Haben die neuronalen Netze die regelbasierten Systeme abgehängt?
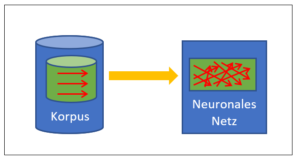
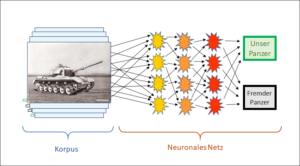
Es ist nicht zu übersehen: Die korpusbasierte KI hat die regelbasierte KI um Längen überholt. Neuronale Netze machen das Rennen, wohin man schaut. Schläft die Konkurrenz? Oder sind regelbasierte Systeme schlicht nicht in der Lage, gleichwertige Ergebnisse wie neuronale Netze zu erzielen?
Meine Antwort ist, dass die beiden Methoden aus Prinzip für sehr unterschiedliche Aufgaben prädisponiert sind. Ein Blick auf die jeweiligen Wirkweisen macht klar, wofür die beiden Methoden sinnvollerweise eingesetzt werden. Je nach Fragestellung ist die eine oder die andere im Vorteil.
Trotzdem bleibt das Bild: Die regelbasierte Variante scheint auf der Verliererspur. Woher kommt das?
In welcher Sackgasse steckt die regelbasierte KI?
Meines Erachtens hat das Hintertreffen der regelbasierten KI damit zu tun, dass sie ihre Altlasten nicht loswerden will. Dabei wäre es so einfach. Es geht darum:
- Semantik als eigenständiges Wissensgebiet zu erkennen
- Komplexe Begriffsarchitekturen zu verwenden
- Eine offene und flexible Logik (NMR) einzubeziehen.
Wir tun dies seit über 20 Jahren mit Erfolg. Andernorts allerdings ist
die Notwendigkeit dieser drei Neuerungen und des damit verbundenen Paradigmenwechsels noch nicht angekommen.
Was bedeuten die drei Punkte nun im Detail?
Punkt 1: Semantik als eigenständiges Wissensgebiet erkennen
Üblicherweise ordnet man die Semantik der Linguistik zu. Dem wäre im Prinzip nichts entgegen zu halten, doch in der Linguistik lauert für die Semantik eine kaum bemerkte Falle: Linguistik beschäftigt sich mit Wörtern und Sätzen. Der Fehler entsteht dadurch, dass man die Bedeutung, d.h. die Semantik, durch den Filter der Sprache sieht und glaubt, ihre Elemente auf die gleiche Weise anordnen zu müssen, wie die Sprache das mit den Wörtern macht. Doch die Sprache unterliegt einer entscheidenden Einschränkung, sie ist linear, d.h. sequenziell: Ein Buchstabe kommt nach dem anderen, ein Wort nach dem anderen. Es ist nicht möglich, Wörter parallel nebeneinander zu setzen. Im Denken können wir das aber. Und wenn wir die Semantik von etwas untersuchen, geht es darum, wie wir denken und nicht, wie wir sprechen.
Wir müssen also Formalismen finden für die Begriffe, wie sie im Denken vorkommen. Die Beschränkung durch die lineare Anordnung der Elemente und die sich daraus ergebende Notwendigkeit, behelfsweise und in jeder Sprache anders mit grammatikalischen Kunstgriffen Klammerungen und komplexe Beziehungsstrukturen nachzubilden, diese Beschränkung gilt im Denken nicht und wir erhalten dadurch auf der semantischen Seite ganz andere Strukturen als auf der sprachlichen Seite.
Wort ≠ Begriff
Was sicher nicht funktioniert, ist eine simple «semantische Annotation» von Wörtern. Ein Wort kann viele, sehr unterschiedliche Bedeutungen haben. Eine Bedeutung (= ein Begriff) kann durch unterschiedliche Wörter ausgedrückt werden. Wenn man Texte analysieren will, darf man nicht die einzelnen Wörter, sondern muss immer den Gesamtkontext ansehen. Nehmen wir das Wort «Kopf». Wir sprechen z.B. vom Kopf eines Briefes oder vom Kopf eines Unternehmens. Wir können nun den Kontext in unseren Begriff hineinnehmen, indem wir den Begriff <Kopf< mit anderen Begriffen verbinden. So gibt es einen <Körperteil<Kopf< und eine <Funktion<Kopf<. Der Begriff links (<Körperteil<) sagt dann aus, von welchem Typ der Begriff rechts (<Kopf<) ist. Wir typisieren also. Wir suchen den semantischen Typ eines Begriffs und setzen ihn vor den Unterbegriff.
Konsequent komposite Datenelemente
Die Verwendung typisierter Begriffe ist nichts Neues. Wir gehen aber weiter und bilden ausgedehnte strukturierte Graphen, diese komplexen Graphen bilden dann die Basis unserer Arbeit. Das ist etwas ganz anderes als die Arbeit mit Wörtern. Die Begriffsmoleküle, die wir verwenden, sind solche Graphen, die eine ganz spezielle Struktur aufweisen, sodass sie sowohl für Menschen wie für Maschinen leicht und schnell lesbar sind. Die komposite Darstellung hat viele Vorteile, einer ist z.B. dass der kombinatorischen Explosion ganz einfach begegnet wird und so die Zahl der atomaren Begriffe und Regeln drastisch gekürzt werden kann. Durch die Typisierung und die Attribute können ähnliche Begriffe beliebig geschärft werden, wir können mit Molekülen dadurch sehr präzis «sprechen». Präzision und Transparenz der Repräsentation haben darüber hinaus viel damit zu tun, dass die spezielle Struktur der Graphen (Moleküle) direkt von der multifokalen Begriffsarchitektur abgeleitet ist (siehe im folgenden Punkt 2).
