Go and chess
The Asian game of Go shares many similarities with chess while being simpler and more sophisticated at the same time.
The same as in chess:
– Board game → clearly defined playing field
– Two players (more would immediately increase complexity)
– Unequivocally defined possibilities of playing the stones (clear rules)
– The players place stones alternately (clear timeline).
– No hidden information (as, for instance, in cards)
– Clear objective (the player who has surrounded the larger territory wins)
Simpler in Go:
– Only one type of piece: the stone (unlike in chess: king, queen, etc.)
More complex/requires more effort:
– Go has a slightly larger playing field.
– The higher number of fields and stones require more computation.
– Despite its very simple rules, Go is a highly sophisticated game.
Summary
Compared with their common features, the differences between Go and chess are minimal. In particular, Go satisfies the strongly limiting preconditions a) to d), which enable an algorithm to tackle the job:
a) a clearly defined playing field,
b) clearly defined rules,
c) a clearly defined course of play,
d) a clear objective.(Cf. also preceding blog post)
Go and deep learning
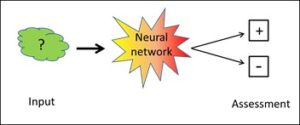
Google has beaten the best human Go players. This victory was achieved by means of a type of AI which is called deep learning. Many people think that this proves that a computer – i.e. a machine – can be genuinely intelligent. Let us therefore have a closer look at how Google managed to do this.
Rule- or corpus-based, or a new, third system?
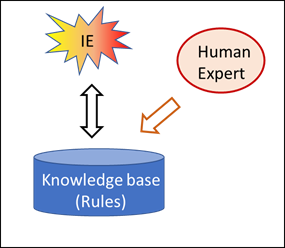
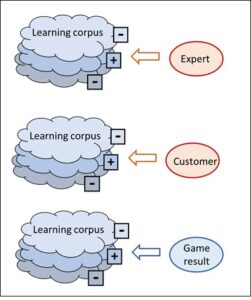
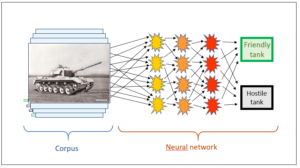
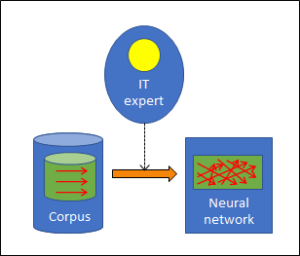
The strategies of the known AI programs are either rule-based or corpus-based. In previous posts, we asked ourselves where the intelligence in these two strategies comes from, and we realised that the intelligence in rule-based AI is injected into the system by the human experts who establish the rules. Corpus-based AI also requires human beings, since all the inputs into the corpus must be assessed (e.g. friendly/hostile tanks), and these assessments can always be traced back to people even if this is not immediately obvious.
However, what does this look like in the case of deep learning? Obviously, it does not require any human beings any longer in order to provide specific assessments – in Go, with regard to the individual moves’ chances of winning; rather, it is sufficient for the program to play against itself and find out on its own which moves have proved most successful. In this, deep learning does NOT depend on human intelligence and – in chess and Go – even turns out to be superior to human intelligence.
Deep learning is corpus-based
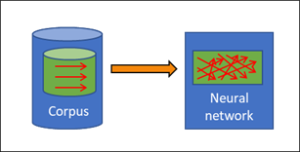
Google’s engineers undoubtedly did a fantastic job. Whereas in conventional corpus-based applications, the data for the corpus have to be compiled laboriously, this is quite simple in the case of the Go program: the engineers simply have the computer play against itself, and every game is an input into the corpus. No one has to take the trouble to trawl the internet or any other source for data; instead, the computer is able to generate a corpus of any size very simply and quickly. Although like the programs for pattern recognition, deep learning for Go continues to depend on a corpus, this corpus can be compiled in a much simpler way – and automatically at that.
Yet it gets even better for deep learning. Not only is the compilation of the corpus much simpler, but the assessment of the single moves in the corpus is also very easy: Finding out the best move from among all the moves that are possible at any given time no longer requires any human experts. How does this work? How is deep learning capable of drawing intelligent conclusions without any human intelligence at all? This may be astonishing, but if we look at it in more detail, it becomes clear why this is indeed the case.
