Go und Schach
Das asiatische Go-Spiel hat viele Ähnlichkeiten mit Schach und ist dabei gleichzeitig einfacher und raffinierter. Das heisst:
Gleich wie Schach:
– Brettspiel → klar definiertes Spielfeld
– Zwei Spieler (mehr würde die Komplexität sofort erhöhen)
– Eindeutig definierte Spielmöglichkeiten der Figuren (klare Regeln)
– Die Spieler ziehen abwechselnd (klare Zeitschiene)
– Keine versteckten Informationen (wie etwa beim Jassen)
– Klares Ziel (Wer am Schluss das grössere Gebiet besetzt, gewinnt)
Bei Go einfacher:
– Nur ein Typus Spielfigur/Steine (Bei Schach: König, Dame, etc.)
Bei Go komplexer/aufwendiger:
– Go hat das leicht grössere Spielfeld.
– Die grössere Anzahl Felder und Steine führt zu etwas mehr Rechenaufwand.
– Trotz sehr einfachen Grundelementen hat Go eine ausgesprochen raffinierte Spielanlage.
Zusammenfassung
Die Unterschiede zwischen Go und Schach sind verglichen mit den Gemeinsamkeiten minimal. Insbesondere sind auch für Go die stark einschränkenden Vorbedingungen a) bis d) erfüllt, die es einem Algorithmus erlauben, die Aufgabe in Angriff zu nehmen:
a) klar definiertes Spielfeld
b) klar definierte Spielregeln
c) klar definierter Spielablauf
d) klares Spielziel
(siehe auch Vorbeitrag)
Go und Deep Learning
Google hat die besten menschlichen Go-Spieler besiegt. Der Sieg wurde durch einen Typus KI erreicht, der als Deep Learning bezeichnet wird. Manche Leute denken, dass damit sei bewiesen, dass ein Computer – d.h. eine Maschine – wirklich intelligent sein könne. Schauen wir deshalb genauer, wie Google das angestellt hat.
Regel- oder korpusbasiert – oder ein neues, drittes System?
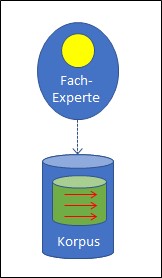
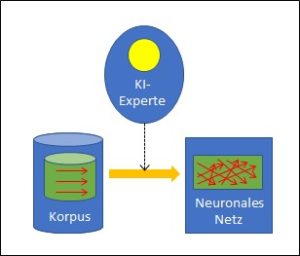
Die Strategien der bekannten KI-Programme sind entweder regel- oder korpusbasiert. In den Vorbeiträgen haben wir uns gefragt, wo die Intelligenz bei diesen beiden Strategien herkommt und wir haben gesehen, dass die Intelligenz bei der regelbasierten KI von menschlichen Experten in das System hinein gegeben wird, indem sie die Regeln bauen. Bei der korpusbasierten KI sind ebenfalls Menschen nötig, denn alle Einträge in den Korpus müssen eine Bewertung (z.B. eigener/fremder Panzer) bekommen, und diese Bewertung lässt sich immer auf Menschen zurückführen, auch wenn das nicht immer sofort ersichtlich ist.
Wie aber sieht das nun bei Deep Learning aus? Offensichtlich sind hier keine Menschen mehr nötig, um konkrete Bewertungen – bei Go bezüglich der Siegeschancen der Spielzüge – abzugeben, sondern es reicht, dass das Programm gegen sich selber spielt und dabei selbstständig herausfindet, welche Züge die erfolgreichsten waren. Dabei ist Deep Learning NICHT auf menschliche Intelligenz angewiesen und erweist sich – bei Schach und Go – sogar der menschlichen Intelligenz überlegen. Wie funktioniert das?
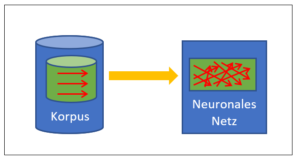
Deep Learning ist korpusbasiert
Zweifellos haben die Ingenieure von Google einen phantastischen Job gemacht. Während bei konventionellen korpusbasierten Anwendungen die Daten des Korpus mühsam zusammengesucht werden müssen, ist das beim Go-Programm ganz einfach: Die Ingenieure lassen den Computer einfach gegen sich selber spielen und jedes Spiel ist ein Eintrag im Korpus. Es müssen nicht mehr mühsam Daten im Internet oder anderswo gesucht werden, sondern der Computer kann den Korpus sehr einfach und schnell in beliebiger Grösse selber generieren. Das Deep Learning für Go bleibt zwar wie die Programme zu Mustererkennung weiterhin auf einen Korpus angewiesen, doch dieser lässt sich sehr viel einfacher – und vor allem automatisch – zusammenstellen.
