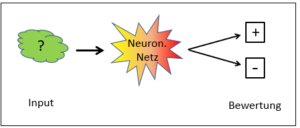
Was unter Künstlicher Intelligenz (KI) allgemein verstanden wird, sind sogenannte Neuronale Netze.
Neuronale Netze sind potent und für ihre Anwendungsgebiete unschlagbar. Sie erweitern die technischen Möglichkeiten unserer Zivilisation massgeblich auf vielen Gebieten. Trotzdem sind neuronale Netze nur eine Möglichkeit, ‹intelligente› Computerprogramme zu organisieren.
Korpus- oder regelbasiert?
Neuronale Netze sind korpusbasiert, d. h. ihre Technik basiert auf einer Datensammlung, dem Korpus, der von aussen in einer Lernphase Datum für Datum bewertet wird. Das Programm erkennt anschliessend in der Bewertung der Daten selbständig gewisse Muster, die auch für bisher unbekannte Fälle gelten. Der Prozess ist automatisch, aber auch intransparent.
In einem realen Einzelfall ist nicht klar, welche Gründe für die Schlussfolgerungen herangezogen worden sind. Wenn der Korpus aber genügend gross und korrekt bewertet ist, ist die Präzision der Schlüsse ausserordentlich hoch.
Grundsätzlich anders funktionieren regelbasierteSysteme. Sie brauchen keine Datensammlung, sondern eine Regelsammlung. Die Regeln werden von Menschen erstellt und sind transparent, d. h. leicht les- und veränderbar. Regelbasierte Systeme funktionieren allerdings nur mit einer adäquaten Logik (dynamische, nicht statische Logik) und einer für komplexe Semantiken geeigneten, multifokalen Begriffsarchitektur; beides wird in den entsprechenden Hochschulinstituten bisher kaum gelehrt.
Aus diesem Grund stehen regelbasierte Systeme heute eher im Hintergrund, und was allgemein unter künstlicher Intelligenz verstanden wird, sind neuronale Netze, also korpusbasierte Systeme.
Ist künstliche Intelligenz intelligent? Oder kann sie es werden?
Der bekannte Schriftsteller Daniel Kehlmann («Die Vermessung der Welt») hat letztes Jahr mit einem Sprachalgorithmus (CTRL) in Silicon Valley zusammen den Versuch unternommen, eine Kurzgeschichte zu schreiben. Fasziniert und gleichzeitig kritisch berichtet er über dieses aufschlussreiche Experiment.
CTRL
Das Programm CTRL ist ein typisches corpusbasiertesKI-System, d.h. ein System mit einer grossen Datensammlung – dem Corpus – und einem statistisch funktionierenden Auswertungsalgorithmus. Konkret haben die Betreiber den Corpus von CTRL mit Hunderttausenden von Büchern, Zeitungen und Online-Foren gefüttert, wodurch das System auf ein Gedächtnis aus Abermillionen von Sätzen zurückgreifen kann. Die Auswertung dieses Datenschatzes erfolgt aufgrund der Wahrscheinlichkeit: Wenn statistisch auf Wort A das Wort B das wahrscheinlichste ist, bringt das System nach Wort A auch das Wort B. Dank des immensen Corpus kann sich das System darauf verlassen, dass A nach B für uns durchaus eine wohlklingende Fortsetzung des Textes ist. Die schiere Wahrscheinlichkeit ist ist das Prinzip jeder korpusbasierten KI.
Natürlich ist anzunehmen, dass die Betreiber nicht nur die unmittelbaren Nachbarwörter berücksichtigen, sondern die Tiefenschärfe um das Ausgangswort weitreichender einstellen, also mehr Kontext berücksichtigen, doch stets gilt auch bei der Fortschreibung des gemeinsamen Textes durch Kehlmann und CTRL, dass der Algorithmus den bisher geschriebenen Text mit seinem grossen Corpus vergleicht und dann die Fortsetzung basierend auf der Wahrscheinlichkeit in seinem Korpus vorschlägt. Dadurch wird uns die Fortsetzung stets irgendwie vertraut und möglich vorkommen. – Wird sie aber auch sinnvoll sein? Wir kommen hier an die Grenzen jeder corpusbasierten Intelligenz: Das Wahrscheinlichste ist nicht immer das Beste.
Die Grenzen von CTRL
Daniel Kehlmann beschreibt die gemeinsame kreative Welt, die er zusammen mit dem Programm CTRL erkundet hat, gleichzeitig fasziniert und kritisch. Kritisch vermerkt er u.a. folgende Mängel:
a) Abstürze des Algorithmus Beim Experiment ist es nicht gelungen, eine Kurzgeschichte über eine bestimmte Länge weiterzuschreiben; offenbar war dann der Algorithmus rechnerisch nicht in der Lage, die Informationen der bisherigen Geschichte kohärent mit dem Corpus zusammenzubringen. Sobald die Geschichte über einige Sätze hinausging, stürzte das Programm regelmässig unrettbar ab – Ende der Gesichte.
Meines Erachtens ist das kein KO-Kriterium, denn Abstürze eines neuen Programms sind stets zu erwarten (ich weiss, wovon ich spreche … ). Zudem erwecken solche Abstürze stets den Eindruck, als könnten sie mit noch besserer Hardware und robusteren Algorithmen überwunden werden.
Doch dies ist m.E. hier nicht der Fall. Ich glaube vielmehr, dass diese Abstürze einen grundsätzlichen Schwachpunkt der corpusbasierten KI offenbaren, der auch mit verbesserter Hardware und besseren Auswertungsalgorithmen nicht angegangen werden kann. Der Mangel liegt vielmehr prinzipiell in der wahrscheinlichkeitsbasierten Anlage dieser corpusbasierten Programme. Je mehr Kontext (Tiefenschärfe) sie berücksichtigen müssen, umso grösser muss ihr Corpus werden. Doch der Bedarf an Daten und Rechenpower wächst, wenn es um die Vergrösserung des Kontexts geht, nicht linear, sondern exponentiell. Selbst wenn der riesige Corpus und die immense Rechenpower von CTRL weiter vergrössert werden würden, stösst ein solches Programm systembedingt immer und rasch an seine Grenzen.
Um Sinn und Bedeutung einzufangen, braucht es grundsätzlich andere Methoden, solche, die Bedeutung nicht indirekt aus statistischen Daten ausmitteln, sondern sie direkt repräsentieren und behandeln. Erst dann können die Programme direkt mit Bedeutung umgehen.
b) Zweitverwertung CTRL kennt nichts Neues, dafür Abermillionen alter Sätze. Dies birgt die Gefahr des «Garbage In, Garbage Out». Wenn Fehler oder Schwächen in den bisherigen Texten vorhanden sind, können sie auch in den Sätzen von CTRL auftauchen. Diese Gefahr ist zwar an sich klein, denn durch die grosse Menge an Sätzen wird es wahrscheinlicher, dass gleiche korrekte Sätze auftauchen als gleiche falsche, und somit wird CTRL sicher nur grammatikalisch, oder mindestens umgangssprachlich korrekte Sätze liefern. Doch trifft dies auch auf den Inhalt zu?
Wenn mehrere Menschen den gleichen Fehler machen, wird er dadurch zwar nicht korrekt, aber für eine corpusbasierte KI wird er so salonfähig. Rechtsextreme Messanger wird CTRL zwar kaum als bevorzugte Quelle benutzen, doch es geht nicht nur darum, gefährlichen Nonsens zu vermeiden. Vielmehr wollen wir spannende neue Geschichten. Wir wollen im CTRL-Projekt Kreativität und neue Ideen. Geht das mit einer Zweitverwertung?
c) Fehlende innere Logik Die gewünschte Kreativität kann zwar durch Zufall simuliert werden. Wenn zwei für uns unzusammenhängende Informationen in einen direkten Zusammenhang gesetzt werden, sind wir erst einmal überrascht. Wir horchen auf und hören die Geschichte weiter. Aber macht das Zusammengebrachte auch Sinn? Folgt es einer inneren Logik? – Wenn es rein zufällig ist, tut es das nicht, dann fehlt die innere Logik.
Zufall ist nicht Kreativität. Erst wenn ein logischer Zusammenhang zwischen den Zufällen gefunden wird, entsteht eine funktionierende Geschichte. Diese innere Logik fehlt einem corpusbasierten Programm prinzipiell.
Fazit
Daniel Kehlmann hat seine Erfahrungen präzis und gut nachvollziehbar beschrieben. Er erlebte das Experiment als faszinierend und war oft positiv von den Inputs von CTRL überrascht. Trotzdem stellt er fest, dass CTRL entscheidende Schwächen hat und verweist insbesondere auf den fehlenden narrativen Plan, welcher eine Geschichte zusammenhält.
Für jeden, der sich mit künstlicher Intelligenz vorurteilsfrei beschäftigt hat, ist die Erfahrung Kehlmanns eine lebhafte Bestätigung der eigenen Erfahrungen. Ich habe mich beruflich intensiv mit Computerlinguistik beschäftigt, d.h. mit der Frage, wie Computer natürliche Sätze intelligent interpretieren können. Dabei wird klar: Verständnis von Texten baut auf einem inneren Bezugssystem auf. Über dieses Bezugssystem verfügt jeder menschliche Schriftsteller – aber das KI-System nicht. Das korpusbasierte KI-System kennt nur die Wahrscheinlichkeiten von Signalen (Wörtern), ohne ihre wirkliche Bedeutung zu erfassen. Das ist das Problem.
