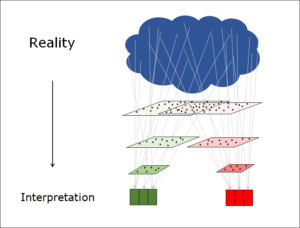
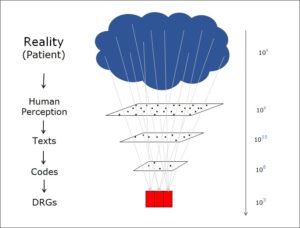
Two Levels define Entropy: Micro and Macro
Two levels Define Entropy
The conventional physical definition of entropy characterises it as a difference between two levels: a detail level and an overview level.
Example Coffee Cup
The thermal entropy according to Boltzmann is classic, using the example of an ideal gas. The temperature (1 value) is directly linked to the kinetic energies of the individual gas molecules (1023 values). With certain adjustments, this applies to any material object, e.g. also to a coffee cup:
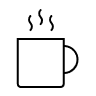
- Thermal macro state: temperature of the liquid in the cup.
- Thermal micro state: kinetic energy of all individual molecules in the cup
The values of a) and b) are directly connected. The heat energy of the liquid, which is expressed in the temperature of the coffee, is made up of the kinetic energies of the many (~ 1023) individual molecules in the liquid. The faster the molecules move, the hotter the coffee.
The movement of the individual molecules b) is not constant, however. Rather, the molecules are constantly colliding, changing their speed and therefore their energy. Nevertheless, the total energy after each collision is the same. Because of the energy theorem, the energy of the molecules involved changes with each collision, but the energy of all the molecules involved together remains the same. Even if the coffee cools down slowly or if the liquid is heated from the outside, the interdependence is maintained: The single overall value (temperature) and the many detailed values (movements) are always interdependent.
Example Forest and Trees
The well-known proverb warns us not to see the wood for the trees. This is an helpful picture for the tension between micro and macro level.
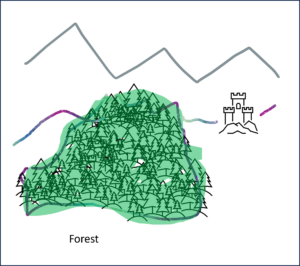
Forest: macro level
Trees: micro level
On the micro level we see the details, on the macro level we recognise the big picture. So which view is better? The forest or the trees?
- Both macro level and micro level are useful – depending on the task
- Both refer to the same object.
- Both cannot be discerned at the same time
-> When you look at the forest, you can’t see the individual trees
-> If you look at the trees, you miss the forest
We generally believe that it is better to know all the details. But this is a delusion. We always need an overview. Otherwise we would get lost in the details.
So Where is the Entropy?
We can now enumerate all the details of the micro view and thus obtain the information content – e.g. in bits – of the micro state. In the macro state, however, we have a much smaller amount of bits. The difference between the two amounts is the entropy, namely the information that is present in the micro state (trees) but missing in the macro state (forest).
Why isn’t the information content at the micro level the absolute entropy?
The information content at the micro level can be calculated in bits. Does this amount of bits correspond to entropy? If so, the information content at the macro level would simply be a loss of information. The actual information would then be in the micro level of details.
This is the spontaneous expectation that I repeatedly encounter with dialogue partners. They assume that there is an absolute information content, and in their eyes, this is naturally the one with the greatest amount of detail.
A problem with this conception is that the ‘deepest’ micro-level is not clearly defined. The trees are a lower level of information in relation to the forest – but this does not mean that the deepest level of detail has been reached. You can describe the trees in terms of their components – branches, twigs, leaves, roots, trunk, cells, etc. – which is undoubtedly a deeper level than just trees and would contain even more details. But even this level would not be deep enough. We still can go deeper into the details and describe the different cells of the tree, the organelles in the cells, the molecules in the organelles and so on. We would then arrive at the quantum level. But is that the deepest level? Perhaps, but that is not certain. And the further we go into the details, the further we move away from the description of the forest. What interests us is the description of the forest and the lowest level is not necessary for this. The deeper down we search, the further we move away from the description of our object.
→ The deepest micro level is not unequivocally defined!
We can therefore not assign a distinct absolute entropy for our object. Because the micro level can be set at any depth, the entropy, i.e. the quantitative information content at this level, also changes. the deeper, the more information, the higher the entropy.
Is There an Absolute Macro Level?
Like the micro level, the highest information level, e.g., of a forest, is not clearly defined as well.
Is this macro level the image that represents an optical view of the forest as seen by a bird flying over it? Or is it the representation of the forest on a map? At what scale? 1:25,000 or 1:100,000? Obviously the amount of information of the respective macro state changes depending on the view.
What are we interested in when we describe the forest? The paths through the forest? The tree species? Are there deer and rabbits? How healthy is the forest?
In other words, the forest, like any object, can be described in very different ways.
