A simple broken bone
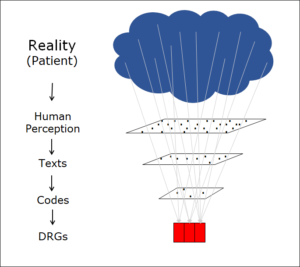
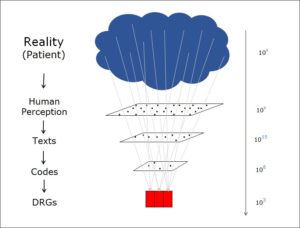
In the world of healthcare, medical diagnoses are encoded to improve transparency. This is necessary because they can be formulated in such a wide variety of different ways. For example, a patient may suffer from the following:
– a broken arm
– a distal radius fracture
– a fractura radii loco classico
– a closed extension fracture of the distal radius
– a Raikar’s fracture, left
– a bone fracture of the left distal forearm
– an Fx of the dist. radius l.
– a Colles fracture
Even though they are constructed from different words and abbreviations, all the above expressions can be used to describe the same factual situation, some with more precision than others. And this list is by no means exhaustive. I have been studying such expressions for decades and can assure you without any exaggeration whatsoever that there are billions of different formulations for medical diagnoses, all of them absolutely correct.
Of course, this huge array of free texts in all variations cannot be processed statistically. The diagnoses are therefore encoded, often using the ICD (International Classification of Diseases) system, which comprises between 15,000 and 80,000 different codes depending on variant. That’s a lot of codes, but much clearer than the billions of possible text formulations it replaces.
Incidentally, the methods used to automate the interpretation of texts so that it can be performed by a computer program are a fascinating subject.
Morse code
Morse code is used for communication in situations where it’s only possible to send very simple signals. The sender encodes the letters of the alphabet in the form of dots and dashes, which are then transmitted to the recipient, who decodes them by converting them back into letters. An E, for example, becomes a dot and an A becomes a dot followed by a dash. The process of encoding/decoding is perfectly reversible, and the representation unambiguous.
Cryptography
In the field of cryptography, too, we need to be able to translate the code back into its original form. This approach differs from Morse code only in that the translation rule is usually a little more complicated and is known only to a select few. As with Morse code, however, the encrypted form needs to carry the same information as the original.
Information reduction
Morse code and cryptographic codes are both designed so that the receiver can ultimately recreate the original message. The information itself needs to remain unchanged, with only its outer form being altered.
The situation is quite different for ICD coding. Here, we are not dealing with words that are interchangeable on a one-for-one basis such as tibia and shinbone – the ICD is not, and was never intended to be, a reversible coding system. Instead, ICD codes are like drawers in which different diagnoses can be placed, and the process of classification involves deliberately discarding information which is then lost for ever. This is because there is simply too much detail in the diagnoses themselves. For example, a fracture can have the following independent characteristics:
– Name of the bone in question
– Site on the bone
– State of the skin barrier (open, closed)
– Joint involvement (intra-articular, extra-articular)
– Direction of the deformity (flexion, extension, etc.)
– Type of break line (spiral, etc.)
– Number and type of fracture fragments (monoblock, comminuted)
– Cause (trauma, tumour metastasis, fatigue)
– etc.
All these characteristics can be combined, which multiplies the number of possibilities. A statistical breakdown naturally cannot take all combination variants into account, so the diagnostic code covers only a few. In Germany and Switzerland, the ICD can cope with fewer than 20,000 categories for the entire field of medicine. The question of what information the ‘drawers’ can and cannot take into account, is an important topic both for players within the healthcare system and those of us who are interested in information theory and its practical application. Let’s turn now to the coding process.
Two types of coding
I believe that the distinction described above is an important one. On the one hand, we have coding systems that aim to preserve the information itself and change only its form, such as Morse code and cryptographic systems. On the other hand, we have systems such as those for encoding medical diagnosis. These aim to reduce the total amount of information because this is simply too large and needs to be cut down – usually dramatically – for the sake of clarity. Coding to reduce information behaves very differently from coding to preserve information.
This distinction is critical. Mathematical models and scientific theories that apply to information-preserving systems are not suitable for information-reducing ones. In terms of information theory, we are faced with a completely different situation.