Der Trichter der Informationsreduktion
Im vorhergehenden Beitrag Informationsreduktion 1 habe ich eine Kette der Informationsverarbeitung vom Patienten bis zur Fallpauschale (DRG) beschrieben:
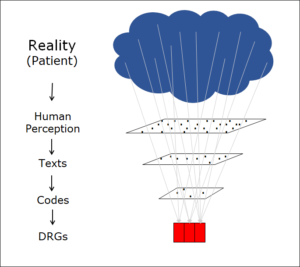
Bei dieser Kette handelt es sich um einen Trichter, der die verfügbare Informationsmenge bei jedem Schritt reduziert. Das Ausmass der Reduktion ist drastisch. Stellen Sie sich vor, sie haben den Patienten vor sich. Um ihn zu beschreiben, können Sie z.B. die roten Blutkörperchen zählen. Es gibt 24–30 Billionen (= 24–30·1012 ) davon, jedes hat eine bestimmte Form, einen Ort im Körper, eine Bewegung zu einem bestimmten Zeitpunkt und eine bestimmte Menge an rotem Blutfarbstoff im Innern. Das ist in der Tat eine Menge Information. Natürlich wollen sie diese Details gar nicht alle wissen. In der Regel genügt es zu wissen, ob sich im Blutkreislauf genug roter Blutfarbstoff (Hämoglobin) findet. Nur wenn das nicht der Fall ist (bei Anämie), wollen wir mehr wissen. So reduzieren wir die Information über den Patienten und wählen nur das Nötige aus. Das ist sehr vernünftig – obwohl wir dabei Information verlieren.
Der Trichter, quantifiziert
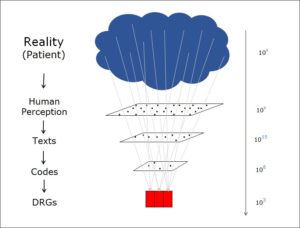
Um das Ausmass der Informationsreduktion zu quantifizieren, habe ich in der oben stehenden Abbildung rechts bei jeder Stufe der Informationsverarbeitung die Anzahl der möglichen Zustände aufgeführt. Von unten her sind dies:
- DRGs (Fallpauschalen): Es gibt unterschiedliche DRG-Systeme. Stets sind es aber ca. 1000 verschiedene Pauschalen, also 103 Zustände. Auf der Stufe Fallpauschale sind also 103 verschiedene Zustände möglich. Dies ist die Information, welche auf dieser Stufe erhältlich ist.
- Codes: Die ICD-10 Klassifikation bietet in der Schweiz ca. 20’000 verschiedene Codes an. Jeder Code entspricht einer Diagnose. Da ein Krankenhaus-Patient in der Regel mehr als eine Diagnose hat, nehme ich als Näherung zwei Diagnosen an. Die Information kann also zweimal zwischen 20’000 Zuständen auswählen, das ergibt 400’000’000 = 4 x 108.
- Texte: SNOMED, eine ausgedehnte medizinische Nomenklatur, enthält ca. 500’000 (5 x 105 )verschiedene Wörter. Da in einer Krankengeschichte viele Wörter vorkommen, ist die Informationsmenge hier natürlich sehr viel detailreicher. Meine Schätzung von 1015 ist hier gewiss untertrieben.
- Wahrnehmung (Perception) und Realität: Ich verzichte auf eine Schätzung. Das oben genannte Beispiel mit den roten Blutkörperchen zeigt, was für riesige Informationsmengen in der Realität vorliegen.
Dieser Text zur Informationsreduktion wird fortgesetzt mit einem Beitrag zur Selektion. Eine solche ist immer dann nötig, wenn die Menge an Detaildaten unübersichtlich wird – also eigentlich immer.
Zum Thema Informationsreduktion finden Sie hier die Übersichtsseite.