Dem KI-System fehlt insbesondere Absicht und Bewusstsein. Die Absicht kann zwar durch die Betreiber von aussen vorgegeben werden – z.B. bestimmte Zellen in einem medizinischen Blutausstrich zu erkennen oder möglichst viel Traffic auf einer Suchmaschine zu erzielen – doch ein wirkliches Bewusstsein eines Programms würde ein Nachdenken über die eigene Absicht beinhalten. Eine corpusbasierte Intelligenz aber denkt überhaupt nicht nach – schon gar nicht über die eigene Absicht – sondern rechnet nur aus, was in seinem Datenpool das Wahrscheinlichste ist.
Das Experiment von Daniel Kehlmann ist deshalb lehrreich, weil es konkret, genau und verständlich Programmierern und Nicht-Programmierern die Grenzen der künstlichen Intelligenz aufzeigt.
Kurzfassung des Fazits
KI ist faszinierend und in vielen Anwendungen ausserordentlich nützlich, aber eines ist künstliche Intelligenz mit Sicherheit nicht: auf kreative Weise wirklich intelligent.
Ganz kurz: Die Intelligenz steckt immer ausserhalb.
a) Regelbasierte Systeme
Die Regeln und Algorithmen dieser Systeme – Typ A1 und A2 – werden von Menschen erstellt und niemand wird einem Taschenrechner wirkliche Intelligenz zubilligen. Das Gleiche gilt auch für alle anderen, noch so raffinierten regelbasierten Systeme. Die Regeln werden von Menschen gebaut.
b) Konventionelle korpusbasierte Systeme (Mustererkennung)
Diese Systeme (Typ B1) verwenden immer einen bewerteten Korpus, also eine Datensammlung, die bereits bewertet worden ist (Details). Die Bewertung entscheidet, nach welchen Zielen jeder einzelne Korpuseintrag klassifiziert wird und die Klassifizierung stellt dann das wirkliche Wissen im Korpus dar.
Die Klassierung ist aber nicht aus den Daten des Korpus selber ableitbar, sondern erfolgt immer von ausserhalb. Und nicht nur die Zuweisung eines Dateneintrags zu einer Klasse ist nur von aussen durchführbar, auch die Klassen selber sind nicht durch die Daten des Korpus determiniert, sondern werden von aussen – letztlich von Menschen – vorgegeben.
Die Intelligenz bei diesen Systemen steckt immer in der Bewertung des Datenpools, d.h. der Zuteilung der Datenobjekte zu vorgegebenen Klassen, und diese erfolgt von aussen durch Menschen. Das neuronale Netz, das dabei entsteht, weiss nicht, wie das menschliche Hirn die dafür nötigen Bewertungen gefunden hat.
c) Suchmaschinen
Diese (Typ B2) stellen einen Sonderfall der korpusbasierten Systeme dar und basieren auf der Tatsache, dass viele Menschen eine bestimmte Suchmaschinen benützen und mit ihren Klicks entscheiden, welche Internetlinks den Suchbegriffen zugeordnet werden können. Die Suchmaschinen mitteln am Ende nur, welche Spuren die vielen Benutzer mit ihrem eigenen Kontextwissen und ihren jeweiligen Absichten gelegt haben. Ohne die menschlichen Gehirne der bisherigen Suchmaschinenbenutzer wüssten die Suchmaschinen nicht, wohin sie zeigen sollten.
d) Spielprogramme (Schach, Go, usw.) / Deep Learning
Hier wird es interessant, denn diese Programme (Typ B3) brauchen im Gegensatz zu den anderen korpusbasierten Systemen keinen Menschen, der von aussen den Korpus (bestehend aus den Zügen bereits gespielter Partien) beurteilt. Verfügen diese Systeme also über eine eigenständige Intelligenz?
Wie die Programme zur Mustererkennung (b) und die Suchmaschinen (c) verfügt das Go-Programm über einen Korpus, der in diesem Fall die Züge der gespielten Testpartien enthält. Der Unterschied zu klassischen KI-Systemen besteht nun darin, dass die Bewertung des Korpus (d.h. der Spielzüge) bereits durch den Spielerfolg in der betreffenden Partie definiert ist. Es braucht also keinen Menschen, der fremde von eigenen Panzern unterscheiden muss und dadurch die Vorlage für das neuronale Netz liefert. Der Spielerfolg kann von der Maschine, d.h. dem Algorithmus, selber direkt erkannt werden, ein Mensch ist dafür nicht nötig.
Bei klassischen KI-Systemen ist dies nicht der Fall, und es braucht unbedingt einen Menschen, der die einzelnen Korpuseinträge bewertet. Dazu kommt, dass das Kriterium der Bewertung nicht wie bei Go eindeutig gegeben ist. Panzerbilder können z.B. ganz unterschiedlich kategorisiert werden (Radpanzer/Kettenpanzer, beschädigte/unbeschädigte Panzer, Panzer in Städten/Feldern, auf Farbbildern/Schwarzweiss-Bildern etc.). Dies öffnet die Interpretationsmöglichkeiten für die Bewertung beliebig. Eine automatische Zuweisung ist aus all diesen Gründen bei klassischen KI-System nicht möglich, und es braucht immer die Bewertung des Lernkorpus durch menschliche Experten.
Bei Schach und Go ist dies gerade nicht nötig. Denn Schach und Go sind künstlich konstruierte und völlig geschlosseneSysteme und deshalb in der Tat von vornherein vollständig determiniert. Das Spielfeld, die Spielregeln und das Spielziel – und damit auch die Bewertung der einzelnen Züge – sind automatisch gegeben. Deshalb braucht es keine zusätzliche Intelligenz, sondern ein Automatismus kann innerhalb des vorgegebenen, geschlossenen Settings Testpartien mit sich selber spielen und das vorgegebene Ziel so immer besser erreichen, bis er besser ist als jeder Mensch.
Bei Aufgaben, die sich nicht in einem künstlichen Spielraum, sondern in der Realität stellen, sind die erlaubten Züge und die Ziele aber nicht vollständig definiert und der Strategie-Raum bleibt offen. Eine Automatik wie Deep Learning ist in offenen, d.h. realen Situationen nicht anwendbar.
In der Praxis braucht es selbstverständlich eine beträchtliche Intelligenz, um den Sieg in Go und anderen Spielen zu programmieren und wir dürfen die Intelligenz der Ingenieuren von Google durchaus dafür bewundern, doch ist es eben wieder ihre menschliche Intelligenz, die sie die Programme entwickeln lässt, und nicht eine Intelligenz, die die von ihnen konstruierten Programme selbständig entwickeln könnten.
Fazit
KI-Systeme können sehr eindrücklich und sehr nützlich sein, sie verfügen aber nie über eigene Intelligenz.
Die einen versprechen sich den entscheidenden Technologiesprung, die anderen fürchten, dass eine gleichzeitig unfehlbare und fehlgeleitete künstliche Intelligenz die Menschheit unterjochen könnte.
Was ist daran wahr? – Ich arbeite seit einem Vierteljahrhundert mit «intelligenten» Informatiksystemen und wundere mich vor allem darüber, dass wir den neuronalen Netzen – zugegebenermassen sehr leistungsfähigen Systemen – überhaupt echte, d.h. eigenständige Intelligenz zubilligen.
Genau die haben sie nämlich nicht. Ihre Intelligenz kommt stets von Menschen, welche die Daten nicht nur liefern, sondern auch bewerten, bevor die KI sie verwenden kann. Ihre Leistungsfähigkeit zeigt die KI nur, wenn die Aufgabenstellung klar und einfach ist. Sobald die Fragestellung komplex wird, versagen sie. Oder sie flunkern, indem sie schöne Sätze, die sich in ihrem Datenschatz finden, so anordnen, dass es intelligent klingt (ChatGPT, LaMDA). Sie arbeiten nicht mit Logik, sondern mit Statistik, also mit Wahrscheinlichkeit. Aber ist das Wahr-Scheinliche auch immer das Wahre?
Wie funktioniert KI überhaupt? Wo sind ihre Grenzen? Wie unterscheiden sich die unterschiedlichen Arten der KI? Was steckt hinter Deep Learning? Ist künstliche Intelligenz wirklich intelligent? Und falls Sie das glauben, wo genau steckt die Intelligenz in der künstlichen Intelligenz – und wie kommt sie da hinein?
Diese Fragen werden ich im Folgenden zu beantworten versuchen. Unten sehen Sie meine Blogbeiträge zum Thema in systematischer Ordnung.
Die Beiträge sind im August 2021 auch als Buch erschienen. Sie können das Buch direkt beim Verlag bestellen:
Die Computerintelligenz verfügt über zwei grundlegend verschiedene Methoden: Sie kann entweder auf Regeln oder auf einer Datensammlung (=Korpus) beruhen. Im Einstiegsbeitrag stelle ich sie mit zwei charakteristischen Anekdoten vor:
Die regelbasierten Systeme hatten es schwieriger. Was sind ihre Herausforderungen? Wie können sie ihre Schwächen überwinden? Und wo steckt bei ihnen die Intelligenz?
Zurück zu den korpusbasierten Systemen. Wie sind sie aufgebaut? Wie wird ihr Korpus zusammengestellt und bewertet? Was hat es mit dem neuronalen Netz auf sich? Und was sind die natürlichen Grenzen der korpusbasierten Systeme?
Als nächstes beschäftigen wir uns mit Suchmaschinen, die ebenfalls korpusbasierte Systeme sind. Wie gelangen sie zu ihren Vorschlägen? Wo sind ihre Grenzen und Gefahren? Weshalb entstehen z.B. zwingend Blasen?
