Ein simpler Knochenbruch
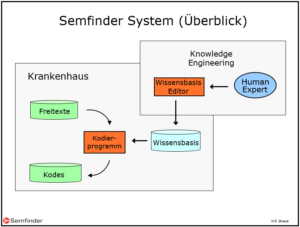
Um im Gesundheitswesen Transparenz zu schaffen werden die medizinischen Diagnosen codiert. Dies ist nötig, weil die Diagnosen sehr unterschiedlich formuliert werden können. So kann ein Patient z.B. an Folgendem leiden:
– einem Armbruch
– einer distale Fraktur des Radius
– einer Radiusfraktur loco classico
– einer geschlossenen Extensionsfraktur am distalen Radius
– einem Bruch der Speiche links
– einem Knochenbruch am linken Unterarm
– einer Fx des dist. Radius li
– einer Colles-fracture
Alle obigen Ausdrücke können den gleichen Sachverhalt bezeichnen, einmal präziser formuliert, einmal weniger und mit unterschiedlichen Wörtern und Abkürzungen. Die Liste liesse sich noch lange fortsetzen. Ich habe mich während Jahrzehnten mit solchen Ausdrücken befasst und kann Ihnen versichern, dass es ohne Übertreibung Milliarden von unterschiedlichen, aber absolut korrekten Formulierungen für medizinische Diagnosen gibt.
Selbstverständlich entzieht sich dieser Wust von Freitexten einer statistischen Bearbeitung und deshalb werden die Diagnosen codiert. Häufig wird dabei der ICD (International Classification of Diseases) Code verwendet, der ja nach Variante zwischen 15’000 und 80’000 Codes umfasst. Zehntausende von Codes sind natürlich viele, aber in Anbetracht der Milliarden von möglichen Textformulierungen sind die ICD-Codes vergleichsweise überschaubar.
Wie die Interpretation der Texte automatisiert wird, sodass sie von einem Computerprogramm durchgeführt werden kann, ist übrigens eine hochspannende Angelegenheit.
Morsecode
Ein Morsecode dient der Kommunikation in Fällen wo nur ganz einfache Signale gesendet werden können. Die Buchstaben des Alphabets werden vom Sender als Punkte und Striche codiert und so gesendet und vom Empfänger decodiert, also wieder in Buchstaben umgewandelt. So wird ein E zu einem Punkt und ein A zu einem Punkt, gefolgt von einem Strich. Der Vorgang der Codierung/Decodierung ist perfekt umkehrbar, die Abbildung ist eineindeutig.
Kryptographie
Auch hier soll der Code wieder in die ursprüngliche Form zurückübersetzt werden. Der Unterschied zum Morsecode besteht einzig darin, dass die Übersetzungsvorschrift nur einem kleinen Kreis bekannt sein soll und meist auch etwas komplizierter ist. Wie beim Morsecode soll die verschlüsselte Form aber die gleiche Information tragen wie die ursprüngliche Form.
Informationsreduktion
Morsecode und kryptographische Codes haben beide das Ziel, dass am Ende der Empfänger wieder die ursprüngliche Botschaft herstellen kann. Die Information soll unverändert bleiben, nur die äussere Form ändert sich.
Beim ICD-Code ist die Situation aber eine ganz andere. Es geht dabei nicht um die Wörter, die 1:1 austauschbar sind, wie z.B. im obigen Beispiel das Wort Radius und das Wort Speiche . Bei der ICD-Codierung geht es nicht um umkehrbare Abbildungen. Es geht vielmehr darum, dass Information bewusst unter den Tisch fällt und definitiv verloren geht. Die ICD-Codes sind Schubladen, die mit unterschiedlichen Diagnosen gefüllt werden. Und das mit gutem Grund: Es gibt einfach zu viele Detaillierungen bei den Diagnosen. So kann eine Fraktur folgende voneinander unabhängige Charakteristika aufweisen:
– Name des betroffenen Knochens
– Stelle am betroffenen Knochen
– Zustand der Hautbarriere (offen/geschlossen)
– Gelenkbeteiligung (intraartikulär/extraartikulär)
– Richtung der Fehlstellung (Flexion, Extension …)
– Art der Bruchlinie (spiral, etc).
– Zahl und Art der Bruchfragmente (Monoblock, Trümmerfraktur)
– Ursache (Trauma, Tumor-Metastase, Ermüdung)
– u.v.m.
Alle diese Merkmale sind kombinierbar, was sich mathematisch als Multiplikation der Möglichkeiten präsentiert. Eine medizinische Statistik kann selbstverständlich nicht alle Kombinationsvarianten berücksichtigen, deshalb berücksichtigt der Diagnosecode nur wenige und die ICD kommt in Deutschland und der Schweiz mit weniger als 20’000 Schubladen für die gesamte Medizin zurecht. Welche Information die Schubladen berücksichtigen und welche nicht, ist ein wichtiges Thema, sowohl für die Akteure im Gesundheitswesen wie auch für uns, die wir uns informationstheoretische (und -praktische!) Überlegungen zum Codiervorgang machen.
Zwei Arten von Codierung
Ich halte den oben genannten Unterschied für bedeutsam. Einerseits haben wir Codierungen, die das Ziel haben, die Information zu erhalten und nur die Form zu ändern, so wie der Morsekode und kryptographische Verschlüsselungen. Andererseits haben wir Codierungen wie die medizinische Diagnosecodierung, deren Ziel es ist, die Menge an Information zu reduzieren. Der Grund dieser Informationsreduktion ist, dass die Ursprungsmenge an Information zu gross ist und sie zum Zweck der Übersichtlichkeit vereinfacht werden muss – meist drastisch. Informationsreduzierende Codierung verhält sich entscheidend anders als informationserhaltende.
Dieser Unterschied hat es in sich. Mathematische Modelle und wissenschaftliche Theorien, die für die informationserhaltende Codierung gelten, sind für die informationsreduzierende nicht verwendbar. Wir stehen hier informationstheoretisch vor einer ganz anderen Situation. Mehr dazu in Zwei Arten von Kodierung 2.
Die Informationsreduktion ist ein Vorgang, der bei realer Informationsverarbeitung häufig an entscheidender Stelle vorkommt. Einen Einstieg in das Thema Informationsreduktion finden Sie hier.