Zwei KI-Varianten: regelbasiert und korpusbasiert
Im Vorbeitrag erwähnte ich die beiden prinzipiellen Herangehensweisen, mit der versucht wird, dem Computer Intelligenz beizubringen, nämlich die regelbasierte und die korpusbasierte. Bei der regelbasierten steckt die Intelligenz in einem Regelpool, der von Menschen bewusst konstruiert wird. Bei der korpusbasierten Methode steckt das Wissen im Korpus, d.h. in einer Datensammlung, welche von einem raffinierten Programm analysiert wird.
Beide Methoden haben ihre Leistungen seit den 90er Jahren gewaltig steigern können. Am eindrücklichsten ist dies bei der korpusbasierten Methode geschehen, die heute als eigentliche künstliche Intelligenz gilt und in der breiten Öffentlichkeit für Schlagzeilen sorgt. Worauf beruhen die entscheidenden Verbesserungen der beiden Methoden? – Ich werde gleich auf beide Methoden und ihre Verbesserungen eingehen. Als erstes sehen wir uns an, wie die korpusbasierte KI funktioniert.
Wie funktioniert die korpusbasierte KI?
Eine korpusbasierte KI besteht aus zwei Teilen:
- Korpus
- Algorithmen (neuronales Netz)
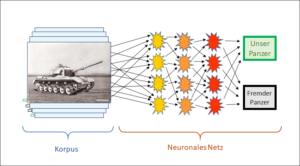
Der Korpus, auch Lernkorpus genannt, ist eine Sammlung von Daten. Dies können z.B. Photographien von Panzern oder Gesichtern sein, aber auch Sammlungen von Suchanfragen, z.B. von Google. Wichtig ist, dass der Korpus die Daten bereits bewertet enthält. Im Panzerbeispiel ist im Korpus vermerkt, ob es sich um eigene oder feindliche Panzer handelt. In der Gesichtersammlung ist vermerkt, um wessen Gesicht es sich jeweils handelt; bei den Suchanfragen speichert Google, welcher Link der Suchende anklickt, d.h. welcher Vorschlag von Google erfolgreich ist. Im Lernkorpus steckt also das Wissen, das die korpusbasierte KI verwenden wird.
Nun muss die KI lernen. Das Ziel ist, dass die KI ein neues Panzerbild, ein neues Gesicht oder eine neue Suchanfrage korrekt zuordnen kann. Dazu verwendet die KI das Wissen im Korpus, also z.B. die Bilder der Panzersammlung, wobei bei jedem Bild vermerkt ist, ob es sich um eigene oder fremde Panzer handelt – in Abb. 1 dargestellt durch die kleinen grauen und grünen Etiketten links von jedem Bild. Diese Bewertungen sind ein notwendiger Teil des Korpus.
Jetzt kommt der zweite Bestandteil der korpusbasierten KI ins Spiel, der Algorithmus. Im Wesentlichen handelt es sich um ein neuronales Netz. Es besteht aus mehreren Schichten von ‚Neuronen‘, die Inputsignale aufnehmen, gegeneinander verrechnen und dann ihre eigenen Signale an die nächsthöhere Schicht ausgeben. In Abb. 1 ist dargestellt, wie die erste (gelbe) Neuronenschicht die Signale (Pixel) aus dem Bild aufnimmt und nach einer Verrechnung dieser Signale eigene Signale an die nächste (orange) Schicht weitergibt, bis am Schluss das Netz zum Resultat ‚eigener‘ oder ‚fremder‘ Panzer gelangt. Die Verrechnungen (Algorithmen) der Neuronen werden beim Training so lange verändert und angepasst, bis das Gesamtnetz bei jedem Bild das korrekte Resultat liefert.