Kann ein Programm lernen, ohne dass ein Mensch ihm gute Ratschläge zuflüstert? Mit Deep Learning scheint das zu klappen. Um zu verstehen, was dabei passiert, vergleichen wir zuerst ein einfaches Kartenspiel mit Schach: Was braucht mehr Intelligenz? Überraschend wird klar, dass für den Computer Schach das einfachere Spiel ist.
An den Rahmenbedingungen von Go und Schach erkennen wir, unter welchen Voraussetzungen Deep Learning funktioniert.
Im anschliessenden Beitrag gebe ich einen systematischen Überblick über die mir bekannten KI-Arten, skizziere kurz ihren jeweiligen Aufbau und die Unterschiede in ihrer Funktionsweise.
Alle bis jetzt untersuchten Systeme, inkl. Deep Learning, lassen sich in ihrem Kern auf zwei Methoden zurückführen, die regel- und die korpusbasierte. Dies gilt auch für die bisher nicht besprochenen Systeme, nämlich den einfachen Automaten und die hybriden Systeme. Letztere kombinieren die beiden Herangehensweisen.
Wenn wir diese Varianten integrieren, gelangen wir zur folgenden Übersicht:
A: Regelbasierte Systeme
Regelbasierte Systeme basieren auf Rechenregeln. Bei diesen Regeln handelt es sich immer um ‹IF-THEN› Befehle, also um Anweisungen, die einem bestimmten Input ein bestimmtes Ergebnis zuweisen. Diese Systeme sind immer deterministisch, d.h. ein bestimmter Input führt immer zum gleichen Resultat. Ebenfalls sind diese Systeme immer explizit, d.h. es gibt keine Vorgänge, die nicht sichtbar gemacht werden können und das System ist – mindestens im Prinzip – immer vollständig durchschaubar. Regelbasierte Systeme können allerdings recht komplex werden.
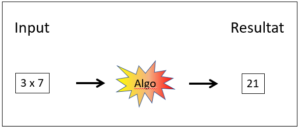
A1: Einfacher Automat (Typ Taschenrechner)
Abb. 1: Einfacher Automat
Regeln werden auch als Algorithmen («Algo» in Abb. 1) bezeichnet. Selbstverständlich können mit einfachen Automaten auch sehr komplexe Berechnungen durchgeführt werden und Input und Output (Resultat) müssen nicht Zahlen sein. Der einfache Automat zeichnet sich vor den anderen Systemen dadurch aus, dass er keine spezielle Wissensbasis und keinen Korpus braucht, sondern mit wenigen Rechenregeln auskommt.
Vielleicht würden Sie den Taschenrechner nicht als KI-System bezeichnen, doch die Unterschiede zu den höher entwickelten Systemen bis hin zum Deep Learning sind nur gradueller Natur – bzw. von genau der Art, wie sie hier auf dieser Seite beschrieben werden. Komplexe Rechenleistungen erscheinen uns schnell einmal als intelligent, besonders dann, wenn wir sie mit unseren menschlichen Gehirnen nicht so einfach nachvollziehen können. Das gilt bereits für einfache Rechenoperationen wie Divisionen und Wurzelziehen, bei denen wir schnell an unsere Grenzen stossen. Gesichtserkennung erscheint uns hingegen vergleichsweise einfach, weil wir das meist auch ohne Computer ganz gut können. Übrigens gehört Mühlespielen auch in die Kategorie A1, es braucht zwar eine gewisse Intelligenz, um es zu spielen, aber es ist vollständig und einfach mit einem KI-Programm vom Typ A1 beherrschbar.
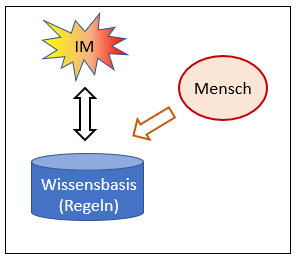
A2: Wissensbasiertes System
Abb. 2: Erstellen einer Wissensbasis
Diese Systeme unterscheiden sich von einfachen Automaten dadurch, dass ein Teil ihrer Regeln in einer Wissensbasis ausgelagert ist. Abb. 2 weist darauf hin, dass diese Wissensbasis von einem Menschen aufgebaut wird; Abb. 3 zeigt, wie sie angewendet wird. Die Intelligenz steckt in den Regeln, sie kommt vom Menschen – bei der Anwendung reicht dann die Wissensbasis allein.
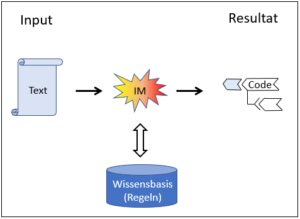
Abb. 3: Anwenden eines wissensbasierten Systems
Die Inferenzmaschine («IM» in Abb. 2 und 3) entspricht den Algorithmen der einfachen Automaten in Abb. 1. Im Prinzip handelt es sich bei den Algorithmen, der Inferenzmaschine und den Regeln der Wissensbasen immer um Regeln, also um explizite ‹IF-THEN›- Anweisungen. Diese können allerdings unterschiedlich komplex verwoben und verschachtelt sein. Sie können sich auf Zahlen oder auf Begriffe beziehen.
Die Regeln in der Wissensbasis sind nun den Regeln der Inferenzmaschine untergeordnet. Letztere kontrollieren den Fluss der Interpretation, d.h. sie entscheiden, welche Regeln der Wissensbasis anzuwenden und wie sie auszuführen sind. Die Regeln der Inferenzmaschine sind das eigentliche Programm, das vom Computer gelesen und ausgeführt wird. Die Regeln der Wissensbasis hingegen werden vom Computer nicht direkt, sondern indirekt über die Anweisungen der Inferenzmaschine ausgeführt. Es handelt sich also um eine Verschachtelung – wie sie im Übrigen typisch für die Befehle (Software) in einem Computer sind. Auch die Regeln der Inferenzmaschine werden ja nicht direkt ausgeführt, sondern von tieferen Regeln gelesen, bis hinunter zur Maschinensprache im Kern (Kernel) des Rechners. Im Prinzip sind aber die Regeln der Wissensbasis genauso Rechenregeln wie die Regeln der Inferenzmaschine, nur eben in einer ‹höheren› Programmiersprache. Diese zeichnet sich vorteilhafterweise dadurch aus, dass sie für die Domain-Experten, d.h. für die menschlichen Fachexperten, besonders einfach und sicher les- und handhabbar ist.
Bezüglich des in der Inferenzmaschine verwendeten Logiksystems unterscheiden wir regelbasierte Systeme
– mit statischer Logik (Typ Ontologien / Semantic Web),
– mit dynamischer Logik (Typ Begriffsmoleküle).
Siehe dazu den Beitrag ‹Die drei Neuerung der regelbasierte KI›.
B: Korpusbasierte Systeme
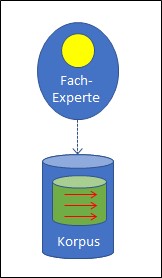
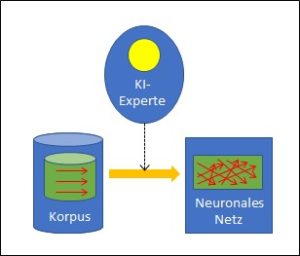
Korpusbasierte Systeme werden in drei Schritten erstellt (Abb. 4). Im ersten Schritt wird ein möglichst grosser Korpus gesammelt. Die Sammlung enthält keine Regeln, sondern Daten. Regeln wären Anweisungen, die Daten des Korpus hingegen sind keine Anweisungen; es handelt sich um reine Datensammlungen, Texte, Bilder, Spielverläufe, etc.
Abb. 4: Erstellen eines korpusbasierten Systems
Diese Daten müssen nun – im zweiten Schritt – bewertet werden. In der Regel macht das ein Mensch.
Im dritten Schritt wird ein sogenanntes neuronales Netz auf Basis des bewerteten Korpus trainiert. Das neuronale Netz ist im Gegensatz zum Datenkorpus wieder eine Regelsammlung, wie es die Wissensbasis der regelbasierten Systeme (Typ A) ist. Im Unterschied zu diesen wird das neuronale Netz aber nicht von einem Menschen trainiert, sondern vom bewerteten Korpus. Das neuronale Netz ist – im Gegensatz zur Wissensbasis – nicht explizit, d.h. nicht so ohne Weiteres einsehbar.
Abb. 5: Anwenden eines korpusbasierten Systems
Bei der Anwendung kommt das neuronale Netz wie das regelbasierte nun ganz ohne Menschen aus. Es braucht nicht einmal mehr den Korpus. Alles Wissen steckt in den Algorithmen des neuronalen Netzes. Zudem ist das neuronale Netz durchaus in der Lage, auch schlecht strukturierten Inhalt, z.B. Pixelhaufen (Bilder) zu interpretieren, bei denen regelbasierte Systeme (Typ B) ganz schnell an ihre Grenzen stossen. Im Gegensatz zu diesen sind die korpusbasierten Systeme aber weniger erfolgreich, was komplexen Output betrifft, d.h. die Zahl der möglichen Output-Resultate darf nicht zu gross sein, da sonst die Trefferschärfe des Systems leidet. Am besten geeignet sind binäre Outputs vom Typ ‹eigener/fremder Panzer› (siehe Vorbeitrag) oder ‹männlicher/weiblicher Autor› bei der Bewertung von Twitter-Texten.
