AI can only see whatever is in the corpus
Corpus-based systems are on the road to success. They are “disruptive”, i.e. they change our society substantially within a very short period of time – reason enough for us to recall how these systems really work.
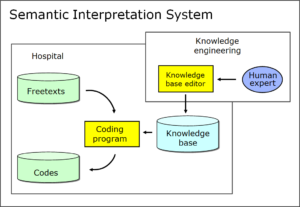
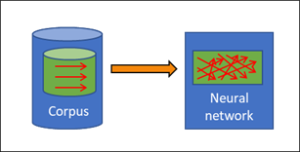
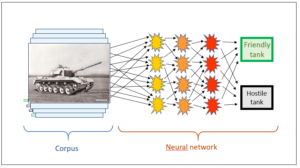
In previous blog posts I explained that these systems consist of two parts, namely a data corpus and a neural network. Of course, the network is unable to recognise anything that is not already in the corpus. The blindness of the corpus automatically continues in the neural network, and the AI is ultimately only able to produce what is already present in the data of the corpus. The same applies to incorrect input in the corpus: this will reappear in the results of the AI and, in particular, lessen their accuracy.
When we bring to mind the mode of action of AI, this fact is banal, since the learning corpus is the basis for this kind of artificial intelligence. Only that which is in the corpus can appear in the results, and errors and lack of precision in the corpus automatically diminish the validity of the results.
What is less banal is another aspect, which is also essentially tied up with the artificial intelligence of neural networks. It is the role played by probability. Neural networks work through probabilities. What precisely does this mean, and what effects does it have in practice?
Neural networks make assessments according to probability
Starting point
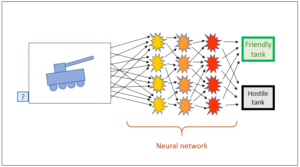
Let’s look again at our search engine from the preceding post. A customer of our search engine enters a search string. Other customers before him have already entered the same search string. We therefore suggest those websites to the customer which have been selected by the earlier customers. Of course we want to place those at the top of the customer’s list which are of most interest to him (cf. preceding post). To be able to do so, we assess all the customers according to their previous queries. How we do this in detail is naturally our trade secret; after all, we want to gain an edge over our competitors. No matter how we do this, however – and no matter how our competitors do it – we end up weighting previous users’ suggestions. On the basis of this weighting process, we select the proposals which we present to our enquirer and the order in which we display them. Here, probabilities are the crucial factor.
Example
Let us assume that enquirer A asks our search engine a question, and the two customers B and C have already asked the same question as A and left their choice, i.e. the addresses of the websites selected by them, in our well-stocked corpus. Which selection should we now prefer to present to A, that of B or that of C?
Now we have a look at the assessments of the three customers: to what extent do B’s and C’s profiles correspond with A’s profile? Let’s assume that we arrive at the following correspondences:
Customer B: 80%
Customer C: 30%
Naturally we assume that B corresponds better with A than C and that A is therefore served better by B’s answers.
But is this truly the case?
The question is justified, for after all, there is no complete correspondence with either of the two other users. It may be the case that it is precisely the 30% with which A and C correspond which concerns A’s current query. In that case, it would be unfortunate to give B’s answer priority, particularly if the 80% correspondence with B concerns completely different fields which have nothing to do with the current query. Admittedly, this deviation from probability is improbable in a specific case, but it is not impossible – and this is the actual crux of probabilities.
Now in this case, we reasonably opted for B, and we may be certain that probability is on our side. In terms of our business success, we may confidently rely on probability. Why?
This is connected with the law of large numbers. In an individual case as described above, C’s answer may indeed by the better one. In most cases, however, B’s answers will be more to our customer’s liking, and we are well advised to provide him with that answer. This is the law of large numbers. Essentially, it is the basis of the phenomenon of probability:
In an individual case, something improbable may happen; in many cases, however, we may rely on it that usually what is probable is what will happen.
Conclusion for our search engine
- If we are interested in being right in most cases, we stick to probability.
- At the same time, we accept that we may miss the target in rare cases.
Conclusion for corpus-based AI in general
What applies to our search engine generally applies to any corpus-based AI since all these systems work on the basis of probability. Thus the conclusion for corpus-based AI is as follows:
- If we are interested in being right in most cases, we stick to probability.
- At the same time, we accept that we may miss the target in rare cases.
We must acknowledge that corpus-based AI has an inherent weak point, a kind of Achilles’ heel of an otherwise highly potent technology. We should therefore continue to watch this heel carefully:
- Incidence:
When is the error most likely to occur, when can it be neglected? This is connected with the size and quality of the corpus, but also with the situation in which the AI is used. - Consequence:
What are the consequences if rare cases are neglected?
Can the permanent averaging and observing of solely the most probable solutions be called intelligent? - Interdependencies:
With regard to the fundamental interdependencies, the connection with the concept of entropy is of interest: the second law of thermodynamics states that in an isolated system, what happens is always what is more probable, and thermodynamics measures this probability with the variable S, which it defines as entropy.
What is probable is what happens, both in thermodynamics and in our search engine – but how does a natural intelligence choose?
The next blog post will be about games and intelligence, specifically about the difference between chess and a Swiss card games.
This is a post about artificial intelligence.
Translation: Tony Häfliger and Vivien Blandford