Compiling the corpus
In a previous post we saw how the corpus – the basis for the neural network of AI – is compiled. The neural network is capable of interpreting the corpus in a refined manner, but of course the neural network cannot extract anything from the corpus that is not in it in the first place.
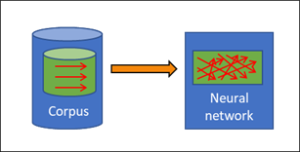
How is a corpus compiled? A domain expert assigns images of a certain class to a certain type, for instance “foreign tanks” vs “our tanks”. In Fig. 2, these categorisations carried out by the experts are the red arrows, which evaluate the tank images in this example.
Of course, the human expert’s assignations of the individual images according to the target categories must be correct – but that is not enough. There are fundamental limits to the evaluability of the corpus by a neural network, no matter how refined this may be.
Chance reigns if a corpus is too small
If I have only coloured images of our own tanks and only black and white ones of the foreign tanks (cf. introductory post about AI), the system can easily be led astray and identify all the coloured images as our own tanks and all the black and white ones as tanks of a foreign army. Although this defect can be remedied with a sufficiently large corpus, the example illustrates how important it is that a corpus consists of correct elements. If chance (coloured/black and white) is apt to play a crucial role in a corpus, the system will easily draw the wrong conclusions. Chance plays a greater role the smaller the corpus, but also the higher the number of possible “outcomes” (searched-for variables).
Besides these relative obstacles, there are also fundamental limits to the evaluability of an AI corpus. This is what we are going to look at next.
Tracked or wheeled tank?
Whatever is not in the corpus cannot be extracted from it. Needless to say, I cannot classify aircraft with a tank corpus.
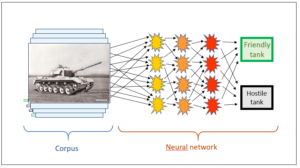
What, though, if our tank system is intended to find out whether a tank is tracked or wheeled? In principle, the corpus may well contain images of both types of tanks. How can the tank AI from our example recognise them?
The simple answer is: it can’t. In the corpus, the system has many images of tanks and knows whether each one is hostile or friendly. But is it wheeled or not? This information is not part of the corpus (yet) and can therefore not be extracted by the AI. Human beings may be capable of evaluating each individual image accordingly, as they did with the “friendly/hostile” properties, but then this would be an intelligence external to the AI that would make the distinction. The neural network is incapable of doing this on its own since it does not know anything about tracks and wheels. It has only learnt to distinguish our tanks from foreign ones. To establish a new category, the relevant information must first be fed into the corpus (new red arrows in Fig. 2), and then the neural network must be trained to answer new questions.
Such training need not necessarily be done on the tank corpus. The system would also be able to make use of the corpus of completely different vehicles whether these move on wheels or tracks. Although the distinction can automatically be transferred to the tank corpus, the external wheels/track system must first be trained – and again with categorisations made by human beings.
On its own, without predefined examples, the AI system will not be able to make this distinction.
Conclusions
- Only such conclusions can be drawn from a corpus as are part of that corpus.
- Categorisations (the red arrows in Fig. 2) invariably come from the outside, i.e. from human beings.
In our tank example, we have examined a typical image recognition AI. However, do the conclusions drawn from it (cf. above) also apply to other corpus-based systems? And isn’t there something like “deep learning”, i.e. the possibility that an AI system learns on its own?
Let us therefore have a look at a completely different type of corpus-based AI in the next blog post.
This is a post about artificial intelligence.
Translation: Tony Häfliger and Vivien Blandford