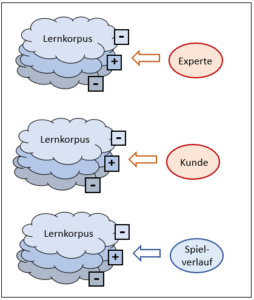
Drei Untertypen der korpusbasierten KI
Die drei Untertypen unterscheiden sich dadurch, wer die Bewertung des Korpus durchführt.
Abb. 6: Die drei Typen der korpusbasierten Systeme
B1: Typ Mustererkennung
Diesen Typ (oberes System in Abb. 6) habe ich im «Panzerbeispiel» beschrieben. Die Bewertung des Korpus erfolgt dabei durch einen menschlichen Experten.
B2: Typ Suchmaschine
Siehe mittleres Schema in Abb. 6. Bei diesem Typ erfolgt die Bewertung des Korpus durch die Kunden. Ein solches System ist im Beitrag Suchmaschine beschrieben.
B3: Typ Deep Learning
Bei diesem Typ (unterstes System in Abb. 6) ist im Gegensatz zu den oberen kein Mensch nötig, um das neuronale Netz zu bewerten. Die Bewertung ergibt sich allein durch den Spielverlauf. Dass Deep Learning aber nur unter sehr restriktiven Bedingungen möglich ist, wird im Beitrag Spiele und Intelligenz erläutert.
C: Hybride Systeme
Selbstverständlich können die oben genannten Methoden (A1 und A2, B1 bis B3) in der Praxis auch verbunden werden.
So kann z.B. ein System zur Gesichtsidentifikation so funktionieren, dass ein korpusbasiertes System des Typs B1 in den Bildern einer Überwachungskamera Gesichter als solche erkennt und in den Gesichtern die entscheidenden Formen von Augen, Mund usw. Anschliessend errechnet ein regelbasiertes System des Typs A2 aus den von System B1 markierten Punkten die Grössenverhältnisse von Augen, Nasen, Mund etc., die ein individuelles Gesicht auszeichnen. Durch eine solche Kombination von korpus- und regelbasiertem System können auf den Bildern individuelle Gesichter erkannt werden. Der erste Schritt wäre für ein System A2 nicht möglich, der zweite Schritt für ein System B1 viel zu kompliziert und ungenau. Ein Hybrid macht es möglich.
Im Folgebeitrag beantworte ich die Frage, wo in all diesen Systemen nun die Intelligenz steckt. Aber vermutlich haben Sie die Antwort längst selbst erkannt.
Was nicht im Korpus ist, ist für die KI unsichtbar
Korpusbasierte KI-Systeme sind auf Erfolgskurs. Sie sind ‹disruptiv›, d.h. sie verändern unsere Gesellschaft nachhaltig und in sehr kurzer Zeit. Genügend Gründe also, sich zu vergegenwärtigen, wie diese Systeme effektiv funktionieren.
In den Vorbeiträgen habe ich dargelegt, dass diese Systeme aus zwei Teilen bestehen, nämlich einem Daten-Korpus und einem neuronalen Netz. Selbstverständlich kann das Netz nichts erkennen, was nicht bereits im Korpus steckt. Die Blindheit des Korpus setzt sich automatisch im neuronalen Netz fort und die KI kann letztlich nur hervorbringen, was bereits in den Daten des Korpus vorgegeben ist. Ebenso verhält es sich mit Fehleingaben im Korpus. Auch diese finden sich in den Resultaten der KI und mindern insbesondere ihre Treffschärfe.
Wenn man sich die Wirkweise der KI vergegenwärtigt, ist dieser Sachverhalt banal, denn der Lernkorpus ist die Grundlage für diese Art künstliche Intelligenz. Nur was im Korpus ist, kann im Resultat erscheinen und Fehler und Unschärfen des Korpus vermindern automatisch die Aussagekraft.
Weniger banal ist ein anderer Aspekt, der mit der künstlichen Intelligenz der neuronalen Netze ebenfalls essenziell verbunden ist. Es handelt sich um die Rolle der Wahrscheinlichkeit. Neuronale Netze funktionieren über Wahrscheinlichkeiten. Was genau heisst das und wie wirkt sich das in der Praxis aus?
Das neuronale Netz bewertet nach Wahrscheinlichkeit
Ausgangslage
Schauen wir wieder unsere Suchmaschine vom Vorbeitrag an: Ein Kunde unserer Suchmaschine gibt einen Suchstring ein. Andere Kunden haben bereits vorher den gleichen Suchstring eingegeben. Wir schlagen deshalb dem Kunden diejenigen Websites vor, die bereits die früheren Kunden ausgewählt haben. Weil das unübersichtlich viele sein können, wollen wir dem Kunden diejenigen zuoberst zeigen, die für ihn am interessantesten sind (siehe Vorbeitrag). Dazu bewerten wir alle Kunden gemäss ihren bisherigen Suchanfragen. Wie wir das im Detail machen, ist natürlich unser Geschäftsgeheimnis, schliesslich wollen wir gegenüber der Konkurrenz einen Vorsprung herausholen. Wie immer aber wir das auch tun – und wie immer es die Konkurrenz auch tut – am Schluss erhalten wir eine Gewichtung der Vorschläge der bisherigen Nutzer. Anhand dieser Gewichtung wählen wir die Vorschläge aus, die wir dem Fragesteller präsentieren, und die Reihenfolge, in der wir sie ihm zeigen. Und dabei sind die Wahrscheinlichkeiten entscheidend.
Beispiel
Nehmen wir an, der Anfragesteller A stellt eine Suchanfrage an unsere Suchmaschine und die beiden Kunden B und C haben bereits die gleiche Suchanfrage wie A gestellt und ihre Wahl, d.h. die Adressen der von ihnen gewählten Websites, in unserem gut gefüllten Korpus hinterlassen. Welche Auswahl sollen wir nun A bevorzugt präsentieren, die von B oder die von C?
Jetzt schauen wir uns die Bewertungen der drei Kunden an: Wie sehr stimmt das Profil von B und C mit dem Kunden A überein? Nehmen wir an, wir kommen auf folgende Übereinstimmungen:
Kunde B: 80%
Kunde C: 30%
Selbstverständlich nehmen wir an, dass Kunde B mit A besser übereinstimmt als C, und A deshalb mit den Antworten von B besser bedient ist.
Ist das aber sicher so?
Die Frage ist berechtigt, denn schliesslich besteht zu keinem der beiden anderen User eine vollständige Übereinstimmung. Vielleicht betreffen gerade die 30%, mit denen A und C übereinstimmen, das Gebiet der aktuellen Suchanfrage von A. Da wäre es schade, die Antwort von B bevorzugt zu platzieren, insbesondere wenn die 80% Übereinstimmung zu B ganz andere Gebiete betrifft, die mit der aktuellen Suchanfrage nichts zu tun haben. Zugegeben, die skizzierte Abweichung von der Wahrscheinlichkeit ist im konkreten Fall unwahrscheinlich, aber sie ist nicht unmöglich – das ist die eigentliche Crux mit den Wahrscheinlichkeiten.
Nun, wir entscheiden uns in diesem Fall vernünftigerweise für B, und wir können sicher sein, dass die Wahrscheinlichkeit auf unserer Seite ist. Für unseren Geschäftserfolg können wir uns getrost auf die Wahrscheinlichkeit verlassen. Warum?
Das hängt mit dem Prinzip der ‹grossen Zahl‹ zusammen. Für den einzelnen Fall kann – wie oben geschildert – die Antwort von C wirklich die bessere sein. In den meisten Fällen aber wird die Antwort von B unserem Kunden besser gefallen und wir tun gut daran, ihm diese Antwort zu geben. Das ist das Prinzip der ‹grossen Zahl›. Es liegt dem Phänomen Wahrscheinlichkeit essenziell zugrunde:
Im Einzelfallkann etwas geschehen, was unwahrscheinlich ist, für viele Fällekönnen wir uns aber darauf verlassen, dass meistens das Wahrscheinliche geschieht.
Fazit für unsere Suchmaschine
Wenn wir uns also dafür interessieren, in den meisten Fällen recht zu bekommen, halten wir uns an die Wahrscheinlichkeit.
Wir nehmen dabei in Kauf, dass wir in seltenen Fällen daneben greifen.
Fazit für die korpusbasierte KI generell
Was für unsere Suchmaschine gilt, gilt ganz generell für jede korpusbasierte KI, da eine solche immer mit Wahrscheinlichkeiten funktioniert. Somit lautet das Fazit für die korpusbasierte KI:
Wenn wir uns dafür interessieren, in den meisten Fällen recht zu bekommen, halten wir uns an die Wahrscheinlichkeit.
Wir nehmen dabei in Kauf, dass wir in seltenen Fällen daneben greifen.
Wir müssen bei der korpusbasierten KI mit einer inhärenten Schwäche rechnen, einer Art Achillesferse einer sonst hochpotenten Technologie. Diese Ferse sollten wir sorgfältig weiter beobachten:
Vorkommen:
Wann tritt der Fehler eher auf, wann kann man ihn eher vernachlässigen? Dies hängt mit der Grösse des Korpus und seiner Qualität, aber auch mit der Art der Fragestellung zusammen.
Konsequenzen:
Was hat es für Folgen, wenn seltene Fälle vernachlässigt werden?
Kann das permanente Mitteln und Beachten nur der wahrscheinlichsten Lösungen als intelligent bezeichnet werden?
Zusammenhänge: Für die grundlegenden Zusammenhänge interessant ist der Bezug zum Begriff der Entropie: Der 2. Hauptsatz der Wärmelehre besagt, dass in einem geschlossenen System immer das Wahrscheinlichere geschieht und die Wärmelehre misst diese Wahrscheinlichkeit anhand der Variablen S, welche sie als Entropie bezeichnet.
