2 Arten von Kodierung
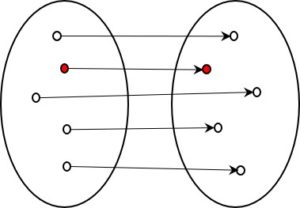
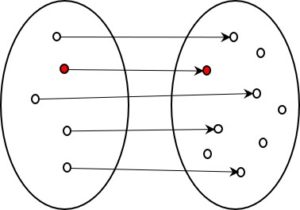
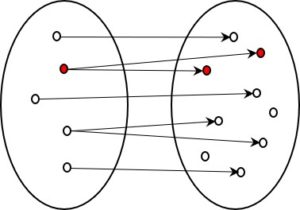
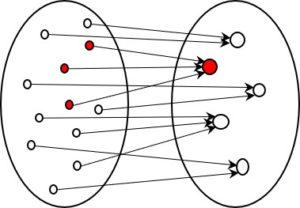
Im einem früheren Beitrag zur Kodierung habe ich zwei Arten von Kodierung beschrieben, die sich grundsätzlich unterscheiden. In der ersten Art wird versucht, die komplette Information der Quelle in die kodierte Form zu übertragen, in der zweiten Art wird bewusst darauf verzichtet. Es ist zweite, also die informationsverlierende Form, die uns besonders interessiert.
Als ich vor 20 Jahren in meinen Präsentationen auf diesen Unterschied hinwies und das Wort «Informationsverlust» prominent in meinen Folien auftauchte, wurde ich von meinen Projektpartnern darauf aufmerksam gemacht, dass das Wort bei den Zuhörern möglicherweise schlecht ankommt. Schliesslich wollen alle gewinnen, niemand will verlieren. Wie kann ich ein Produkt anpreisen, das den Verlust als Qualitätsmerkmal führt?
Nun, manchmal muss man über den Schatten springen und erkennen, dass gerade das, was man um jeden Preis zu vermeiden sucht, einen besonderen Wert hat. Und das ist bei der informationsverlierenden Kodierung mit Sicherheit der Fall.
Medizinische Kodierung
Unsere Firma spezialisierte sich auf die Kodierung von medizinischen Freitext-Diagnosen. Die Ärzte schreiben in die Krankengeschichten ihrer Patienten die Diagnose in Freitext und unser Programm las sie und ordnete ihnen automatisiert einen Kode zu. Dieser Kode (ICD-10) ist ein Standard mit nicht ganz 20’000 verschiedenen Kodes. Das klingt nach viel, die Zahl ist aber klein in Anbetracht der Milliarden von unterscheidbaren Diagnosen und Diagnoseformulierungen in der Medizin (siehe Beitrag). Der einzelne Kode kann natürlich nicht mehr Information enthalten als der Standard an dieser Stelle unterscheidet. In den Volltext-Diagnosen stand meist mehr und unsere Aufgabe war es, automatisiert die relevante Information aus den Freitexten zu ziehen, um den korrekten Kode zuzuweisen, was uns auch ganz gut gelang.
Die Kodierung ist Teil einer grösseren Kette
Doch die Kodierung ist nur ein Schritt. Einerseits geht die Kette der Informationsverarbeitung von den Kodes weiter zu den Fallpauschalen (DRGs), und andererseits sind die zu kodierenden Freitexte in den Krankengeschichte bereits Ergebnisse einer mehrstufigen Kette von früheren Informationsverarbeitungen und -reduktionen. Insgesamt liegt bei einem Krankenhausfall vom untersuchten Patienten bis zur Fallpauschale eine Kette mit folgenden Stufen vor:
- Patient: Menge der im Patienten enthaltenen Information.
- Arzt: Menge der Information über den Patienten, die der Arzt erkennt.
- Krankengeschichte: Menge der Information, die der Arzt dokumentiert.
- Diagnosen: Menge der Information, die in den Diagnosetexten steckt.
- Codes: Menge der Information, die in den Diagnosecodes steckt.
- Fallpauschale: Menge der Information die in der Fallpauschale steckt.
Bei jedem Schritt wird Information reduziert und die Informationsreduktion ist meistens drastisch. Es stellt sich die Frage, wie das funktioniert. Lässt die Reduktion automatisieren? Und wenn ja, wie?
Serie über Informationsreduktion
Mit diesem Beitrag starte ich eine Serie von Texten zum Thema Informationsreduktion, das in meinen Augen ein Schlüsselthema für das Verständnis von Information und unserem Umgang damit ist. Informationsreduktion ist so omnipräsent und alltäglich, dass wir sie leicht übersehen können.
Im nächsten Beitrag stelle ich dar, wie drastisch das Ausmass der Reduzierung sein kann.
Hier geht es zur Übersicht über die Beiträge zur Informationsreduktion.