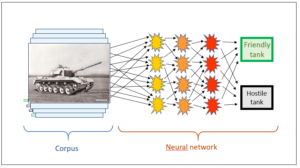
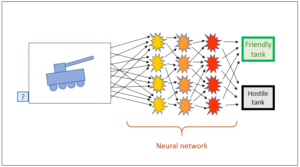
The US Army – which has been an essential driver of computer technology all along – is supposed to have set up a neural network for the identification of US and foreign tanks. A neural network operates in such a way that the final conclusions are found through several layers of conclusions by the system itself. People need not input any rules any longer; they are generated by the system itself.
How is the system able to do this? It requires a learning corpus for this purpose. In the case of tank recognition, this consisted of a series of American and Russian tanks. Thus it was known for every photograph whether it was American or Russian, and the system was trained until it was capable of generating the required categorisation itself. The experts only exerted an indirect influence on the program in that they established the learning corpus; the program compiled the conclusions in the neural network autonomously – without the experts knowing precisely what rules the system used to draw which conclusions from which details. Only the result had to be correct, of course. Now, once the system had completely integrated the learning corpus, it could be tested by being shown a new input, for instance a new tank photo, and it was expected to categorise the new image correctly on the basis of the rules it had found in the learning corpus. As mentioned before, this categorisation was conducted by the system on its own, without the experts exerting any further influence and without them knowing how conclusions were drawn in a specific case.
It was said that this worked perfectly with regard to tank recognition. No matter how many photos were shown to the program, the categorisation was always spot on. The experts could hardly believe that they had really created a program with a 100% identification rate. How could this be? Ultimately, they discovered the reason: the photos of the American tanks were in colour, those of the Russian tanks were in black and white. Thus the program only had to recognise the colour; the contours of the tanks were irrelevant.
Rule-based vs corpus-based
The two anecdotes show what problems were lying in wait for rule-based and corpus-based AI at the time.
- In the case of rule-based AI (vodka), they were
– the rigidity of mathematical logic,
– the fuzziness of our words,
– the necessity to establish very large knowledge bases,
– the necessity to use specialist experts for the knowledge bases.
- In the case of corpus-based AI (tanks), they were
– the lack of transparency of the paths along which conclusions were drawn,
– the necessity to establish a very large and correct learning corpus.
I hope that I have been able to describe the characters and modes of operation of the two AI types with the two above (which admittedly are somewhat unfair) examples, including the weaknesses with characterise each type.
Needless to say, the challenges persist. In the following posts I will show how the two AI types have reacted against this and where the intelligence now really resides in the two systems. To begin with, we’ll have a look at corpus-based AI.
This is a blog post about artificial intelligence.
Translation: Tony Häfliger and Vivien Blandford