Doch es kommt für das Deep Learning noch besser: Neben der einfacheren Erstellung des Korpus gibt es einen weiteren Vorteil: Es braucht überhaupt keine menschlichen Experten mehr, um unter den vielen zu einem bestimmten Zeitpunkt möglichen Spielzügen den besten herauszufinden. Wie funktioniert das? Wie kann Deep Learning ganz ohne menschliche Intelligenz intelligente Schlüsse ziehen? Das ist schon erstaunlich. Bei näherem Hinsehen wird aber klar, weshalb das in der Tat so ist.
Die Bewertung der Korpuseinträge
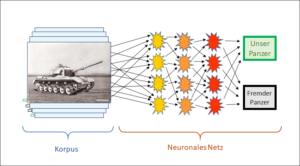
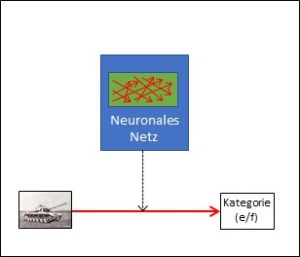
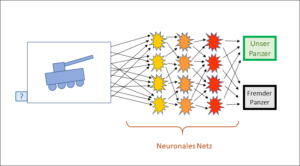
Der Unterschied liegt in der Bewertung der Korpuseinträge. Sehen wir dazu noch einmal unser Panzerbeispiel an. Sein Korpus besteht aus Bildern von Panzern, und ein menschlicher Experte muss jedes Bild danach beurteilen, ob es einen eigenen oder fremden Panzer darstellt. Dazu braucht es – wie dargestellt – menschliche Experten. Auch bei unserem zweiten Beispiel, der Suchmaschine, beurteilen menschliche Anwender, nämlich die Kunden, ob der im Korpus vorgeschlagene Link auf eine Website zum eingegebenen Suchausdruck passt. Beide Arten von KI kommen nicht ohne menschliche Intelligenz aus.
Bei Deep Learning ist das jedoch wirklich anders. Hier braucht es keine zusätzliche Intelligenz, um den Korpus, d.h. die einzelnen Züge der vielen Spielverläufe, die bei den Go-Testspielen entstehen, zu bewerten. Die Bewertung ergibt sich automatisch aus dem Spiel selber, denn es kommt nur darauf an, ob das Spiel gewonnen wird oder nicht. Das weiss der Korpus aber selber, da er ja den ganzen Spielverlauf bis zum Schluss hin registriert hat. Jeder Spielverlauf im Korpus hat somit seine Bewertung automatisch mit dabei – eine Bewertung durch Menschen erübrigt sich.
Natürliche Grenzen des Deep Learning
Durch das oben Gesagte lassen sich aber auch die Bedingungen erkennen, unter denen Deep Learning überhaupt möglich ist: Damit Spielverlauf und Bewertung klar sind, dürfen keine Überraschungen auftreten. Mehrdeutige Situationen und unkontrollierbare Einflüsse von aussen sind verboten. Damit alles fehlerfrei kalkulierbar bleibt, braucht es zwingend:
1. Ein geschlossenes System
Dies ist durch die Eigenschaften a) bis c) (siehe Vorbeitrag) gegeben, die Spiele wie Schach und Go aufweisen, nämlich:
a) klar definiertes Spielfeld,
b) klar definierte Spielregeln,
c) klar definierter Spielablauf.
Ein geschlossenes System ist nötig, damit Deep Learning funktionieren kann. Ein solches kann nur ein konstruiertes sein, denn in der Natur gibt es keine geschlossenen Systeme. Es ist kein Zufall, dass Schach und Go sich für die KI besonders eignen, da Spiele immer diesen Aspekt des bewusst Konstruierten haben. Schon Spiele, die den Zufall mit integrieren, wie das Jassen im Vorbeitrag, sind keine absolut geschlossenen Systeme mehr und deshalb für eine künstliche Intelligenz weniger geeignet.