Punkt 2: Komplexe Begriffsarchitekturen verwenden
Begriffe sind in den Graphen (Begriffsmoleküle) über Relationen verbunden. Die oben genannte Typisierung ist eine solche Relation: Wenn der <Kopf< als ein <Körperteil< gesehen wird, dann ist er vom Typ <Körperteil< und es besteht eine ganz bestimmte Relation zwischen <Kopf< und <Körperteil<, nämlich eine sogenannte hierarchische oder ‹IS-A‹-Relation – letzteres darum, weil man bei hierarchischen Relationen immer ‹IST-EIN› sagen kann, also in unserem Fall: der <Kopf< ist ein <Körperteil<.
Die Typisierung ist eine der beiden grundlegenden Relationen in der Semantik. Wir ordnen eine Anzahl Begriffe einem übergeordneten Begriff, also ihrem Typ zu. Dieser Typ ist natürlich genauso ein Begriff und er kann deshalb selber wieder typisiert werden. Dadurch entstehen hierarchische Ketten von ‹IS-A›-Relationen, mit zunehmender Spezifizierung, z.B. <Gegenstand<Möbel<Tisch<Küchentisch<. Wenn wir alle Ketten der untergeordneten Begriffe, die von einem Typ ausgehen, zusammenbinden, erhalten wir einen Baum. Dieser Baum ist der einfachste der vier Architekturtypen für die Anordnung von Begriffen.
Von dieser Baumstruktur gehen wir aus, müssen aber erkennen, dass eine blosse Baumarchitektur entscheidende Nachteile hat, die es verunmöglichen, damit wirklich präzis greifende Semantiken zu bauen. Wer sich für die verbesserten und komplexeren Architekturtypen und ihre Vor- und Nachteile interessiert, findet eine ausführliche Darstellung der vier Architekturtypen auf der Website von meditext.ch.
Bei den Begriffsmolekülen haben wir den gesamten Formalismus, d.h. die innere Struktur der Regeln und Moleküle selbst auf die komplexen Architekturen ausgerichtet. Das bietet viele Vorteile, denn die Begriffsmoleküle weisen jetzt in sich genau die gleiche Struktur auf wie die Achsen der multifokalen Begriffsarchitektur. Man kann die komplexen Faltungen der multifokalen Architektur als Gelände auffassen, mit den Dimensionen oder semantischen Freiheitsgraden als komplex verschachtelte Achsen. Die Begriffsmoleküle nun folgen diesen Achsen in ihrer eigenen inneren Struktur. Das macht das Rechnen mit den Molekülen so einfach. Mit simplen Hierarchiebäumen oder multidimensionalen Systemen würde das nicht funktionieren. Und ohne konsequent komposite Datenelemente, deren innere Struktur auf fast selbstverständliche Weise den Verzweigungen der komplexen Architektur folgt, auch nicht.
Punkt 3: Eine offene und flexible Logik (NMR) einbeziehen
Dieser Punkt ist für theoretisch vorbelastete Wissenschaftler möglicherweise der härteste. Denn die klassische Logik erscheint den meisten unverzichtbar und viele kluge Köpfe sind stolz auf ihre Kenntnisse darin. Klassische Logik ist in der Tat unverzichtbar – nur muss sie am richtigen Ort eingesetzt werden. Meine Erfahrung zeigt, dass wir im Bereich des NLP (Natural Language Processing) eine andere Logik brauchen, nämlich eine, die nicht monoton ist. Eine solche nichtmonotone Logik (NMR) erlaubt es, für das gleiche Resultat mit viel weniger Regeln in der Wissensbasis auszukommen. Die Wartung wird dadurch zusätzlich vereinfacht. Auch ist es möglich, das System ständig weiter zu entwickeln, weil es logisch offen bleibt. Ein logisch offenes System mag einen Mathematiker beunruhigen, die Erfahrung aber zeigt, dass ein NMR-System für die regelbasierte Erfassung des Sinns von frei formuliertem Text wesentlich besser funktioniert als ein monotones.
Fazit
Heute scheinen die regelbasierten Systeme im Vergleich zu den korpusbasierten im Hintertreffen zu sein. Dieser Eindruck täuscht aber und rührt daher, dass die meisten regelbasierten Systeme den Sprung in ein modernes System noch nicht vollzogen haben. Dadurch sind sie entweder:
- nur für Aufgaben in kleinem und wohldefiniertem Fachgebiet anwendbar oder
- sehr rigid und deshalb kaum einsetzbar oder
- sie benötigen einen unrealistischen Ressourceneinsatz und werden unwartbar.
Wenn wir aber konsequent komposite Datenelemente und höhergradige Begriffsarchitekturen verwenden und bewusst darauf verzichten, monoton zu schliessen, kommen wir – für die entsprechenden Aufgaben – mit regelbasierten Systemen weiter als mit korpusbasierten.
Regelbasierte und korpusbasierte Systeme sind sehr unterschiedlich und je nach Aufgabe ist das eine oder das andere im Vorteil. Darauf werde ich in einem späteren Beitrag eingehen.
Dies ist ein Beitrag zum Thema künstliche Intelligenz (KI). Ein Folgebeitrag beschäftigt sich mit der aktuellen Verbreitung der beiden KI-Methoden.