Was unter Künstlicher Intelligenz (KI) allgemein verstanden wird, sind sogenannte Neuronale Netze.
Neuronale Netze sind potent und für ihre Anwendungsgebiete unschlagbar. Sie erweitern die technischen Möglichkeiten unserer Zivilisation massgeblich auf vielen Gebieten. Trotzdem sind neuronale Netze nur eine Möglichkeit, ‹intelligente› Computerprogramme zu organisieren.
Korpus- oder regelbasiert?
Neuronale Netze sind korpusbasiert, d. h. ihre Technik basiert auf einer Datensammlung, dem Korpus, der von aussen in einer Lernphase Datum für Datum bewertet wird. Das Programm erkennt anschliessend in der Bewertung der Daten selbständig gewisse Muster, die auch für bisher unbekannte Fälle gelten. Der Prozess ist automatisch, aber auch intransparent.
In einem realen Einzelfall ist nicht klar, welche Gründe für die Schlussfolgerungen herangezogen worden sind. Wenn der Korpus aber genügend gross und korrekt bewertet ist, ist die Präzision der Schlüsse ausserordentlich hoch.
Grundsätzlich anders funktionieren regelbasierteSysteme. Sie brauchen keine Datensammlung, sondern eine Regelsammlung. Die Regeln werden von Menschen erstellt und sind transparent, d. h. leicht les- und veränderbar. Regelbasierte Systeme funktionieren allerdings nur mit einer adäquaten Logik (dynamische, nicht statische Logik) und einer für komplexe Semantiken geeigneten, multifokalen Begriffsarchitektur; beides wird in den entsprechenden Hochschulinstituten bisher kaum gelehrt.
Aus diesem Grund stehen regelbasierte Systeme heute eher im Hintergrund, und was allgemein unter künstlicher Intelligenz verstanden wird, sind neuronale Netze, also korpusbasierte Systeme.
Ganz kurz: Die Intelligenz steckt immer ausserhalb.
a) Regelbasierte Systeme
Die Regeln und Algorithmen dieser Systeme – Typ A1 und A2 – werden von Menschen erstellt und niemand wird einem Taschenrechner wirkliche Intelligenz zubilligen. Das Gleiche gilt auch für alle anderen, noch so raffinierten regelbasierten Systeme. Die Regeln werden von Menschen gebaut.
b) Konventionelle korpusbasierte Systeme (Mustererkennung)
Diese Systeme (Typ B1) verwenden immer einen bewerteten Korpus, also eine Datensammlung, die bereits bewertet worden ist (Details). Die Bewertung entscheidet, nach welchen Zielen jeder einzelne Korpuseintrag klassifiziert wird und die Klassifizierung stellt dann das wirkliche Wissen im Korpus dar.
Die Klassierung ist aber nicht aus den Daten des Korpus selber ableitbar, sondern erfolgt immer von ausserhalb. Und nicht nur die Zuweisung eines Dateneintrags zu einer Klasse ist nur von aussen durchführbar, auch die Klassen selber sind nicht durch die Daten des Korpus determiniert, sondern werden von aussen – letztlich von Menschen – vorgegeben.
Die Intelligenz bei diesen Systemen steckt immer in der Bewertung des Datenpools, d.h. der Zuteilung der Datenobjekte zu vorgegebenen Klassen, und diese erfolgt von aussen durch Menschen. Das neuronale Netz, das dabei entsteht, weiss nicht, wie das menschliche Hirn die dafür nötigen Bewertungen gefunden hat.
c) Suchmaschinen
Diese (Typ B2) stellen einen Sonderfall der korpusbasierten Systeme dar und basieren auf der Tatsache, dass viele Menschen eine bestimmte Suchmaschinen benützen und mit ihren Klicks entscheiden, welche Internetlinks den Suchbegriffen zugeordnet werden können. Die Suchmaschinen mitteln am Ende nur, welche Spuren die vielen Benutzer mit ihrem eigenen Kontextwissen und ihren jeweiligen Absichten gelegt haben. Ohne die menschlichen Gehirne der bisherigen Suchmaschinenbenutzer wüssten die Suchmaschinen nicht, wohin sie zeigen sollten.
d) Spielprogramme (Schach, Go, usw.) / Deep Learning
Hier wird es interessant, denn diese Programme (Typ B3) brauchen im Gegensatz zu den anderen korpusbasierten Systemen keinen Menschen, der von aussen den Korpus (bestehend aus den Zügen bereits gespielter Partien) beurteilt. Verfügen diese Systeme also über eine eigenständige Intelligenz?
