Entropie zwischen Mikro- und Makroebene
Unter Energie kann sich jedermann etwas vorstellen, unter dem noch wichtigeren Begriff Entropie jedoch die wenigsten. Dabei spielt Entropie in der allgemeinen Physik, der Informationstheorie und der Biologie eine entscheidende Rolle.
Es gibt Gründe, weshalb der Begriff so schwierig zu verstehen ist. Das hat vor allem damit zu tun, dass Entropie physikalisch und informationstheoretisch als Abstand zwischen der Mikro- und Makroebene eines untersuchten Objekts definiert ist. Das klingt erst einmal abstrakt, doch wenn Sie sich auf den Gedanken einlassen, wird Ihnen vieles plötzlich klar werden.
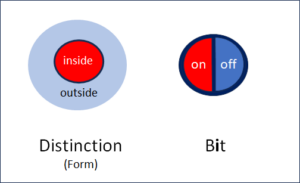
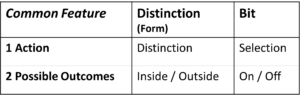
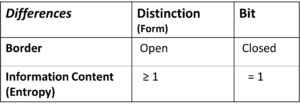
Die zwei Ebenen der Entropie: Mikro- und Makroebene
Zwei Ebenen definieren die Entropie
Die schulmässige physikalische Definition der Entropie weist diese als eine Differenz zwischen zwei Ebenen aus: einer Detail- und einer Übersichtsebene.
Beispiel Kaffeetasse
Der Begriff Entropie stammt aus der Wärmelehre, gilt aber ganz allgemein überall, wo Information ausgetauscht wird.
Klassisch ist die thermale Entropie nach Boltzmann, am Beispiel eines idealen Gases. Die Temperatur (1 Wert) ist direkt verbunden mit den Bewegungsenergien der einzelnen Gasmoleküle (1023 Werte). Mit gewissen Anpassungen gilt das für jedes materielle Objekt, z.B. auch für eine Kaffeetasse:
- Thermischer Makrozustand: Temperatur der Flüssigkeit in der Tasse.
- Thermischer Mikrozustand: Bewegungsenergie aller einzelnen Moleküle in der Tasse
Die Werte von a) und b) sind direkt verbunden. Die Wärmeenergie der Flüssigkeit, die sich in der Temperatur des Kaffees äussert, setzt sich zusammen aus den Bewegungsenergien der vielen (~ 1023) einzelnen Moleküle in der Flüssigkeit. Je schneller sich die Moleküle bewegen, umso heisser ist der Kaffee.
Die Bewegung der einzelnen Moleküle b) ist jedoch nicht konstant. Vielmehr stossen sich die Moleküle andauernd und ändern dabei ihre Geschwindigkeit und damit auch ihre Energie. Trotzdem ist die Gesamtenergie nach jedem Stoss die gleiche. Wegen dem Energiesatz ändert sich bei jedem Stoss zwar die Energie der beteiligten Moleküle, die Energie aller beteiligten Moleküle zusammen bleibt aber erhalten. Auch wenn der Kaffee langsam abkühlt, oder wenn die Flüssigkeit von aussen erhitzt wird, bleibt der Zusammenhang erhalten: Der einzelne Übersichtswert (Temperatur) und die vielen Detailwerte (Bewegungen) hängen immer gegenseitig voneinander ab.
Beispiel Wald und Bäume
Das bekannte Sprichwort warnt, vor lauter Bäumen den Wald nicht mehr zu sehen.
Wald: Makroebene

Wald: Mikroebene
Auf der Mikroebene sehen wir die Details, auf der Makroebene erkennen wir das grosse Ganze.
Welche Sicht ist nun besser? Die auf den Wald oder auf die Bäume?
- Sowohl Makroebene wie Mikroebene sind sinnvoll – je nach Aufgabe
- Beides bezieht sich auf das gleiche Objekt.
Beides ist nicht im gleichen Moment zu sehen:
- Sieht man die Bäume, verpasst man den Wald
- Erkennt man den Wald, sieht man nicht alle einzelnen Bäume
Generell glauben wir, dass es besser sei, alle Details zu kennen. Doch das ist eine Täuschung. Wir brauchen immer wieder die Übersicht. Und wir würden uns verlieren in den Details.
Wo ist nun die Entropie?
Wir können nun alle Details der Mikrosicht aufzählen und erhalten so den Informationsgehalt – z.B. in Bits – des Mikrozustandes. Von diesem können wir den viel kleineren Informationsgehalt der Makrosicht abzählen. Die Differenz, die wir erhalten ist die Entropie, nämlich die Information, die auf der Mikroebene (Bäume) vorhanden ist, auf der Makroebene (Wald) aber fehlt. Die Differenz ist die Entropie.
