Two types of coding
In a previous post, I described two fundamentally different types of coding. In the first, the intention is to carry all the information contained in the source over into the encoded version. In the second, on the other hand, we deliberately refrain from doing this. It is the second – the information-losing – type that is of particular interest to us.
When I highlighted this difference in my presentations twenty years ago and the phrase ‘information reduction’ appeared prominently in my slides, my project partners pointed out that this might not go down too well with the audience. After all, everyone wants to win; nobody wants to lose. How can I promote a product for which loss is a quality feature?
Well, sometimes we have to face the fact that the thing we have been trying to avoid at all costs is actually of great value. And that’s certainly the case for information-losing coding.
Medical coding
Our company specialised in the encoding of free-text medical diagnoses. Our program read the diagnoses that doctors write in free text in their patients’ medical records and automatically assigned them a code based upon a standard coding system (ICD-10) with about 15,000 codes (Switzerland, 2019). This sounds like a lot, but the number is small considering the billions of distinguishable diagnoses and diagnostic formulations that occur in the field of medicine (see article). Of course, the individual code cannot contain more information than the standard code is able to discern for the case in question. The full-text diagnoses usually contained more information than this and our task was to automatically extract the relevant parts from the free texts in order to assign the correct code. We were fairly successful in this attempt.
Coding is part of a longer chain
But coding is only one step in a bigger process. Firstly, the information-processing chain extends from codes to flat rates per case (Diagnosis Related Groups = DRGs). Secondly, the free texts to be coded in the medical record are themselves the result of a multi-stage chain of information processing and reduction that has already been performed. Overall, a hospital case involves a chain made up of the following stages from patient examination to flat rate per case:
- Patient: amount of information contained in the patient.
- Doctor: amount of information about the patient that the doctor recognises.
- Medical record: amount of information documented by the doctor.
- Diagnoses: amount of information contained in the texts regarding the diagnoses.
- Codes: amount of information contained in the diagnosis codes.
- Flat rate per case: amount of information contained in the flat rate per case.
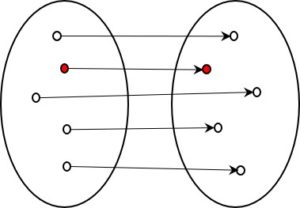
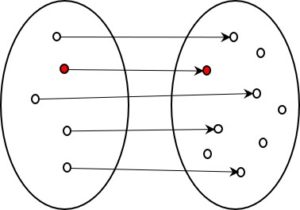
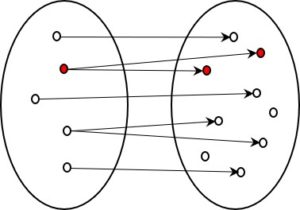
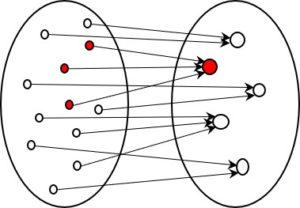
The information is reduced at every step, usually quite dramatically. The question is, how does this process work? Can the reduction be automated. And is it a determinate process, or one in which multiple options exist?
This is a page about information reduction — see also overview.
Translation: Tony Häfliger and Vivien Blandford