The assessment of corpus inputs
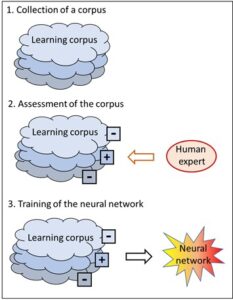
The difference is the assessment of the corpus inputs. To illustrate this, let’s have another look at the tank example. Its corpus consists of tank images, and a human expert has to assess each picture according to whether it shows one of our own tanks or a foreign tank. As explained, this requires human experts. In our second example, the search engine, it is also human beings, namely the users, who assess whether the link to a website suggested in the corpus fits the input search string. Both types of AI cannot do without human intelligence.
With deep learning, however, this is really different. The assessment of the corpus, i.e. the individual moves that make up the many different Go test games, does not require any additional intelligence. The assessment automatically results from the games themselves, since the only criterion is whether the game has been won or lost. This, however, is known to the corpus itself since it has registered the entire course of every game right to the end. Therefore the way in which every game has proceeded, automatically contains its own assessment – assessments by human beings are no longer required.
The natural limits of deep learning
The above, however, also reveals the conditions in which deep learning is possible at all: for the course of the game and the assessment to be clear-cut, there must not be any surprises. Ambiguous situations and uncontrollable outside influences are not allowed. For everything to be flawlessly calculable, the following is indispensable:
1. A closed system
This is given by the properties a) to c) (cf. preceding post), which games like chess and Go possess, namely
a) a clearly defined playing field,
b) clearly defined rules,
c) a clearly defined course of play.
A closed system is necessary for deep learning to work. Such a system can only be an artificially constructed system, for there are no closed systems in nature. It is no accident that chess and Go are particularly suitable for AI since games always have this aspect of being consciously designed. Games which integrate chance as part of the system, such as cards in the preceding post, are not absolutely closed systems any longer and therefore less suitable for artificial intelligence.
2. A clearly defined objective
A clearly defined objective – point d) in the preceding post – is also necessary for the assessment of the corpus to take place without any human interference, because the objective of the process under investigation and the assessment of the corpus inputs are closely connected. We must understand that the target of the corpus assessment is not given by the corpus data. Data and assessment are two different things. We have already discussed this in the example of the tanks, where we saw that a corpus input, i.e. the pixels of a tank photograph, did not automatically contain its own assessment (hostile/friendly). The assessment is a piece of information which is not intrinsic to the individual data (pixels) of an image; rather, it has to be fed into the corpus from the outside (by an interpreting intelligence). Therefore the same corpus input can also be assessed in very different ways: if the corpus is told whether an individual image is one of our own tanks or a foreign tank, it still does not know whether it is a tracked tank or a wheeled tank. With all such images, assessments can go in very different directions – unlike with chess and Go, where a move in a game (which is known to the corpus) is solely assessed according to the criterion of whether it is conducive to winning the game.
Thus chess and Go pursue a simple, clearly defined objective. In contrast to these two games, however, tank pictures allow for a wide variety of assessment objectives. This is typical of real situations. Real situations are always open, and in such situations, various and differing assessements can make sense and are absolutely appropriate. For the purpose of assessment, an instance (intelligence) outside the data has to establish the connection between the data and the assessment objective. This function is always linked to an instance with a certain intention.
Machine intelligence, however, lacks this intention and therefore depends on being provided with it by an objective from the outside. If the objective is as self-evident as it is in chess and Go, this is not a problem, and the assessment of the corpus can indeed be conducted by the machine itself without any human intelligence. In such unequivocal situations, machine deep learning is genuinely capable of working – indeed, even of beating human intelligence.
However, this only applies if the rules and the objective of a game are clearly defined. In all other cases, it is not an algorithm that is required but “real” intelligence, i.e. intelligence with a deliberate intention.
Conclusion
- Deep learning (DL) works.
- DL uses a corpus-based system.
- DL is capable of beating human intelligence in certain applications.
- However, DL only works in a closed system.
- DL only works if the objective is clear and unequivocal.
Ad 4) Closed systems are not real but are either obvious constructs (like games) or idealisations of real circumstances (= models). Such idealisations are invariably simplification with reduced information content. They are therefore incapable of mapping reality completely.
Ad 5) The objective, i.e. the “intention”, corresponds to a subjective momentum. This subjective momentum distinguishes natural from machine intelligence. The machine must be provided with it in advance.
This is a blog post about artificial intelligence.
Translation: Tony Häfliger and Vivien Blandford