All the systems we have examined so far, including deep learning, can in essence be traced back to two methods: the rule-based method and the corpus-based method. This also applies to the systems we have not discussed to date, namely simple automata and hybrid systems, which combine the two above approaches. If we integrate these variants, we will arrive at the following overview:
A: Rule-based systems
Rule-based systems are based on calculation rules. These rules are invariably IF-THEN commands, i.e. instructions which assign a certain result to a certain input. These systems are always deterministic, i.e. a certain input always leads to the same result. Also, they are always explicit, i.e. they involve no processes that cannot be made visible, and the system is always completely transparent – at least in principle. However, rule-based systems can become fairly complex.
A1: Simple automaton (pocket calculator type)
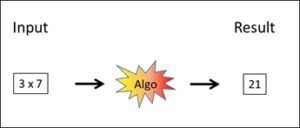
Fig. 1: Simple automaton
Rules are also called algorithms (“Algo”) in Fig. 1. Input and outputs (results) need not be figures. The simple automaton distinguishes itself from other systems in that it does not require any special knowledge base, but works with a few calculation rules. Nevertheless, simple automata can be used to make highly complex calculations, too.
Perhaps you would not describe a pocket calculator as an AI system, but the differences between a pocket calculator and the more highly developed systems right up to deep learning are merely gradual in nature – i.e. precisely of the kind that is being described on this page. Complex calculations soon strike us as intelligent, particularly if we are unable to reproduce them that easily with our own brains. This is already the case with simple arithmetic operations such as divisions or root extraction, where we quickly reach our limits. Conversely, we regard face recognition as comparatively simple because we are usually able to recognise faces quite well without a computer. Incidentally, nine men’s morris is also part of the A1 category: playing it requires a certain amount of intelligence, but it is complete in itself and easily controllable with an AI program of the A1 type.
A2: Knowledge-based system
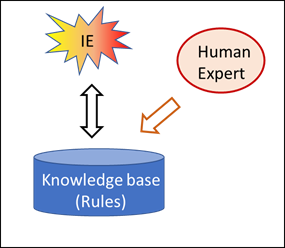
Fig. 2: Compiling a knowledge base (IE=Inference Engine)
These systems distinguish themselves from simple automata in that part of their rules have been outsourced to a knowledge base. Fig. 2 indicates that this knowledge base has been compiled by a human being, and Fig. 3 shows how it is applied. The intelligence is located in the rules; it originates from human beings – in the application, however, the knowledge base is capable of working on its own.
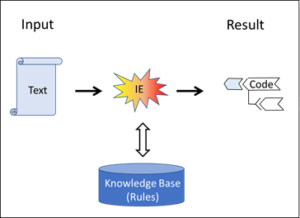
Fig. 3: Application of a knowledge-based system
The inference machine (“IE” in Figs. 2 and 3) corresponds to the algorithms of the simple automaton in Fig. 1. In principle, algorithms, the inference engine and the rules of the knowledge bases are always rules, i.e. explicit IF-THEN commands. However, these can be interwoven and nested in a variety of different ways. They can refer to figures or concepts. Everything is made by human experts.
The rules in the knowledge base are subordinate to the rules of the inference engine. The latter control the flow of the interpretation, i.e. they decide what rules of the knowledge base are to be applied and how they are to be implemented. The rules of the inference engine are the actual program that is read and executed by the computer. The rules of the knowledge base, however, are not directly executed by the computer, but indirectly through the instructions provided by the inference engine. This is nesting – which is typical of commands, i.e. software in computers; after all, the rules of the inference engine are not implemented directly but read by deeper rules right down to the machine language at the core (in the kernel) of a computer. In principle, however, the rules of the knowledge base are calculation rules just like the rules of the inference machine, but in a “higher” programming language. It is an advantage if the human domain experts, i.e. the human specialists, find this programming language particularly easy and safe to read and use.