Warum ist nicht der Informationsgehalt auf der Mikroebene die absolute Entropie?
Der Informationsgehalt auf der Mikroebene lässt sich in Bits berechnen. Entspricht diese Bitmenge der Entropie? Dann wäre der Informationsgehalt auf der Makroebene einfach eine Reduktion der Information. Die eigentliche Information würde dann in der Mikroebene der Details stecken.
Das ist die spontane Erwartung, die ich bei Gesprächspartnern immer wieder antreffe. Sie nehmen an, dass es einen absoluten Informationsgehalt gibt, und der ist in ihren Augen selbstverständlich derjenige mit der grössten Menge an Details.
Das Problem dabei ist: Das ‚tiefste‘ Mikrolevel ist gar nicht eindeutig definiert. Die Bäume sind bezogen auf den Wald das tiefere Informationslevel – doch damit ist nicht die tiefste Detailebene erreicht. Man kann die Bäume auf ihre Bestandteile hin – Aste, Zweige, Blätter, Wurzeln, Stamm, Zellen usw. – beschreiben, was zweifellos ein tieferes Level ist und noch mehr Details enthalten würde. Doch auch dieses Level wäre nicht tief genug. Wir können durchaus noch tiefer in die Details gehen, und die verschiedenen Zellen des Baumes beschreiben, die Organellen in den Zellen, die Moleküle in den Organellen usw. Wir würden dann weiter bei der Quantenebene ankommen. Doch ist das die tiefste? Vielleicht, doch sicher ist das nicht. Und je weiter wir in die Details gehen, umso mehr entfernen wir uns von der Beschreibung des Waldes. Was uns interessiert ist die Beschreibung des Waldes und dafür ist das tiefste Level gar nicht nötig. Wir tiefer unten wir es suchen, umso mehr entfernen wir uns von der Beschreibung unseres Objekts.
→ Die Tiefe des Mikrolevels ist nicht eindeutig definiert !
Wir können deshalb für unsere Betrachtung nicht von einer eindeutigen absoluten Entropie eines bestimmten Objekts ausgehen. Weil das Mikrolevel beliebig tief ansetzbar ist, ändert sich auch die Entropie, d.h. der quantitative Informationsgehalt auf dieser Ebene. Je tiefer, umso mehr Information, umso höher die Entropie.
Gibt es ein absolutes Makrolevel?
Wie das Mikrolevel ist auch das höchste Informationslevel, z.B. eines Waldes, nicht eindeutig definiert.
Ist dieses Makrolevel das Bild, das eine optische Sicht auf den Wald darstellt, wie es ein über ihm fliegender Vogel sieht? Oder ist des die Darstellung des Waldes auf einer Landkarte? In welchem Masstab? 1:25’000 oder 1:100’000? Offensichtlich ändert sich je nach Sicht die Informationsmenge des jeweiligen Makrozustandes.
Was interessiert uns, wenn wir den Wald beschreiben? Die Wege durch den Wald? Die Baumarten? Hat es Rehe und Hasen? Wie gesund ist der Wald?
Mit anderen Worten: Der Wald kann wie jedes Objekt auf sehr unterschiedliche Weise beschrieben werden.
Es gibt kein eindeutiges, absolutes Makrolevel. Je nach Situation und Bedürfnissen gilt eine andere Makrodarstellung.
Die Relativität von Mikro- und Makroebene
Auf jeder Ebene gibt es eine jeweilige quantitative Menge an Information, je tiefer umso reichhaltiger, je höher, umso übersichtlicher. Doch es wäre ein Irrtum, eine bestimmte Ebene mit ihrer Informationsmenge als die tiefste oder die höchste zu bezeichnen. Beides ist willkürlich.
Die Information ist die Differenz
Sobald wir akzeptieren, dass sowohl das Mikro- wie das Makrolevel in beliebiger Höhe angesetzt werden können, nähern wir uns einem realeren Informationsbegriff. Es macht plötzlich Sinn, von einer Differenz zu sprechen. Die Differenz zwischen den – jeweils gewählten! – beiden Ebenen definieren die Spanne des Wissens.
Die Information, die ich gewinnen kann, ist die Information, die mir im noch Makrolevel fehlt, die ich aber im Mikrolevel finde. Die Differenz zwischen den beiden Ebenen bezüglich ihrer Entropie ist die Information, die ich dabei gewinnen kann.
Umgekehrt, wenn ich die Details der Mikroebene vor mir habe und eine Übersicht gewinnen will, muss ich diese Information der Mikroebene vereinfachen, und ich muss ihre Bitzahl reduzieren. Diese Reduktion ist die Entropie, d.h. die Information, die auf die ich bewusst verzichte.