Das Wahrscheinliche geschieht, in der Wärmelehre und in unserer Suchmaschine – wie aber wählt eine natürliche Intelligenz?
Nehmen wir an, Sie bauen eine Suchmaschine. Sie wollen dabei möglichst keine teuren und nicht immer fehlerfreien menschlichen Fachexperten (domain experts) einsetzen, sondern die Suchmaschine nur mit ausreichend Datenservern (der Hardware für den Korpus) und einer ausgeklügelten Software bauen. Wieder verwenden Sie im Prinzip ein neuronales Netz mit einem Korpus. Wie bringen Sie nun die Intelligenz in Ihr System?
Trick 1: Lass die Kunden den Korpus trainieren
Bei einer Suchmaschine geht es wie bei der Panzer-KI der Vorbeiträge um Zuordnungen, diesmal von einem Eingabetext (Suchstring) eines Kunden zu einer Liste von Webadressen, die für seine Suche interessant sein könnten. Um die relevanten Adressen zu finden, basiert Ihr System wiederum auf einem Lernkorpus, der diesmal aus der Liste aller Sucheingaben von allen Ihren bisherigen Kunden besteht. Die Webadressen, die die früheren Kunden aus den ihnen angebotenen auch tatsächlich angeklickt haben, sind im Korpus als positive Hits vermerkt. Also geben Sie bei neuen Anfragen – auch von anderen Kunden – einfach die Adressen an, die bisher am meisten Klicks erhalten haben. So schlecht können die ja nicht sein, und mit jeder Anfrage und dem darauf folgenden Klick verfeinert sich das System. Und dann gilt: Je grösser der Korpus, umso präziser.
Wieder stammen diese Zuordnungen von aussen, nämlich von den Menschen, die die Auswahl, die Ihre Suchmaschine ihnen angeboten hat, mit ihren Klicks entsprechend bewertet haben. Die Menschen haben das getan:
mit ihrer menschlichen Intelligenz und
entsprechend ihren jeweiligen Interessen.
Besonders der zweite Punkt ist interessant. Wir könnten später noch etwas detaillierter darauf eingehen.
Trick 2: Bewerte die Kunden dabei mit
Nicht jede Zuordnung von jedem Kunden ist gleich relevant. Als Suchmaschinenbetreiber können Sie hier an zwei Punkten optimieren:
Bewerten Sie die Bewerter:
Sie kennen ja alle Eingaben Ihrer Kunden. So können Sie leicht herausfinden, wie verlässlich die von ihnen gemachten Zuordnungen (die angeklickte Webadressen zu den eingegebenen Suchstrings) sind. Nicht alle Ihre Kunden sind in dieser Hinsicht gleich gut. Je mehr andere Kunden für den gleichen Suchstring die gleiche Webadresse anwählen, umso sicherer wird die Zuordnung auch für zukünftige Anfragen sein. Verwenden Sie nun diese Information, um die Kunden zu gewichten: Der Kunde, der bisher die verlässlichsten Zuordnungen hatte, d.h. derjenige, der am meisten das wählte, was die anderen auch wählten, wird am höchsten gewichtet. Einer, dem die anderen weniger folgten, gilt als etwas weniger verlässlich. Durch die Gewichtung erhöhen Sie die Wahrscheinlichkeit, dass die zukünftigen Suchergebnisse die Websites höher bewerten, die die meisten Kunden interessieren.
Bewerten Sie die Sucher:
Nicht jeder Suchmaschinenbenutzer hat die gleichen Interessen. Das können Sie berücksichtigen, denn Sie kennen ja bereits alle früheren Eingaben von ihm. Diese können Sie verwenden, um ein Profil von ihm zu erstellen. Das dient natürlich dazu, die Suchergebnisse für ihn entsprechend auszuwählen. Bewerter mit einem ähnlichen Profil wie der Sucher werden die potenziellen Adressen auch ähnlich gewichten, und sie können so die Suchergebnisse noch mehr im Interesse des Kunden personalisieren.
Es lohnt sich für Sie als Suchmaschinenbetreiber auf jeden Fall, von allen Ihren Kunden ein Profil zu erstellen, nur schon zur Verbesserung der Qualität der Suchvorschläge.
Konsequenzen
Suchmaschinen werden durch den Gebrauch immer präziser.
Das gilt für alle korpusbasierten Systeme, also für alle Technologien mit neuronalen Netzen: Je grösser ihr Korpus ist, desto besser ist ihre Präzision. Sie können zu erstaunlichen Leistungen fähig sein.
In diesem Zusammenhang lässt sich ein bemerkenswerter Rückkopplungseffekt feststellen: Je grösser ihr Korpus ist, umso besser ist die Qualität einer Suchmaschine und deshalb wird sie häufiger benützt, was wiederum ihren Korpus vergrössert und so ihre Attraktivität gegenüber der Konkurrenz steigert. Dieser Effekt führt unweigerlich zu den Monopolen, wie sie typisch sind für alle Anwendungen von korpusbasierter Software.
Alle Bewertungen sind primär von Menschen erstellt worden. Die Basis der Intelligenz – die zuordnenden Eingaben im Korpus – erfolgen weiterhin durch Menschen. Bei den Suchmaschinen ist das jeder einzelne Benutzer, der so sein Wissen in den Korpus eingibt. So künstlich ist die Intelligenz in dieser KI also gar nicht.
Korpusbasierte Systeme tragen die Tendenz zur Blasenbildung in sich: Wenn Suchmaschinen von ihren Kunden Profile anlegen, können sie diese mit besseren Suchergebnissen bedienen. Das führt aber in einem selbstreferenziellen Prozess unweigerlich zu einer Blasenbildung: Anwender mit ähnlichen Ansichten werden von den Suchmaschinen immer näher zusammen gebracht, da sie auf diese Weise die Suchergebnisse erhalten, die ihren jeweiligen Interessen und Ansichten am besten entsprechen. Abweichende Ansichten bekommen sie immer weniger zu Gesicht.
Dies ist ein Beitrag zum Thema künstliche Intelligenz. Im nächsten Beitrag geht es um einen weiteren wichtigen Aspekt der korpusbasierten Systeme, nämlich um die Rolle der Wahrscheinlichkeit.
In einem Vorbeitrag haben wir gesehen, wie der Korpus – die Basis für das neuronale Netz der KI – erstellt wird. Das neuronale Netz kann den Korpus auf raffinierte Weise interpretieren, aber selbstverständlich kann das neuronale Netz nichts aus dem Korpus herausziehen, was nicht drin steckt.
Abb. 1: Das neuronale Netz holt das Wissen aus seinem Korpus
Wie wird der Korpus erstellt? Ein Fachexperte ordnet Bilder einer bestimmten Klasse, einem bestimmten Typus zu, z.B. ‹fremde Panzer› versus ‹eigene Panzer›. Diese Zuordnungen des Experten sind in Abb. 2 die roten Pfeile, welche z.B. die Panzerbilder bewerten.
Abb. 2: Erstellung der Zuordnungen im Korpus
Selbstverständlich müssen die durch den menschlichen Experten erfolgten Zuordnungen der einzelnen Bilder zu den Zielkategorien korrekt sein. Doch das reicht nicht. Es bestehen prinzipielle Grenzen für die Auswertbarkeit eines Korpus durch ein noch so raffiniertes neuronales Netz.
Der Zufall regiert im zu kleinen Korpus
Wenn ich nur farbige Bilder der eigenen und schwarzweisse Bilder der fremden Panzer habe (siehe Einstiegsbeitrag zur KI), dann kann sich das System leicht irren und alle farbigen der eigenen und die schwarzweissen der fremden Armee zuordnen. Mit einem genügend grossen Korpus kann dieser Mangel zwar behoben werden, doch zeigt das Beispiel, wie wichtig die richtige Bestückung des Korpus ist. Wenn ein Zufall (farbig/schwarzweiss) entscheidend in den Korpus hineinspielt, wird das System falsche Schlüsse ziehen. Der Zufall spielt dabei eine umso grössere Rolle, je kleiner der Korpus, aber auch je grösser die Anzahl der möglichen ‹Outcomes› (= Anzahl der prinzipiell möglichen Resultate) ist.
Neben diesen relativen Hindernissen gibt es aber auch prinzipielle Grenzen der Auswertbarkeit eines KI-Korpus. Darauf gehen wir jetzt ein.
Raupen- oder Radpanzer?
Was im Korpus nicht drin ist, kann auch nicht herausgeholt werden. Selbstverständlich kann ich mit einem Panzer-Korpus keine Flugzeuge klassifizieren.
Abb 3: Die Bewertung entscheidet – Korpus mit eigenen und fremden Panzern und entsprechend programmiertem Netz.
Was aber ist, wenn unser Panzersystem herausfinden soll, ob es sich um Raupen- oder um Radpanzer handelt? Im Prinzip können im Korpus ja Bilder von beiden Sorten von Panzern enthalten sein. Wie kann die Panzer-KI aus unserem Beispiel das erkennen?
Die einfache Antwort ist: gar nicht. Im Korpus hat das System zwar viele Bilder von Panzern und weiss bei jedem, ob es ein fremder oder eigener ist. Aber ist es ein Radpanzer oder nicht? Diese Information steckt im Korpus (noch) nicht drin und kann deshalb von der KI nicht herausgezogen werden. Zwar kann ein Mensch jedes einzelne Bild entsprechend beurteilen, so wie er das mit der Eigenschaft ‹fremd/eigen› gemacht hat. Aber dann ist es eine KI-fremde, von aussen zugeführte Intelligenz, die das tut. Das neuronale Netz kann das nicht selber leisten, da es nichts über Raupen oder Räder weiss. Es hat nur gelernt, eigene von fremden Panzern zu unterscheiden. Für jede neue Kategorie muss zuerst die Information in den Korpus gegeben (neue rote Pfeile in Abb. 2) und dann das neuronale Netz für die neuen Fragen geschult werden.