With regard to the logic system used in inference machines, we distinguish between rule-based systems
– with a static logic (ontologies type / semantic web type),
– with a dynamic logic (concept molecules type).
For this, cf. the blog post on the three innovations of rule-based AI.
B: Corpus-based systems
Corpus-based systems are compiled in three steps (Fig. 4). In the first step, as large as possible a corpus is collected. The collection does not contain any rules, only data. Rules would be instructions; however, the data of the corpus are not instructions: they are pure data collections, texts, images, game processes, etc.
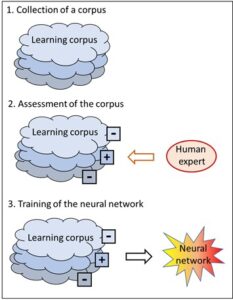
Fig. 4: Compiling a corpus-based system
These data must now be assessed. As a rule, this is done by a human being. In the third step, a so-called neural network is trained on the basis of the assessed corpus. In contrast to the data corpus, the neural network is again a collection of rules like the knowledge base of the rule-based systems A. Unlike those, however, the neural network is not constructed by a human being but built and trained by the assessed corpus. Unlike the knowledge base, the neural network is not explicit, i.e. it is not readily accessible.
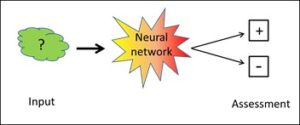
Fig. 5: Application of a corpus-based system
In their applications, both neural networks and the rule-based systems are fully capable of working without human beings. Even the corpus is no longer necessary. All the knowledge is located in the algorithms of the neural network. In addition, neural networks are also quite capable of interpreting poorly structured contents such as a mess of pixels (i.e. images), where rule-based systems (B type) very quickly reach their limits. In contrast to these, however, corpus-based systems are less successful with complex outputs, i.e. the number of possible output results must not be too large since if it is, the accuracy rate will suffer. What are best suited here are binary outputs of the “our tank – foreign tank” type (cf. preceding post) or of “male author – female author” in the assessment of Twitter texts. For such tasks, corpus-based systems are vastly superior to rule-based ones. This superiority quickly declines, however, when it comes to finely differentiated outputs.
Three subtypes of corpus-based AI
The three subtypes differ from each other with regard to who or what assesses the corpus.
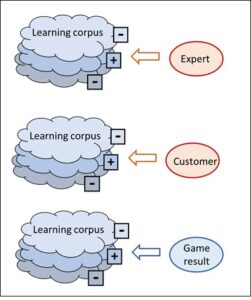
Fig. 6: The three types of corpus-based system and how they assess their corpus
B1: Pattern recognition type
I described this type (top in Fig. 6) in the tank example. The corpus is assessed by a human expert.
B2: Search engine type
Cf. middle diagram in Fig. 6: in this type, the corpus is assessed by the customers. I described such a system in the search engine post.
B3: Deep learning type
In contrast to the above types, this one (bottom in Fig. 6) does not require a human being to train or assess the neural network. The assessment results solely from the way in which the games proceed. The fact that deep learning is only possible in very restricted conditions is explained in the post on games and intelligence.
C: Hybrid systems
Of course the above-mentioned methods (A1-A2, B1-B3) can also be combined in practice.
Thus a face identification system, for instance, may work in such a way that in the images provided by a surveillance camera, a corpus-based system B1 is capable of recognising faces as such, and in the faces the crucial shapes of eyes, mouth, etc. Subsequently, a rule-based system A2 uses the points marked by B1 to calculate the proportions of eyes, nose, mouth, etc., which characterise an individual face. Such a combination of corpus- and rule-based systems allows for individual faces to be recognised in images. The first step would not be possible for an A2 system, the second step would be far too complicated and inaccurate for a B1 system. A hybrid system makes it possible.
In the following blog post, I will answer the question as to where the intelligence is located in all these systems. But you have probably long found the answer yourself.
This is a blog post about artificial intelligence.
Translation: Tony Häfliger and Vivien Blandford