2. Ein klar definiertes Ziel
Auch das klar definierte Ziel – Punkt d) im Vorbeitrag – ist nötig, damit die Bewertung des Korpus ohne menschlichen Eingriff stattfinden kann. Das Ziel des untersuchten Vorgangs und die Bewertung der Korpuseinträge hängen nämlich eng zusammen. Wir müssen verstehen, dass das Ziel der Auswertung des Korpus nicht durch die Daten des Korpus gegeben ist. Daten und Auswertung sind zwei verschiedene Dinge, und die Auswertung der Daten hängt vom Ziel ab. Wir haben diesen Aspekt bereits im Beispiel mit den Panzern diskutiert.
Dort sahen wir, dass ein Korpuseintrag, d.h. die Pixel eines Panzerbilds, nicht automatisch seine Bewertung (fremd/eigen) enthält. Die Bewertung ist eine Information, die nicht in den einzelnen Daten (Pixeln) des Bildes enthalten ist, vielmehr muss sie von aussen (durch eine interpretierende Intelligenz) in den Korpus hinein gegeben werden. Der gleiche Korpuseintrag kann deshalb sehr unterschiedlich bewertet werden: Wenn dem Korpus mitgeteilt wird, ob es sich beim jeweiligen Bild um einen eigenen oder einen fremden Panzer handelt, ist damit noch nicht bekannt, ob es ein Raupen- oder ein Radpanzer ist. Die Bewertung kann bei allen solchen Bildern in ganz unterschiedliche Richtungen gehen. Beim Schachspiel und bei Go hingegen ist das anders. Dort wird ein Zug im Spielverlauf (der im Korpus bekannt ist) allein danach bewertet, ob er dem Spielsieg dienlich ist.
Bei Schach und Go gibt es somit ein einfaches, klar definiertes Ziel. Bei Panzerbildern hingegen sind im Gegensatz zu Schach und Go ganz unterschiedliche Beurteilungsziele möglich. Das ist typisch für reale Situationen. Reale Situationen sind immer offen und in ihnen sind unterschiedliche Beurteilungen je nach Situation absolut normal und sinnvoll. Eine Instanz (Intelligenz) ausserhalb der Daten muss zwecks Beurteilung der Daten den Bezug zwischen den Daten und dem Beurteilungsziel herstellen. Diese Aufgabe ist immer an eine Instanz mit einer bestimmten Absicht gebunden.
Der maschinellen Intelligenz fehlt jedoch diese Absicht und sie ist deshalb darauf angewiesen, dass ihr das Ziel von aussen vorgegeben wird. Wenn das Ziel nun so selbstevident ist wie bei Schach und Go, ist das kein Problem und die Bewertung des Korpus kann in der Tat ohne menschliche Intelligenz von der Maschine selbstständig durchgeführt werden. In solchen eindeutigen Situationen kann maschinelles Deep Learning wirklich funktionieren und die menschliche Intelligenz sogar schlagen.
Das trifft aber nur zu, wenn die Spielregeln und das Spielziel klar definiert sind. In allen anderen Fällen braucht es keinen Algorithmus, sondern eine ‹echte›, d.h. eine absichtsvolle Intelligenz.
Fazit
- Deep Learning (DL) funktioniert.
- DL verwendet ein korpusbasiertes System.
- DL kann die menschliche Intelligenz bei gewissen Aufgaben schlagen.
- DL funktioniert aber nur in einem geschlossenen System.
- DL funktioniert nur dann, wenn das Ziel klar und eindeutig ist.
Ad 4) Geschlossene Systeme sind nicht real, sondern entweder offensichtliche Konstrukte (wie Spiele) oder Idealisierungen von realen Verhältnissen (= Modelle). Solche Idealisierungen sind immer Vereinfachungen im Sinn der Interpretationstheorie und beinhalten eine Informationsreduktion. Sie können deshalb die Realität nicht vollständig abbilden.
Ad 5) Das Ziel, d.h. die ‹Absicht› entspricht einem subjektiven Moment. Dieses subjektive Moment unterscheidet die natürliche von der maschinellen Intelligenz. Der Maschine muss es vorgegeben werden.
Wie wir gesehen haben, lohnt es sich, verschiedene Formen von KI zu unterscheiden und ihre Funktionsweise genauer anzusehen. So werden die Stärken und Schwächen dieser neuen Technologien, die auch die heutige Welt entscheidend mitbestimmen, klarer sichtbar.
Im nächsten Beitrag bringen wir basierend auf den bisherigen Erkenntnissen eine Zusammenstellung der verschiedenen KI-Systeme.
Dies ist ein Beitrag zum Thema Künstliche Intelligenz.