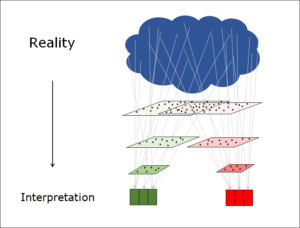
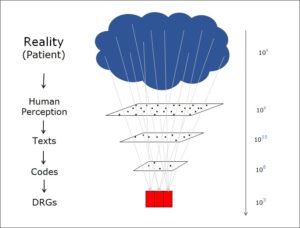
Two states at the same time
In my last article I showed how a system can be described at two levels: that of the micro and that of the macro state. At the micro level, all the information is present in full detail; at the macro level there is less information but what there is, is more stable. We have already discussed the example of the glass of water, where the micro state describes the movement of the individual water molecules, whereas the macro state encompasses the temperature of the liquid. In this paper I would like to discuss how different the relationship between micro and macro states can be.
Does the macro state depend on the micro state?
In terms of its information content, the macro state is always smaller than the micro. But does it have an existence of its own at all, or is it simply a consequence of the micro state? To what extent is the macro state really determined by the micro state? In my opinion, there are major differences between the different situations in this respect. This becomes clear when we consider the question of how to predict the future of the systems.
Glass of water
If we know the kinetic energy of the many individual molecules that make up a glass of water, we also know its temperature – the macro state can be deduced from knowledge about the micro state. In this case, we also know how it will develop: if the system remains closed, the temperature will remain constant. The macro state remains the same, even though there is a lot of information speeding around in the micro state. The temperature only changes when external influences – and in particular energy flows – come to bear. So, why does the temperature remain the same? It all comes down to the law of conservation of energy. The total amount of energy in the closed system remains constant, which means that however the variables in the micro state change, the macro state remains the same.
But why does the law of conservation of energy apply? This is closely linked to the Hamilton principle or principle of least action. This is one of the most fundamental rules in nature and by no means confined to thermodynamics.
The closed thermodynamic system is an ideal system that hardly ever occurs in such a pure form in nature; in reality, it is always an approximation. Let us now compare this abstract system with some systems that really do exist in the natural world.
Water waves and Bénard cells
This type of system can be observed as a wave on the surface of a body of water. In my opinion, Bénard cells, as described in the work of Prigogine, fall into the same category. In both cases, the macroscopic structures come into being as open systems. Both cells and waves can only arise due to external influences, with Bénard cells forming due to temperature gradient and gravity, and water waves forming due to wind and gravity. The structures arise due to the effects of these external forces, which interact to produce macroscopic structures that, interestingly enough, remain in place for long periods. Their persistence is astonishing. Why does the wave maintain its shape, when the particles of matter it is made up of are constantly changing?
The macroscopic structures formed in such open systems are much more complex than those of an isolated thermal system. Opposing external forces (such as wind and gravity) give rise to completely new forms – waves and cells. The external forces are necessary for the form to emerge and persist, but the resulting macroscopic form itself is new and is not inherent to the external forces, which are very simple in terms of information content.
Just like in the thermal system, we have two levels here: the macro level of the simple outer form (cell or wave) and a micro level of the many molecules that make up the body of this form. And, once again, the macro level – i.e. the form – is much simpler in terms of information content than the micro level, which consists of a huge number of molecules. The wave retains its shape over a long period of time, while the underlying molecules move about frantically. The wave continues to roll, capturing new molecules along the way, which now make up the wave. At given any moment the form, i.e. the coming together of the macro state from the individual molecules, appears completely determined. The information that makes up the form, however, is much easier to grasp at the macro level. The movements of the many individual molecules that make up the wave are there, but do not seem necessary to describe the form of the wave. It looks as though the new macro state is best explained by the old one.
In contrast to more highly developed organisms, the structure of both water waves and Bénard cells disappears as soon as the forces from outside diminish. Our own existence, like that of any other organic life, depends on structures that are much slower to disappear. That is to say: the macro state needs strengthened in relation to the micro state.
The thermostat
The macro state can be bolstered by giving it a controller. Imagine a heating system with a temperature sensor. When the temperature drops, the heating comes on; when it gets too high, the heating goes off. This keeps the temperature, i.e. the macro state, constant. But, of course, this heating system is anything but closed from a thermodynamic point of view. And temperature sensors and control systems to support the macro state and keep it constant are a human invention, not a naturally occurring phenomenon like water waves. Does such a thing exist in the natural world?
Autopoiesis and autopersistence
Of course, such control systems are also found in nature. During my medical studies I was impressed by the number and complexity of control circuits in the human organism. Control is always based upon information. The study of medicine made it evident to me that information is an essential part of the world.
The automatic formation of the wave or Bénard cell is a phenomenon known as autopoiesis. Waves and cells are not stable, but biological organisms are – or, at any rate, they are much more stable than waves. This is because biological organisms incorporate their own control systems. It’s as if a wave were to become aware of its own utter dependency on the wind and respond by actively seeking out its source of sustenance (the wind) or by creating a structure within itself to preserve its energy for the lean times when the wind is not blowing.
This is exactly what the human body – and in fact every biological body – does. It is a macro state that can maintain itself by controlling its micro state and deploying control processes in response to its environment.
Biological systems
This type of system differs from insulated thermal systems by its ability to create shapes, and from simple, randomly created natural shapes such as a water wave by its ability to actively assist the shape’s survival. This is because biological systems can respond to their environment to ensure their own survival. Biological systems differ from the simpler autopoietic systems in their ability to maintain a constant shape for longer thanks to complex internal controls and purposeful activity in response to their environment.
If a system is to maintain a constant form, it needs some kind of memory to preserve the pattern. And, if it is to respond purposefully to its environment, it helps if it has some kind of idea about this outside world. Both this memory of its own pattern and the simplified idea about the outside world need to be represented as information within the biological system information, otherwise it will not be able to maintain its form over time. The biological system thus has some kind of information-based interior. Because of the properties described above, biological systems are always interpreting systems.
This is an article from the series Information reduction.
Translation: Tony Häfliger and Vivien Blandford
 A glass of water contains a huge amount of water molecules, all moving at different speeds and in different directions. These continuously collide with other water molecules, and their speed and direction of travel changes with each impact. In other words, the glass of water is a typical example of a real object that contains more information than an external observer can possibly deal with.
A glass of water contains a huge amount of water molecules, all moving at different speeds and in different directions. These continuously collide with other water molecules, and their speed and direction of travel changes with each impact. In other words, the glass of water is a typical example of a real object that contains more information than an external observer can possibly deal with.