What is real intelligence?
Paradoxically, the success of artificial intelligence helps us to identify essential conditions of real intelligence. If we accept that artificial intelligence has its limits and, in comparison with real intelligence, reveals clearly discernible flaws – which is precisely what we recognised and described in previous blog posts – then these descriptions do not only show what artificial intelligence lacks, but also where real intelligence is ahead of artificial intelligence. Thus we learn something crucial about natural intelligence.
What have we recognised? What are the essential differences? In my view, there are two properties which distinguish real intelligence from artificial intelligence. Real intelligence
– also works in open systems and
– is characterised by a conscious intention.
Chess and Go are closed systems
In the blog post on cards and chess, we examined the paradox that a game of cards appears to require less intelligence from us humans than chess, whereas it is precisely the other way round for artificial intelligence. In chess and Go, the computer beats us; at cards, however, we are definitely in with a chance.
Why is this the case? – The reason is the closed nature of chess, which means that nothing happens that is not provided for. All the rules are clearly defined. The number of fields and pieces, the starting positions and the way in which the pieces may move, who plays when and who has won at what time and for what reasons: all this is unequivocally set down. And all the rules are explicit; whatever is not defined does not play a part: what the king looks like, for instance. The only important thing is that there is a king and that, in order to win the game, his opponent has to checkmate him. In an emergency, a scrap of paper with a “K” on it is enough to symbolise the king.
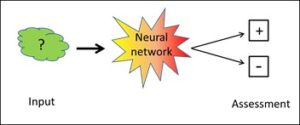
Such closed systems can be described with mathematical clarity, and they are deterministic. Of course, intelligence is required to win them, but this intelligence may be completely mechanical – that is, artificial intelligence.
Pattern recognition: open or closed system?
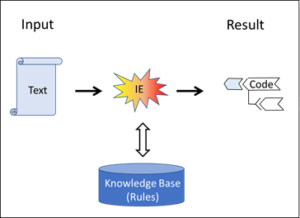
This looks different in the case of pattern recognition where, for example, certain objects and their properties have to be identified on images. Here, the system is basically open, for it is not only possible that images with completely new properties can be introduced from the outside. In addition, the decisive properties themselves that have to be recognised can vary. The matter is thus not as simple, clearly defined and closed as in chess and Go. Is it a closed system, then?
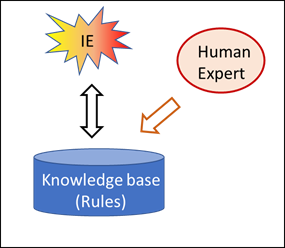
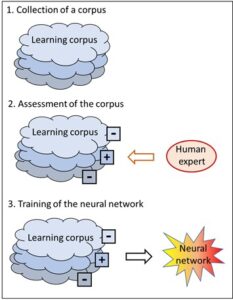
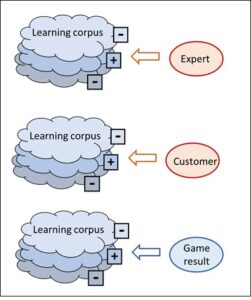
No, it isn’t. Whereas in chess, the rules place a conclusive boundary around the options and objectives, such a safety fence must be actively placed around pattern recognition. The purpose of this is to organise the diversity of the patterns in a clear order. This can only be done by human beings. They assess the learning corpus, which includes as many pattern examples as possible, and allocate each example to the appropriate category. This assessed learning corpus then assumes the role of the rules of chess and determines how new input will be interpreted. In other words: the assessed learning corpus contains the relevant knowledge, i.e. the rules according to which previously unknown input is interpreted. It corresponds to the rules of chess.
The AI system for pattern recognition is thus open as long as the learning corpus has not been integrated; with the assessed corpus, however, such a system becomes closed. In the same way that the chess program is set clear limits by the rules, expert assessment provides the clear-cut corset which ultimately defines the outcome in a deterministic way. As soon as the assessment has been made, a second and purely mechanical intelligence is capable of optimising the behaviour within the defined limits – and ultimately to a degree of perfection which I as a human being will never be able to achieve.
Who, though, specifies the content of the learning corpus which turns the pattern recognition program into a technically closed system? It is always human experts who assess the pattern inputs und who thus direct the future interpretation done by the AI system. In this way pattern recognition can be turned into a closed task like a game of chess or go which can be solved by a mechanical algorithm.
In both cases – in the initially closed game program (chess and Go) as well as in the subsequently closed pattern recognition program – the algorithm finds a closed situation, and this is the prerequisite for an artificial, i.e. mechanical intelligence to be able to work.
Conclusion 1:
AI algorithms can only work in closed spaces.
In the case of pattern recognition, the human-made learning corpus provides this closed space.
Conclusion 2:
Real intelligence also works in open situations.
Is there any intelligence without intention?
Why is artificial intelligence unable to work in an open space without assessments introduced from outside? Because it is only the assessments introduced from outside that make the results of intelligence possible. And assessments cannot be provided purely mechanically by the AI but are always linked to the assessors’ views and intentions.
Besides the differentiation between open and closed systems, our analysis of AI systems shows us still more about real intelligence, for artificial and natural intelligence also differ from each other with regard to the extent to which individual intentions play a part in their decision-making.
In chess programs, the objective is clear: to checkmate the opponent’s king. The objective which determines the assessment of the moves, namely the intention to win, does not have to be laboriously recognised by the program itself but is intrinsically given.
With pattern recognition, too, the role of the assessment intention is crucial, for what kind of patterns should be distinguished in the first place? Foreign tanks versus our own tanks? Wheeled tanks versus tracked tanks? Operational ones versus damaged ones? All these distinctions make sense, but the AI must be set, and adjusted to, a specific objective, a specific intention. Once the corpus has been assessed in a certain direction, it is impossible to suddenly derive a different property from it.
As in the chess program, the artificial intelligence is not capable of finding the objective on its own: in the chess program, the objective (checkmate) is self-evident; in pattern recognition, the assessors involved must agree on the objective (foreign/own tanks, wheeled/tracked tanks) in advance. In both cases, the objective and the intention come from the outside.
Conversely, natural intelligence has to determine itself what is important and what is unimportant, and what objectives it pursues. In my view, an active intention is an indispensable property of natural intelligence and cannot be created artificially.
Conclusion 3:
In contrast to artificial intelligence, natural intelligence is characterised by the fact that it is able to judge, and deliberately orient, its own intentions.
This is a blog post about artificial intelligence. You can find further posts through the overview page about AI.
Translation: Tony Häfliger and Vivien Blandford