Two AI variants: rule-based and corpus-based
The two AI variants mentioned in previous blog posts are still topical today, and they have registered some remarkable successes. The two differ from each other not least in where precisely their intelligence is situated. Let’s first have a look at the rule-based system.
Structure of a rule-based system
In the Semfinder company, we used a rule-based system. I drew the following sketch of it in 1999:
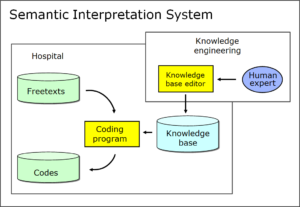
Green: data
Yellow: software
Light blue: knowledge ware
Dark blue: knowledge engineer
The sketch consists of two rectangles, which represent different locations. The rectangle bottom left shows what happens in the hospital; the rectangle top right additionally shows what goes on in knowledge engineering.
In the hospital, our coding program reads the doctors’ free texts, interprets them and converts them into concept molecules, and allocates the relevant codes to them with the help of a knowledge base. The knowledge base contains the rules with which the texts are interpreted. In our company, these rules were drawn up by people (human experts). The rules are comparable to the algorithms of a software program, apart from the fact that they are written in a “higher” programming language to ensure that non-IT specialists, i.e. the domain experts, who in our case are doctors, are able to establish them easily and maintain them safely. For this purpose, they use the knowledge base editor, which enables them to view the rules, to test them, to modify them or to establish completely new ones.
Where, then, is the intelligence situated?
It is situated in the knowledge base – but it is not actually a genuine intelligence. The knowledge base is incapable of thinking on its own; it only carries out what a human being has instilled into it. I have therefore never described our system as intelligent. At the very least, intelligence means that new things can be learnt, but the knowledge base learns nothing. If a new word crops up or if a new coding aspect is integrated, then this is not done by the knowledge base but by the knowledge engineer, i.e. a human being. All the rest (hardware, software, knowledge base) only carry out what they have been prescribed to do by human beings. The intelligence in our system was always and exclusively a matter of human beings – i.e. a natural rather than an artificial intelligence.
Is this different in the corpus-based method? In the following post, we will therefore have a closer look at a corpus-based system.
This is a post about artificial intelligence.
Translation: Tony Häfliger and Vivien Blandford