Das Informationsparadox
Wenn ich aus einem Wust von Details die Information herausholen will, die mich interessiert, wenn ich also von der Detailbeschreibung zur verwertbaren Information gelangen will, dann muss ich ganz viel Informationen der Mikroebene unter den Tisch fallen lassen. Ich muss Information verlieren, um meine gewünschte Information zu erhalten. Dieses Paradox liegt jedem Analysevorgang zugrunde.
Information ist relativ und dynamisch
Was ich vorschlage ist ein relativer Informationsbegriff. Das entspricht nicht der Erwartung der meisten Mitmenschen, die eine statische Vorstellung von der Welt haben. Die Welt ist aber grundlegend dynamisch. Wir bewegen uns in dieser Welt wie alle anderen Lebewesen als informationsverarbeitende Existenzen. Die Verarbeitung von Information ist ein alltäglicher Vorgang für alle von uns, für alle biologischen Existenzen, ob Pflanzen, Tiere oder Menschen.
Die Verarbeitung von Information ist für alle Lebewesen ein existentieller Prozess. Dieser Prozess hat stets ein Vorher und ein Nachher. Je nachdem gewinnen wir Information, wenn wir etwas im Detail näher ansehen. Und wenn wir eine Übersicht gewinnen wollen, oder einen Entschluss (!) fassen, dann müssen wir Information vereinfachen. Wir gehen also von einer Makrobeschreibung zu einer Mikrobeschreibung und umgekehrt. Information ist dabei eine dynamische Grösse.
Entropie ist die Information, die im Makrolevel fehlt, im Mikrolevel aber zu finden ist.
Und umgekehrt: Entropie ist die Information, die im Mikrolevel vorhanden ist, im Makrolevel – also zur Gewinnung einer Übersicht – ignoriert wird.
Objekte und ihr Mikro- und Makrolevel
Wir können davon ausgehen, dass ein bestimmtes Objekt auf verschiedenen Stufen beschrieben werden kann. Ob eine tiefste Beschreibungsebene zu finden ist, ist gemäss aktuellen naturwissenschaftlichen Erkenntnissen ungewiss, doch für unsere informationstheoretischen Überlegungen letztlich irrelevant. Genauso ist es nicht sinnvoll von einer höchsten Makroebene zu sprechen. Die Makroebenen richten sich nach der Aufgabe der jeweiligen Betrachtung.
Was aber relevant ist, ist der Abstand, also die Information, die im Makrozustand zu gewinnen ist, wenn tiefere Details in die Sicht integriert werden, oder wenn sie – zwecks besserer Übersicht – verworfen werden. Beidemale geht es um eine Differenz zwischen zwei Beschreibungsebenen.
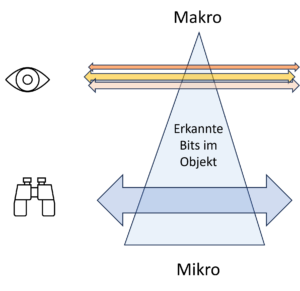
Die Darstellung oben visualisiert die Menge der erkannten Bits in einem Objekt. Oben bei der Makrospitze sind es wenige, unten im Mikrolevel sind es viele. Das Objekt bleibt das gleiche, ob nun viele oder wenige Details berücksichtigt, bzw. erkannt werden.
Die Makrosicht bringt wenige Bits, doch ihre Auswahl wird nicht vom Objekt allein bestimmt, es kommt vielmehr auch auf das Interesse hinter der Sichtweise an.
Die Zahl der Bits, d.h. die Entropie nimmt von unten nach oben ab. Das ist aber nicht eine Eigenschaft des Objekts der Betrachtung, sondern eine Eigenschaft der Betrachtung selber. Je nachdem sehe ich das Objekt anders, einmal detailliert und unübersichtlich, ein anderes Mal übersichtlich und vereinfacht, d.h.einmal mit viel und ein anderes Mal mit weniger Entropie.
Die Informationsgewinnung ist der dynamische Vorgang, der entweder
a) mehr Details erkennt: Makro → Mikro
b) mehr Übersicht gewinnt: Mikro → Makro
Beidemale wird die Informationsmenge (Entropie als Bitmenge) verändert. Die gewonnenen oder verlorenen Bits entsprechen der Differenz der Entropie von Mikro- und Makrolevel.
Wenn ich das Objekt in den Blick nehme, enthüllt es je nach Betrachtungsweise mehr oder weniger Information. Information ist dabei stets relativ zum Vorwissen und dynamisch zu verstehen.
Das ist ein Beitrag zum Thema Entropie. Siehe -> Übersichtsseite Entropie