Wie die Programme zur Mustererkennung (b) und die Suchmaschinen (c) verfügt das Go-Programm über einen Korpus, der in diesem Fall die Züge der gespielten Testpartien enthält. Der Unterschied zu klassischen KI-Systemen besteht nun darin, dass die Bewertung des Korpus (d.h. der Spielzüge) bereits durch den Spielerfolg in der betreffenden Partie definiert ist. Es braucht also keinen Menschen, der fremde von eigenen Panzern unterscheiden muss und dadurch die Vorlage für das neuronale Netz liefert. Der Spielerfolg kann von der Maschine, d.h. dem Algorithmus, selber direkt erkannt werden, ein Mensch ist dafür nicht nötig.
Bei klassischen KI-Systemen ist dies nicht der Fall, und es braucht unbedingt einen Menschen, der die einzelnen Korpuseinträge bewertet. Dazu kommt, dass das Kriterium der Bewertung nicht wie bei Go eindeutig gegeben ist. Panzerbilder können z.B. ganz unterschiedlich kategorisiert werden (Radpanzer/Kettenpanzer, beschädigte/unbeschädigte Panzer, Panzer in Städten/Feldern, auf Farbbildern/Schwarzweiss-Bildern etc.). Dies öffnet die Interpretationsmöglichkeiten für die Bewertung beliebig. Eine automatische Zuweisung ist aus all diesen Gründen bei klassischen KI-System nicht möglich, und es braucht immer die Bewertung des Lernkorpus durch menschliche Experten.
Bei Schach und Go ist dies gerade nicht nötig. Denn Schach und Go sind künstlich konstruierte und völlig geschlosseneSysteme und deshalb in der Tat von vornherein vollständig determiniert. Das Spielfeld, die Spielregeln und das Spielziel – und damit auch die Bewertung der einzelnen Züge – sind automatisch gegeben. Deshalb braucht es keine zusätzliche Intelligenz, sondern ein Automatismus kann innerhalb des vorgegebenen, geschlossenen Settings Testpartien mit sich selber spielen und das vorgegebene Ziel so immer besser erreichen, bis er besser ist als jeder Mensch.
Bei Aufgaben, die sich nicht in einem künstlichen Spielraum, sondern in der Realität stellen, sind die erlaubten Züge und die Ziele aber nicht vollständig definiert und der Strategie-Raum bleibt offen. Eine Automatik wie Deep Learning ist in offenen, d.h. realen Situationen nicht anwendbar.
In der Praxis braucht es selbstverständlich eine beträchtliche Intelligenz, um den Sieg in Go und anderen Spielen zu programmieren und wir dürfen die Intelligenz der Ingenieuren von Google durchaus dafür bewundern, doch ist es eben wieder ihre menschliche Intelligenz, die sie die Programme entwickeln lässt, und nicht eine Intelligenz, die die von ihnen konstruierten Programme selbständig entwickeln könnten.
Fazit
KI-Systeme können sehr eindrücklich und sehr nützlich sein, sie verfügen aber nie über eigene Intelligenz.
Die einen versprechen sich den entscheidenden Technologiesprung, die anderen fürchten, dass eine gleichzeitig unfehlbare und fehlgeleitete künstliche Intelligenz die Menschheit unterjochen könnte.
Was ist daran wahr? – Ich arbeite seit einem Vierteljahrhundert mit «intelligenten» Informatiksystemen und wundere mich vor allem darüber, dass wir den neuronalen Netzen – zugegebenermassen sehr leistungsfähigen Systemen – überhaupt echte, d.h. eigenständige Intelligenz zubilligen.