Eine solche Schulung muss zwar nicht zwingend am Panzer-Korpus erfolgen. Das System könnte auch anhand eines Korpus von ganz anderen Fahrzeugen lernen, ob sich diese sich auf Rädern oder Raupen bewegen. Auch wenn sich der Unterschied automatisch auf den Panzerkorpus übertragen lässt, muss doch das externe Räder/Raupen-System vorgängig trainiert werden – und zwar mit Zuordnungen, die wieder ein Mensch gemacht hat.
Selber, ohne vorgegebene Beispiele, findet das KI-System dies nicht heraus.
Fazit
Aus einem Korpus können nur Schlüsse gezogen werden, die im Korpus angelegt sind.
Die Kategorie-Zuordnungen (die roten Pfeile in Abb. 2) kommen immer von aussen, d.h. von einem Menschen.
In unserem Beispiel haben wir mit dem Panzerbeispiel eine typische Bilderkennungs-KI untersucht. Aber gelten die daraus gezogenen Schlüsse (siehe Fazit oben) auch für andere korpusbasierte Systeme? Und gibt es nicht so etwas wie ‹Deep Learning›, also die Möglichkeit, dass ein KI-System ganz von selber lernt?
Schauen wir deshalb im nächsten Beitrag einen ganz anderen Typ mit korpusbasierter KI an.
Im Vorbeitrag haben wir gesehen, dass bei der regelbasierten KI die Intelligenz in den Regeln steckt. Diese Regeln sind menschengemacht und das System ist so intelligent wie die Menschen, die die Regeln geschrieben haben. Wie sieht das nun bei der korpusbasierten Intelligenz aus?
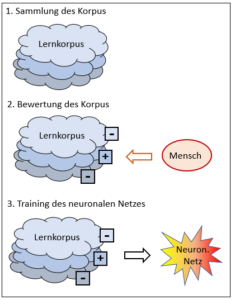
Die Antwort ist etwas komplizierter als bei den regelbasierten Systemen. Schauen wir deshalb den Aufbau eines solchen korpusbasierten Systems genauer an. Er geschieht in drei Schritten:
Erstellen einer möglichst grossen Datensammlung (Korpus)
Bewertung dieser Datensammlung
Training des neuronalen Netzes (Lernphase)
Sobald das Netz erstellt ist, kann es angewendet werden:
Anwendung des neuronalen Netzes
Schauen wir die vier Schritte genauer an und überlegen wir uns dabei, worauf es ankommt und wo die Intelligenz in das korpusbasierte System hineinkommt.
Schritt 1: Erstellung der Datensammlung
In unserem Panzerbeispiel besteht der Korpus (die Datensammlung) aus Photographien von Panzern. Bilder sind typisch für korpusbasierte Intelligenz, aber die Sammlung kann natürlich auch andere Informationen enthalten, z.B. Suchanfragen von Kunden einer Suchmaschine oder GPS-Daten von Handys. Typisch ist, dass die Daten von jedem einzelnen Eintrag aus so vielen Einzelelementen (z.B. Pixeln) bestehen, dass Ihre Auswertung mit bewusst von Menschen konstruierten Regeln zu aufwendig wird. Dann lohnt sich ein regelbasiertes System nicht mehr.
Die Sammlung der Daten reicht aber nicht aus. Sie müssen jetzt auch bewertet werden.
Schritt 2: Bewertung des Korpus
Abb. 1: Korpusbasiertes System
Abb. 1 zeigt das bereits bekannte Bild aus unserem Panzerbeispiel. Auf der linken Seiten sehen Sie den Korpus. Dieser ist in der Abbildung bereits bewertet, die Bewertung ist symbolisiert durch die kleinen schwarzen und grünen Fähnchen (Flags) links an jedem Panzerbild.
Man kann sich den bewerteten Korpus vereinfacht als eine zweispaltige Tabelle vorstellen. In der linken Spalte sitzt die Bildinformation, in der rechten die Bewertung und der Pfeil dazwischen ist die Zuordnung, die somit ein wesentlicher Teil des Korpus wird, sie sagt nämlich, zu welcher Kategorie (e oder f) das jeweilige Bild gehört, wie es also bewertet wird.
Tabelle 1: Korpus mit Bewertungen (e=eigen, f=fremd)
Typischerweise sind die Informationsmengen in den beiden Spalten von sehr unterschiedlicher Grösse. Während die Bewertung in der rechten Spalte in unserem Panzerbeispiel aus genau einem Bit besteht, enthält das Bild der linken Spalte alle Pixel der Photographie; zu jedem Pixel sind Lage, Farbe usw. abgespeichert, also eine ziemlich grosse Datenmenge. Dieser Unterschied im Grössenverhältnis ist typisch für korpusbasierte Systeme – und falls Sie philosophisch interessiert sind, möchte ich auf den Bezug zum Thema Informationsreduktion und Entropie hinweisen . Im Moment geht es uns aber um die Intelligenz in den korpusbasierten KI-Systemen und wir halten dazu fest, dass im Korpus zu jedem Bild seine korrekte Zielkategorie fest zugeordnet wird.
Bei dieser Zuordnung wissen wir nicht, wie sie geschieht, denn sie wird durch einen Menschen durchgeführt, mit den Neuronen in seinem eigenen Kopf, deren genaues Verhalten ihm wohl kaum bewusst ist. Er könnte also nicht Regeln dafür angeben. Hingegen weiss er, was die Bilder darstellen, und vermerkt das im Korpus, eben mit der Zuordnung der entsprechenden Kategorie. Diese Zuordnung kommt von aussen durch den Menschen in den Korpus, sie ist zu hundert Prozent menschengemacht. Gleichzeitig ist diese Bewertung eine absolute Bedingung und die Grundlage für den Aufbau des neuronalen Netzes. Auch später, wenn das fertig trainierte neuronale Netz den Korpus mit den von aussen eingebrachten Zuordnungen nicht mehr braucht, war er doch vorher notwendig, damit das Netz überhaupt entsteht und arbeiten kann.
Woher stammt also die Intelligenz bei der Zuordnung der Kategorien e) und f)? Es ist letztlich ein Mensch, der diese Zuordnung macht und auch falsch machen kann; es handelt sich um seine Intelligenz. Sobald die Zuordnung im Korpus einmal notiert ist, handelt es sich nicht mehr um aktive Intelligenz, sondern um fixiertes Wissen.
Abb. 2: Bewertung des Korpus
Die Bewertung des Korpus ist eine entscheidende Phase, und Intelligenz ist dabei zweifellos nötig. Die zusammen getragene Datensammlung muss bewertet werden und der Fachexperte, der diese Bewertung durchführt, muss garantieren, dass sie korrekt ist. In Abb. 2 ist die Intelligenz des Fachexperten durch den gelben Kreis repräsentiert. Der Korpus erhält das so erstellte Wissen über die Zuordnungen; die Zuordnungen selber sind in Abb. 2 als rote Pfeile dargestellt.
Wissen ist etwas anderes als die Intelligenz. Es ist einem gewissen Sinn passiv. In diesem Sinn handelt es sich bei den im Korpus festgehaltenen Informationen um Wissensobjekte, d.h. um Zuordnungen, die formuliert sind und nicht mehr bearbeitet werden müssen. Intelligenz hingegen ist ein aktives Prinzip, das selber Wertungen vornehmen kann, so wie es der menschliche Experte tut. Bei den Elementen im Korpus aber handelt es sich um Daten oder dann bei den erwähnten Zuordnungen um Resultate der Intelligenz von Experten – also um fest formuliertes Wissen.
Um dieses Wissen von der Intelligenz zu unterscheiden, habe ich es in Abb. 2 nicht gelb, sondern grün markiert.
Wir unterscheiden somit sinnvollerweise drei Dinge:
– Daten (die Datensammlung im Korpus)
– Wissen (die durchgeführte Bewertung dieser Daten)
– Intelligenz (die Fähigkeit, diese Bewertung durchzuführen).
Schritt 3: Training des neuronalen Netzes
Abb. 3: Das neuronale Netz lernt das Wissen des Korpus
In der Trainingsphase wird auf Basis des Lernkorpus das neuronale Netz aufgebaut. Damit das funktioniert, ist wieder eine beträchtliche Intelligenz notwendig, diesmal kommt sie vom KI-Experten, der das Funktionieren der Lernphase ermöglicht und steuert. Dabei spielen Algorithmen eine Rolle, die dafür verantwortlich sind, dass das Wissen im Korpus korrekt ausgewertet wird und das neuronale Netz genau die Form erhält, die bewirkt, dass alle im Korpus festgehaltenen Zuordnungen auch durch das Netz nachvollzogen werden können.