There is no clear, absolute macro level. A different macro representation applies depending on the situation and requirements.
The Relativity of Micro and Macro Levels
At each level, there is a quantitative amount of information, the deeper the richer, the higher the clearer. It would be a mistake, however, to label a specific level with its amount of information as the lowest or the highest. Both are arbitrary. They are not laid by the object, but by the observer.
The Difference is the Information
As soon as we accept that both micro and macro levels can be set arbitrarily, we approach a more real concept of information. It suddenly makes sense to speak of a difference. The difference between the two levels define the span of knowledge.
The information that I can gain is the information that I lack at the macro level, but which I find at the micro level. The difference between the two levels in terms of their entropy is the information that I can gain in this process.
Conversely, if I have the details of the micro level in front of me and want to gain an overview, I have to simplify this information of the micro level and reduce its number of bits. This reduction is the entropy, i.e. the information that I consciously relinquish.
The Information Paradox
If I want to extract the information that interests me from a jumble of details, i.e. if I want to get from a detailed description to useful information, then I have to ignore a lot of information at the micro level. I have to lose information in order to get the information I want. This paradox underlies every analytical process.
Information is Relative and Dynamic
What I am proposing is a relative concept of information. This does not correspond to the expectations of most people who have a static idea of the world. The world, however, is fundamentally dynamic. We live in this world – like all other living beings – as information-processing entities. The processing of information is an everyday process for all of us, for all biological entities, from plants to animals to humans.
The processing of information is an existential process for all living beings. This process always has a before and an after. Depending on this, we gain information when we analyse something in detail. And if we want to gain an overview or make a decision (!), then we have to simplify information. So we go from a macro-description to a micro-description and vice versa. Information is a dynamic quantity.
Entropy is the information that is missing at the macro level but can be found at the micro level.
And vice versa: entropy is the information that is present at the micro level but – to gain an overview – is ignored at the macro level.
Objects and their Micro and Macro Level
We can assume that a certain object can be described at different levels. According to current scientific findings, it is uncertain whether a deepest level of description can be found, but this is ultimately irrelevant to our information theory considerations. In the same way, it does not make sense to speak of a highest macro level. The macro levels depend on the task at hand.
What is relevant, however, is the distance, i.e. the information that can be gained in the macro state when deeper details are integrated into the view, or when they are discarded for the sake of a better overview. In both cases, there is a difference between two levels of description.
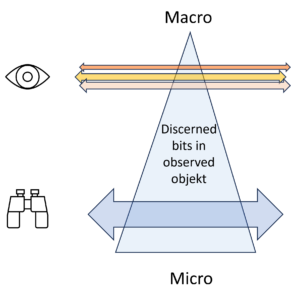
The illustration above visualises the number of detected bits in an object. At the top of the macro level, there are few, at the bottom of the micro level there are many. The object remains the same whether many or few details are taken into account and recognised.
The macro view brings a few bits, but their selection is not determined by the object alone, but rather by the interest behind the view of the observer.
The number of bits, i.e. the entropy, decreases from bottom to top. The heigth of the level, however, is not a property of the object of observation, but a property of the observation itself. Depending on my intention, I see it the observed object differently, sometimes detailed and unclear, another time clear and simplified, i.e. sometimes with a lot of entropy and another time with less entropy.
Information acquisition is the dynamic process that either:
a) gains more details: Macro → Micro
b) gains more overview: Micro → Macro
In both cases, the amount of information (entropy as the amount of bits) is changed. The bits gained or lost correspond to the difference in entropy between the micro and macro levels.
When I examine the object, it reveals more or less information depending on how I look at it. Information is always relative to prior knowledge and must be understood dynamically.
Translation: Juan Utzinger
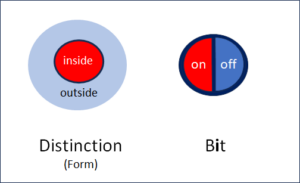
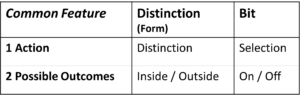
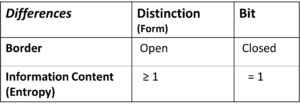

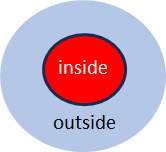
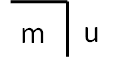 Fig. 3: Marked (m) and unmarked (u) space
Fig. 3: Marked (m) and unmarked (u) space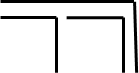

 A glass of water contains a huge amount of water molecules, all moving at different speeds and in different directions. These continuously collide with other water molecules, and their speed and direction of travel changes with each impact. In other words, the glass of water is a typical example of a real object that contains more information than an external observer can possibly deal with.
A glass of water contains a huge amount of water molecules, all moving at different speeds and in different directions. These continuously collide with other water molecules, and their speed and direction of travel changes with each impact. In other words, the glass of water is a typical example of a real object that contains more information than an external observer can possibly deal with.