Genau die haben sie nämlich nicht. Ihre Intelligenz kommt stets von Menschen, welche die Daten nicht nur liefern, sondern auch bewerten, bevor die KI sie verwenden kann. Ihre Leistungsfähigkeit zeigt die KI nur, wenn die Aufgabenstellung klar und einfach ist. Sobald die Fragestellung komplex wird, versagen sie. Oder sie flunkern, indem sie schöne Sätze, die sich in ihrem Datenschatz finden, so anordnen, dass es intelligent klingt (ChatGPT, LaMDA). Sie arbeiten nicht mit Logik, sondern mit Statistik, also mit Wahrscheinlichkeit. Aber ist das Wahr-Scheinliche auch immer das Wahre?
Wie funktioniert KI überhaupt? Wo sind ihre Grenzen? Wie unterscheiden sich die unterschiedlichen Arten der KI? Was steckt hinter Deep Learning? Ist künstliche Intelligenz wirklich intelligent? Und falls Sie das glauben, wo genau steckt die Intelligenz in der künstlichen Intelligenz – und wie kommt sie da hinein?
Diese Fragen werden ich im Folgenden zu beantworten versuchen. Unten sehen Sie meine Blogbeiträge zum Thema in systematischer Ordnung.
Die Beiträge sind im August 2021 auch als Buch erschienen. Sie können das Buch direkt beim Verlag bestellen:
Die Computerintelligenz verfügt über zwei grundlegend verschiedene Methoden: Sie kann entweder auf Regeln oder auf einer Datensammlung (=Korpus) beruhen. Im Einstiegsbeitrag stelle ich sie mit zwei charakteristischen Anekdoten vor:
Die regelbasierten Systeme hatten es schwieriger. Was sind ihre Herausforderungen? Wie können sie ihre Schwächen überwinden? Und wo steckt bei ihnen die Intelligenz?
Zurück zu den korpusbasierten Systemen. Wie sind sie aufgebaut? Wie wird ihr Korpus zusammengestellt und bewertet? Was hat es mit dem neuronalen Netz auf sich? Und was sind die natürlichen Grenzen der korpusbasierten Systeme?
Als nächstes beschäftigen wir uns mit Suchmaschinen, die ebenfalls korpusbasierte Systeme sind. Wie gelangen sie zu ihren Vorschlägen? Wo sind ihre Grenzen und Gefahren? Weshalb entstehen z.B. zwingend Blasen?
Kann ein Programm lernen, ohne dass ein Mensch ihm gute Ratschläge zuflüstert? Mit Deep Learning scheint das zu klappen. Um zu verstehen, was dabei passiert, vergleichen wir zuerst ein einfaches Kartenspiel mit Schach: Was braucht mehr Intelligenz? Überraschend wird klar, dass für den Computer Schach das einfachere Spiel ist.
An den Rahmenbedingungen von Go und Schach erkennen wir, unter welchen Voraussetzungen Deep Learning funktioniert.
Im anschliessenden Beitrag gebe ich einen systematischen Überblick über die mir bekannten KI-Arten, skizziere kurz ihren jeweiligen Aufbau und die Unterschiede in ihrer Funktionsweise.
Alle bis jetzt untersuchten Systeme, inkl. Deep Learning, lassen sich in ihrem Kern auf zwei Methoden zurückführen, die regel- und die korpusbasierte. Dies gilt auch für die bisher nicht besprochenen Systeme, nämlich den einfachen Automaten und die hybriden Systeme. Letztere kombinieren die beiden Herangehensweisen.
Wenn wir diese Varianten integrieren, gelangen wir zur folgenden Übersicht:
A: Regelbasierte Systeme
Regelbasierte Systeme basieren auf Rechenregeln. Bei diesen Regeln handelt es sich immer um ‹IF-THEN› Befehle, also um Anweisungen, die einem bestimmten Input ein bestimmtes Ergebnis zuweisen. Diese Systeme sind immer deterministisch, d.h. ein bestimmter Input führt immer zum gleichen Resultat. Ebenfalls sind diese Systeme immer explizit, d.h. es gibt keine Vorgänge, die nicht sichtbar gemacht werden können und das System ist – mindestens im Prinzip – immer vollständig durchschaubar. Regelbasierte Systeme können allerdings recht komplex werden.