Die Wissensextraktion und die dabei verwendeten Algorithmen sind durch den braunen Pfeil zwischen Korpus und Netz symbolisiert. Wenn man will, kann man ihnen durchaus eine gewisse Intelligenz zubilligen, doch sie tun nichts, was nicht vom IT-Experten bzw. vom Wissen im Korpus vorgegeben wird. Das entstehende neuronale Netz selber hat keine eigene Intelligenz, sondern ist das Ergebnis dieses Prozesses und somit der Intelligenz der Experten. Es enthält aber beträchtliches Wissen und ist deshalb in Abb. 3 grün dargestellt, wie das Wissen im Korpus in Abb. 2. Im Gegensatz zum Korpus sind die Zuweisungen (rote Pfeile) aber jetzt wesentlich komplexer, genau so, wie es in einem neuronalen Netz eben komplexer zu und her geht als in einer einfachen zweispaltigen Tabelle (Tabelle 1).
Und noch etwas unterscheidet das Wissen im Netz vom Wissen im Korpus: Im Korpus handelt es sich um Wissen über Einzelfälle, im Netz hingegen ist das Wissen abstrakt. Es kann deshalb auch auf bisher unbekannte Fälle angewendet werden.
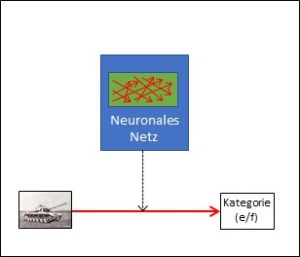
Schritt 4: Anwendung
Abb. 4: Anwendung eines neuronalen Netzes
In Abb. 4 wird ein bisher unbekanntes Bild vom neuronalen Netz bewertet und entsprechend dem im Netz gespeicherten Wissen kategorisiert. Dabei ist kein Korpus und auch kein Experte mehr nötig, es reichen die ‚geschulten‘, aber jetzt feststehenden Verdrahtungen im neuronalen Netz. Das Netz ist in diesem Moment nicht mehr in der Lage, etwas dazuzulernen. Es ist aber fähig zu durchaus eindrücklichen Leistungen mit ganz neuem Input. Diese Leistungen werden ermöglicht durch die vorgängigen Arbeiten, also den Aufbau des Korpus, die in ihm enthaltenen, (hoffentlich) korrekten Bewertungen und den Algorithmen der Lernphase. Hinter dem Lernkorpus steckt die menschliche Intelligenz des Fachexperten, hinter den Algorithmen der Trainingsphase die menschliche Intelligenz des IT-Experten.
Fazit
Was uns als künstliche Intelligenz erscheint, ist das Resultat der durchaus menschlichen, d.h. natürlichen Intelligenz der Fachexperten und IT-Spezialisten.
Dies ist ein Beitrag zum Thema künstliche Intelligenz. Im nächsten Beitrag schauen wir noch genauer hin. Wir schauen, was für Wissen in einem Korpus wirklich steckt. Und was die KI aus dem Korpus herausholen kann und was nicht.
Im Vorbeitrag erwähnte ich die beiden prinzipiellen Herangehensweisen, mit der versucht wird, dem Computer Intelligenz beizubringen, nämlich die regelbasierte und die korpusbasierte. Bei der regelbasierten steckt die Intelligenz in einem Regelpool, der von Menschen bewusst konstruiert wird. Bei der korpusbasierten Methode steckt das Wissen im Korpus, d.h. in einer Datensammlung, welche von einem raffinierten Programm analysiert wird.
Beide Methoden haben ihre Leistungen seit den 90er Jahren gewaltig steigern können. Am eindrücklichsten ist dies bei der korpusbasierten Methode geschehen, die heute als eigentliche künstliche Intelligenz gilt und in der breiten Öffentlichkeit für Schlagzeilen sorgt. Worauf beruhen die entscheidenden Verbesserungen der beiden Methoden? – Ich werde gleich auf beide Methoden und ihre Verbesserungen eingehen. Als erstes sehen wir uns an, wie die korpusbasierte KI funktioniert.
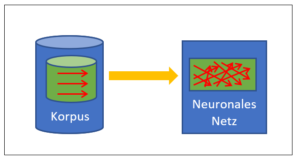
Wie funktioniert die korpusbasierte KI?
Eine korpusbasierte KI besteht aus zwei Teilen:
Korpus
Algorithmen (neuronales Netz)
Abb 1: Aufbau einer korpusbasierten KI
Der Korpus, auch Lernkorpus genannt, ist eine Sammlung von Daten. Dies können z.B. Photographien von Panzern oder Gesichtern sein, aber auch Sammlungen von Suchanfragen, z.B. von Google. Wichtig ist, dass der Korpus die Daten bereits bewertet enthält. Im Panzerbeispiel ist im Korpus vermerkt, ob es sich um eigene oder feindliche Panzer handelt. In der Gesichtersammlung ist vermerkt, um wessen Gesicht es sich jeweils handelt; bei den Suchanfragen speichert Google, welcher Link der Suchende anklickt, d.h. welcher Vorschlag von Google erfolgreich ist. Im Lernkorpus steckt also das Wissen, das die korpusbasierte KI verwenden wird.
Nun muss die KI lernen. Das Ziel ist, dass die KI ein neues Panzerbild, ein neues Gesicht oder eine neue Suchanfrage korrekt zuordnen kann. Dazu verwendet die KI das Wissen im Korpus, also z.B. die Bilder der Panzersammlung, wobei bei jedem Bild vermerkt ist, ob es sich um eigene oder fremde Panzer handelt – in Abb. 1 dargestellt durch die kleinen grauen und grünen Etiketten links von jedem Bild. Diese Bewertungen sind ein notwendiger Teil des Korpus.
Jetzt kommt der zweite Bestandteil der korpusbasierten KI ins Spiel, der Algorithmus. Im Wesentlichen handelt es sich um ein neuronales Netz. Es besteht aus mehreren Schichten von ‹Neuronen›, die Inputsignale aufnehmen, gegeneinander verrechnen und dann ihre eigenen Signale an die nächsthöhere Schicht ausgeben. In Abb. 1 ist dargestellt, wie die erste (gelbe) Neuronenschicht die Signale (Pixel) aus dem Bild aufnimmt und nach einer Verrechnung dieser Signale eigene Signale an die nächste (orange) Schicht weitergibt, bis am Schluss das Netz zum Resultat ‹eigener› oder ‹fremder› Panzer gelangt. Die Verrechnungen (Algorithmen) der Neuronen werden beim Training so lange verändert und angepasst, bis das Gesamtnetz bei jedem Bild das korrekte Resultat liefert.
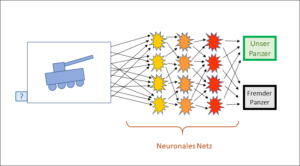
Wenn jetzt ein neues, noch unbewertetes Bild dem neuronalen Netz vorgelegt wird, verhält sich dieses genau gleich wie bei den anderen Bildern. Wenn das Netz gut trainiert worden ist, sollte der Panzer vom Programm selbstständig zugeordnet werden können, d.h. das neuronale Netz erkennt, ob das Bild einen eigenen oder fremden Panzer darstellt (Abb. 2).
Abb. 2: Suchanfrage mit noch nicht klassifiziertem Panzer an das neuronale Netz
Die Bedeutung des Datenkorpus für die korpusbasierte KI
Die korpusbasierte KI findet ihr Detailwissen im eigens für sie bereitgestellten Korpus vor und wertet die Verbindungen aus, die sie dort antrifft. Der Korpus enthält somit das Wissen, welches die korpusbasierte KI auswertet. Das Wissen besteht in unserem Beispiel in der Verbindung der Photographie, also einer Menge von wild angeordneten Pixeln mit einer einfachen binären Information (unser Panzer/fremder Panzer). Dieses Wissen findet sich im Korpus bereits bevor eine Auswertung durch die Algorithmen stattfindet. Die Algorithmen der korpusbasierte KI finden also nichts heraus, was nicht im Korpus steckt. Allerdings: Das im Korpus gefundene Wissen kann die korpusbasierte KI nun auch auf neue und noch nicht bewertete Fälle anwenden.
Die Herausforderungen an die korpusbasierte KI
Die Herausforderungen an die korpusbasierte KI sind eindeutig:
Grösse des Korpus: Je mehr Bilder sich im Korpus befinden, umso sicherer kann die Zuordnung erfolgen. Ein zu kleiner Korpus bringt Fehlresultate. Die Grösse des Korpus ist für die Präzision und Zuverlässigkeit der Resultate entscheidend.
Hardware: Die Rechenleistung, welche die korpusbasierte KI benötigt, ist sehr gross; und sie wird umso grösser, je präziser die Methode sein soll. Die Performance der Hardware entscheidet über die praktische Anwendbarkeit der Methode.
Dadurch wird schnell klar, wie die korpusbasierte KI ihre Leistung in den letzten zwei Jahrzehnten so eindrücklich verbessern konnte:
Die Datenmengen, welche Google und andere Organisationen im Internet sammeln können, sind drastisch angestiegen. Google profitiert dabei von einem nicht unbedeutenden Verstärkungseffekt: Je mehr Anfragen Google bekommt, umso besser wird der Korpus und damit seine Trefferquote. Je besser die Trefferquote, umso mehr Anfragen bekommt Google.
Die Hardware, welche zur Auswertung der Daten benötigt wird, wird immer günstiger und performanter. Internetfirmen und andere Organisationen verfügen heute über riesige Serverfarmen, welche die rechenintensiven Auswertungen der korpusbasierten KI erst möglich machen.
Neben dem Korpus und der Hardware spielt natürlich auch die Raffinesse der Algorithmen eine Rolle. Die Algorithmen waren aber auch schon vor Jahrzehnten nicht schlecht. Im Vergleich zu den beiden anderen Faktoren – Hardware und Korpus – spielt der Fortschritt bei den Algorithmen für den beeindruckenden Erfolg der korpusbasierten KI nur eine bescheidene Rolle.
