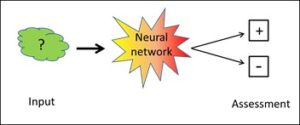
In a nutshell: the intelligence is always located outside.
a) Rule-based systems
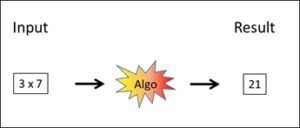
The rules and algorithms of these systems are created by human beings, and no one will ascribe real intelligence to a pocket calculator. The same also applies to all other rule-based systems, however refined they may be. The rules are devised by human beings.
b) Conventional corpus-based systems (neural networks)
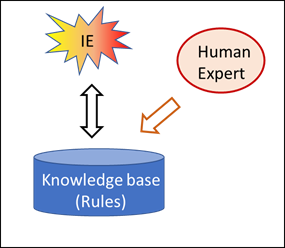
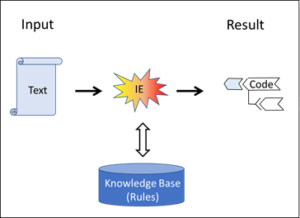
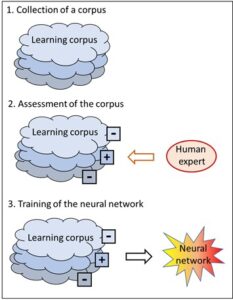
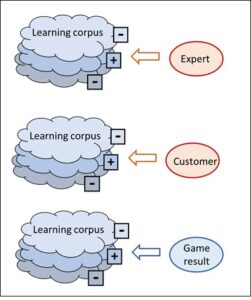
These systems always use an assessed corpus, i.e. a collection of data which have already been evaluated (details). This assessment decides according to what criteria each individual corpus entry is classified, and this classification then constitutes the real knowledge in the corpus.
However, the classification cannot be derived from the data of the corpus itself but is always introduced from the outside. And it is not only the allocation of a data entry to a class that can only be done from the outside; rather, the classes themselves are not determined by the data of the corpus, either, but are provided from the outside – ultimately by human beings.
The intelligence of these systems is always located in the assessment of the data pool, i.e. the allocation of the data objects to predefined classes, and this is done from the outside, by human beings. The neural network which is thus created does not know how the human brain has found the evaluations required for it.
c) Search engines
Search engines constitute a special type of corpus-based system and are based on the fact that many people use a certain search engine and decide with their clicks which internet links can be allocated to the search string. Ultimately, search engines only average the traces which the many users leave with their context knowledge and their intentions. Without the human brains of the users who have used the search engines so far, the search engines would not know where to point new queries.
d) Game programs (chess, Go, etc.) / deep learning
This is where things become interesting, for in contrast to the other corpus-based systems, such programs do not require any human beings who assess the corpus, which consists of the moves of games previously played from the outside. Does this mean, then, that such systems have an intelligence of their own?
Like the pattern recognition programs (b) and the search engines (c), the Go program has a corpus which in this case contains all the moves of the test games played before. The difference from the classic AI systems consists in the fact that the assessment of the corpus (i.e. the moves of the games) is already defined by the success in the actual game. Thus no human being is required who has to make a distinction between foreign tanks and our own tanks in order to provide the template for the neural network. The game’s success can be directly recognised by the machine, i.e. the algorithm itself; human beings are not required.
With classic AI systems, this is not the case, and a human being who assesses the individual corpus items is indispensable. Added to this, the assessment criterion is not given unequivocally, as it is with Go. Tank images can be categorised in completely different ways (wheeled/tracked tanks, damaged/undamaged tanks, tanks in towns/open country, in black and white/coloured pictures, etc.). This opens the interpretation options for the assessment at random. For all these reasons, an automatic categorisation is impossible with classic AI systems, which therefore always require an assessment of the learning corpus by human experts.
In the case of chess and Go, it is precisely this that is not required. Chess and Go are artificially designed and completely closed systems and thus indeed completely determined in advance. The board, the rules and the objective of the game – and thus also the assessment of the individual moves – are given automatically. Therefore no additional intelligence is required; instead, an automatism can play test games with itself within a predefined, closed setting and in this way attain the predefined objective better and better until it is better than any human being.
In the case of tasks which have to be solved not in an artificial game setting but in reality, however, the permitted moves and objectives are not completely defined, and there is leeway for strategy. An automatic system like deep learning cannot be applied in open, i.e. real situations.
It goes without saying that in practice, a considerable intelligence is required to program victory in Go and other games, and we may well admire the intelligence of the engineers at Google, etc., for that, yet once again it is their human intelligence which enables them to develop the programs, and not an intelligence which the programs designed by them are able to develop themselves.
Conclusion
AI systems can be very impressive and very useful, but they never have an intelligence of their own.