Words and their Objects
When we speak, we use words to describe the objects in our environment. With words, however, we do not possess the objects, but only describe them, and as we all know, words are not identical to the objects they describe. It is obvious that there is no identity.
Some funny examples of the not always logical use of words can be found in the following text (in German), which explains why the quiet plays loudly and the loud plays quietly.

Fig 1: The piano (the quiet one)

Fig. 2: The lute (the wood)
But how does the relationship between words and objects look if it is not an identity? It cannot be a 1:1 relationship, because we use the same word to describe different objects. Conversely, we can use several words for the same object. The relationship is not fixed either, because the same word can mean something different depending on the context. Words change relentlessly over time, they change their sound and their meaning.
The relationship between words and designated objects is clearly illuminated by Ogden and Richards’1 famous depiction of the semiotic triangle from 1923.
The Semiotic Triangle
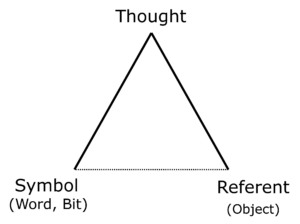
Fig 3: The semiotic triangle according to Ogden and Richards1
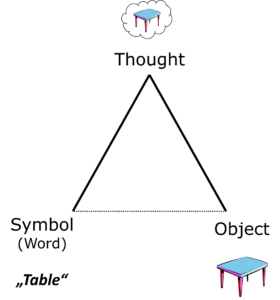
Fig 4: The semiotic triangle exemplified by the word ‘table’
The idea of the triangle has many predecessors, including Gottlob Frege, Charles Peirce, Ferdinand de Saussure and Aristotle.
Ogden and Richards use the semiotic triangle to emphasise that we should not confuse words, objects and concepts. The three points of the triangle point to three areas that are completely different in nature.
The tricky thing is that we are not just tempted but entirely justified in treating the three points as if they were identical. We want the word to describe an object precisely. We want our concepts to correspond exactly with the words we use for them. Nevertheless, the words are not the objects, nor are they concepts.
Ogden and Richards have this to say: «Between the symbol [word] and the referent [object] there is no other relevant relationship than the indirect one, which consists in the fact that the symbol is used by someone [subject] to represent a referent.»
The relationship between the word (symbol, sign) and the object (referent) is always indirect and runs via someone’s thought, i.e. the word activates a mental concept in ‘someone’, i.e. a human subject, speaker or listener. This inside image is the concept.
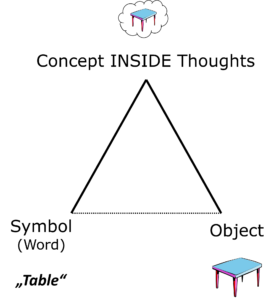
Fig. 5: This is how Ogden and Richards see the indirect relationship between symbol and indicated object (referent). The thoughts contain the concepts.
The diminished baseline in Fig. 5 can also be found in the original of 1923. Symbol (word) and referent (reference object) are only indirectly connected via the thoughts in the interpreting subjects. This is where the mental concepts are found. The concepts are the basic elements of our thoughts.
When we deal with semantics, it is essential to take a look at the triangle. Only the concepts in our head connect the words with the objects. Any direct connection is an illusion.
This is a post on the topic of semantics.
Translation: Juan Utzinger
1 Ogden C.K. und Richards I.A. 1989 (1923): The Meaning of Meaning. Orlando: Harcourt.