Der Erfolg der korpusbasierten KI
Die Herausforderungen an die korpusbasierte KI wurden von den grossen Firmen und Organisationen äusserst erfolgreich angegangen.
Auf Basis der oben erfolgten Beschreibung der Funktionsweise sollten aber auch die systemimmanenten und in den Medien etwas weniger prominent platzierten Schwächen der korpusbasierten KI erkennbar werden. In einem späteren Beitrag werde ich genauer darauf eingehen.
KI ist heute ein grosses Schlagwort, war aber bereits in den 80er und 90er Jahren des letzten Jahrhunderts ein Thema, das für mich auf meinem Gebiet des Natural Language Processing interessant war. Es gab damals zwei Methoden, die gelegentlich als KI bezeichnet wurden und die unterschiedlicher nicht hätten sein können. Das Spannende daran ist, dass diese beiden unterschiedlichen Methoden heute noch existieren und sich weiterhin essenziell voneinander unterscheiden.
KI-1: Schnaps
Die erste, d.h. die Methode, die bereits die allerersten Computerpioniere verwendeten, war eine rein algorithmische, d.h. eine regelbasierte. Beispielhaft für diese Art Regelsysteme sind die Syllogismen des Aristoteles:
Prämisse 1: Alle Menschen sind sterblich.
Prämisse 2: Sokrates ist ein Mensch.
Schlussfolgerung: Sokrates ist sterblich.
Der Experte gibt Prämisse 1 und 2 ein, und das System zieht dann selbstständig die Schlussfolgerung. Solche Systeme lassen sich mathematisch untermauern. Mengenlehre und First-Order-Logic (Aussagelogik ersten Grades) gelten oft als sichere mathematische Grundlage. Theoretisch waren diese Systeme somit wasserdicht abgesichert. In der Praxis sah die Geschichte allerdings etwas anders aus. Probleme ergaben sich durch die Tatsache, dass auch die kleinsten Details in das Regelsystem aufgenommen werden mussten, da sonst das Gesamtsystem «abstürzte», d.h. total abstruse Schlüsse zog. Die Korrektur dieser Details nahm mit der Grösse des abgedeckten Wissens überproportional zu. Die Systeme funktionierten allenfalls für kleine Spezialgebiete, für die klare Regeln gefunden werden konnten, für ausgedehntere Gebiete wurden die Regelbasen aber zu gross und waren nicht mehr wartbar. Ein weiteres gravierendes Problem war die Unschärfe, die vielen Ausdrücken eigen ist, und die mit solchen hart-kodierten Systemen schwer in den Griff zu bekommen ist.
Diese Art KI geriet also zunehmend in die Kritik. Kolportiert wurde z.B. folgender Übersetzungsversuch: Ein NLP-Programm übersetzte Sätze vom Englischen ins Russische und wieder zurück, dabei ergab die Eingabe:
«Das Fleisch ist willig, aber der Geist ist schwach» die Übersetzung:
«Das Steak ist kräftig, aber der Schnaps ist lahm.»
Die Geschichte hat sich vermutlich nicht genau so zugetragen, aber das Beispiel zeigt die Schwierigkeiten, wenn man versucht, Sprache mit regelbasierten Systemen einzufangen. Die Anfangseuphorie, die seit den 50er Jahren mit dem «Elektronenhirn» und seiner «maschinellen Intelligenz» verbunden worden war, verblasste, der Ausdruck «Künstliche Intelligenz» wurde obsolet und durch den Ausdruck «Expertensystem» ersetzt, der weniger hochgestochen klang.
Später, d.h. um 2000, gewannen die Anhänger der regelbasierten KI allerdings wieder Auftrieb. Tim Berners-Lee, Pionier des WWW, lancierte zur besseren Benutzbarkeit des Internets die Initiative Semantic Web. Die Experten der regelbasierten KI, ausgebildet an den besten technischen Hochschulen der Welt, waren gern bereit, ihm dafür Wissensbasen zu bauen, die sie nun Ontologien nannten. Bei allem Respekt vor Berners-Lee und seinem Bestreben, Semantik ins Netz zu bringen, muss festgestellt werden, dass die Initiative Semantic Web nach bald 20 Jahren das Internet nicht wesentlich verändert hat. Meines Erachtens gibt es gute Gründe dafür: Die Methoden der klassischen mathematischen Logik sind zu rigid, die komplexen Vorgänge des Denkens nachzuvollziehen – mehr dazu in meinen anderen Beiträgen, insbesondere zur statischen und dynamischen Logik. Jedenfalls haben weder die klassischen regelbasierten Expertensysteme des 20. Jahrhunderts noch die Initiative «Semantic Web» die hoch gesteckten Erwartungen erfüllt.
KI-2: Panzer
In den 90er Jahren gab es aber durchaus auch schon Alternativen, die versuchten, die Schwächen der rigiden Aussagenlogik zu korrigieren. Dazu wurde das mathematische Instrumentarium erweitert.
Ein solcher Versuch war die Fuzzy Logic. Eine Aussage oder eine Schlussfolgerung war nun nicht mehr eindeutig wahr oder falsch, sondern der Wahrheitsgehalt konnte gewichtet werden. Neben Mengenlehre und Prädikatenlogik hielt nun auch die Wahrscheinlichkeitstheorie Einzug ins mathematische Instrumentarium der Expertensysteme. Doch einige Probleme blieben: Wieder musste genau und aufwendig beschrieben werden, welche Regeln gelten. Die Fuzzy Logic gehört also ebenfalls zur regelbasierten KI, wenn auch mit Wahrscheinlichkeiten versehen. Heute funktionieren solche Programme in kleinen, wohlabgegrenzten technischen Nischen perfekt, haben aber darüberhinaus keine Bedeutung.
Eine andere Alternative waren damals die Neuronalen Netze. Sie galten als interessant, allerdings wurden ihre praktischen Anwendungen eher etwas belächelt. Folgende Geschichte wurde dazu herum
gereicht:
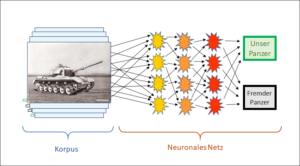
Die amerikanische Armee – seit jeher ein wesentlicher Treiber der Computertechnologie – soll ein neuronales Netz zur Erkennung von eigenen und fremden Panzern gebaut haben. Ein neuronales Netz funktioniert so, dass die Schlussfolgerungen über mehrere Schichten von Folgerungen vom System selber gefunden werden. Der Mensch muss also keine Regeln mehr eingeben, diese werden vom System selber erstellt.
Wie kann das System das? Es braucht dazu einen Lernkorpus. Bei der Panzererkennung war das eine Serie von Fotos von amerikanischen und russischen Panzern. Für jedes Foto war also bekannt, ob amerikanisch oder russisch, und das System wurde nun so lange trainiert, bis es die geforderten Zuordnungen selbstständig erstellten konnte. Die Experten nahmen auf das Programm nur indirekt Einfluss, indem sie den Lernkorpus aufbauten; das Programm stellte die Folgerungen im neuronalen Netz selbstständig zusammen – ohne dass die Experten genau wussten, aus welchen Details das System mit welchen Regeln welche Schlüsse zog. Nur das Resultat musste natürlich stimmen. Wenn das System nun den Lernkorpus vollkommen integriert hatte, konnte man es testen, indem man ihm einen neuen Input zeigte, z.B. ein neues Panzerfoto, und es wurde erwartet, dass es mit den aus dem Lernkorpus gefundenen Regeln das neue Bild korrekt zuordnete. Die Zuordnung geschah, wie gesagt, selbständig durch das System, ohne dass der Experte weiteren Einfluss nahm und ohne dass er genau wusste, wie im konkreten Fall die Schlüsse gezogen wurden.
Das funktionierte, so wurde erzählt, bei dem Panzererkennungsprogramm perfekt. So viele Fotos dem Programm auch gezeigt wurden, stets erfolgte die korrekte Zuordnung. Die Experten konnten selber kaum glauben, dass sie wirklich ein Programm mit einer hundertprozentigen Erkennungsrate erstellt hatten. Wie konnte so etwas sein? Schliesslich fanden sie den Grund: Die Fotos der amerikanischen Panzer waren in Farbe, diejenigen der russischen schwarzweiss. Das Programm musste also nur die Farbe erkennen, die Silhouetten der Panzer waren irrelevant.
Regelbasiert versus korpusbasiert
Die beiden Anekdoten zeigen, welche Probleme damals auf die regelbasierte und die korpusbasierte KI warteten.
Bei der regelbasierten KI waren es:
– die Rigidität der mathematischen Logik
– die Unschärfe unserer Wörter
– die Notwendigkeit, sehr grosse Wissenbasen aufzubauen
– die Notwendigkeit, Fachexperten für die Wissensbasen einzusetzen
Bei der korpusbasierten KI waren es:
– die Intransparenz der Schlussfolgerungs-Wege
– die Notwendigkeit, einen sehr grossen und relevanten Lernkorpus aufzubauen
Ich hoffe, dass ich mit den beiden oben beschriebenen, zugegebenermassen etwas unfairen Beispielen den Charakter und die Wirkweise der beiden KI-Typen habe darstellen können, mitsamt den Schwächen, die die beiden Typen jeweils kennzeichnen.
Die Herausforderungen bestehen selbstverständlich weiterhin. In den folgenden Beiträgen werde ich darstellen, wie die beiden KI-Typen darauf reagiert haben und wo bei den beiden Systemen nun wirklich die Intelligenz sitzt. Als Erstes schauen wir die korpusbasierte KI an.