Wenn jetzt ein neues, noch unbewertetes Bild dem neuronalen Netz vorgelegt wird, verhält sich dieses genau gleich wie bei den anderen Bildern. Wenn das Netz gut trainiert worden ist, sollte der Panzer vom Programm selbstständig zugeordnet werden können, d.h. das neuronale Netz erkennt, ob das Bild einen eigenen oder fremden Panzer darstellt (Abb. 2).
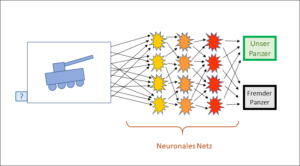
Abb. 2: Suchanfrage mit noch nicht klassifiziertem Panzer an das neuronale Netz
Die Bedeutung des Datenkorpus für die korpusbasierte KI
Die korpusbasierte KI findet ihr Detailwissen im eigens für sie bereitgestellten Korpus vor und wertet die Verbindungen aus, die sie dort antrifft. Der Korpus enthält somit das Wissen, welches die korpusbasierte KI auswertet. Das Wissen besteht in unserem Beispiel in der Verbindung der Photographie, also einer Menge von wild angeordneten Pixeln mit einer einfachen binären Information (unser Panzer/fremder Panzer). Dieses Wissen findet sich im Korpus bereits bevor eine Auswertung durch die Algorithmen stattfindet. Die Algorithmen der korpusbasierte KI finden also nichts heraus, was nicht im Korpus steckt. Allerdings: Das im Korpus gefundene Wissen kann die korpusbasierte KI nun auch auf neue und noch nicht bewertete Fälle anwenden.
Die Herausforderungen an die korpusbasierte KI
Die Herausforderungen an die korpusbasierte KI sind eindeutig:
- Grösse des Korpus: Je mehr Bilder sich im Korpus befinden, umso sicherer kann die Zuordnung erfolgen. Ein zu kleiner Korpus bringt Fehlresultate. Die Grösse des Korpus ist für die Präzision und Zuverlässigkeit der Resultate entscheidend.
- Hardware: Die Rechenleistung, welche die korpusbasierte KI benötigt, ist sehr gross; und sie wird umso grösser, je präziser die Methode sein soll. Die Performance der Hardware entscheidet über die praktische Anwendbarkeit der Methode.
Dadurch wird schnell klar, wie die korpusbasierte KI ihre Leistung in den letzten zwei Jahrzehnten so eindrücklich verbessern konnte:
- Die Datenmengen, welche Google und andere Organisationen im Internet sammeln können, sind drastisch angestiegen. Google profitiert dabei von einem nicht unbedeutenden Verstärkungseffekt: Je mehr Anfragen Google bekommt, umso besser wird der Korpus und damit seine Trefferquote. Je besser die Trefferquote, umso mehr Anfragen bekommt Google.
- Die Hardware, welche zur Auswertung der Daten benötigt wird, wird immer günstiger und performanter. Internetfirmen und andere Organisationen verfügen heute über riesige Serverfarmen, welche die rechenintensiven Auswertungen der korpusbasierten KI erst möglich machen.
Neben dem Korpus und der Hardware spielt natürlich auch die Raffinesse der Algorithmen eine Rolle. Die Algorithmen waren aber auch schon vor Jahrzehnten nicht schlecht. Im Vergleich zu den beiden anderen Faktoren – Hardware und Korpus – spielt der Fortschritt bei den Algorithmen für den beeindruckenden Erfolg der korpusbasierten KI nur eine bescheidene Rolle.
Der Erfolg der korpusbasierten KI
Die Herausforderungen an die korpusbasierte KI wurden von den grossen Firmen und Organisationen äusserst erfolgreich angegangen.
Auf Basis der oben erfolgten Beschreibung der Funktionsweise sollten aber auch die systemimmanenten und in den Medien etwas weniger prominent platzierten Schwächen der korpusbasierten KI erkennbar werden. In einem späteren Beitrag werde ich genauer darauf eingehen.
Dies ist ein Beitrag zum Thema künstliche Intelligenz. In der Fortsetzung sehen wir die Herausforderungen für die regelbasierte KI an.