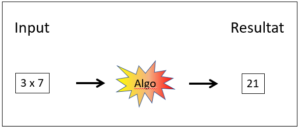
A1: Einfacher Automat (Typ Taschenrechner)
Abb. 1: Einfacher Automat
Regeln werden auch als Algorithmen («Algo» in Abb. 1) bezeichnet. Selbstverständlich können mit einfachen Automaten auch sehr komplexe Berechnungen durchgeführt werden und Input und Output (Resultat) müssen nicht Zahlen sein. Der einfache Automat zeichnet sich vor den anderen Systemen dadurch aus, dass er keine spezielle Wissensbasis und keinen Korpus braucht, sondern mit wenigen Rechenregeln auskommt.
Vielleicht würden Sie den Taschenrechner nicht als KI-System bezeichnen, doch die Unterschiede zu den höher entwickelten Systemen bis hin zum Deep Learning sind nur gradueller Natur – bzw. von genau der Art, wie sie hier auf dieser Seite beschrieben werden. Komplexe Rechenleistungen erscheinen uns schnell einmal als intelligent, besonders dann, wenn wir sie mit unseren menschlichen Gehirnen nicht so einfach nachvollziehen können. Das gilt bereits für einfache Rechenoperationen wie Divisionen und Wurzelziehen, bei denen wir schnell an unsere Grenzen stossen. Gesichtserkennung erscheint uns hingegen vergleichsweise einfach, weil wir das meist auch ohne Computer ganz gut können. Übrigens gehört Mühlespielen auch in die Kategorie A1, es braucht zwar eine gewisse Intelligenz, um es zu spielen, aber es ist vollständig und einfach mit einem KI-Programm vom Typ A1 beherrschbar.
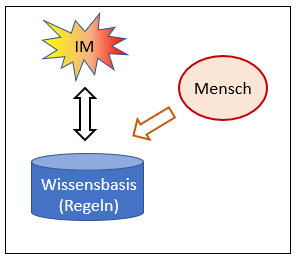
A2: Wissensbasiertes System
Abb. 2: Erstellen einer Wissensbasis
Diese Systeme unterscheiden sich von einfachen Automaten dadurch, dass ein Teil ihrer Regeln in einer Wissensbasis ausgelagert ist. Abb. 2 weist darauf hin, dass diese Wissensbasis von einem Menschen aufgebaut wird; Abb. 3 zeigt, wie sie angewendet wird. Die Intelligenz steckt in den Regeln, sie kommt vom Menschen – bei der Anwendung reicht dann die Wissensbasis allein.
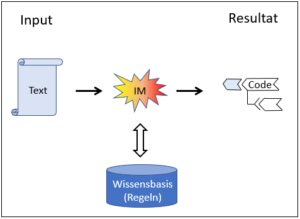
Abb. 3: Anwenden eines wissensbasierten Systems
Die Inferenzmaschine («IM» in Abb. 2 und 3) entspricht den Algorithmen der einfachen Automaten in Abb. 1. Im Prinzip handelt es sich bei den Algorithmen, der Inferenzmaschine und den Regeln der Wissensbasen immer um Regeln, also um explizite ‹IF-THEN›- Anweisungen. Diese können allerdings unterschiedlich komplex verwoben und verschachtelt sein. Sie können sich auf Zahlen oder auf Begriffe beziehen.
Die Regeln in der Wissensbasis sind nun den Regeln der Inferenzmaschine untergeordnet. Letztere kontrollieren den Fluss der Interpretation, d.h. sie entscheiden, welche Regeln der Wissensbasis anzuwenden und wie sie auszuführen sind. Die Regeln der Inferenzmaschine sind das eigentliche Programm, das vom Computer gelesen und ausgeführt wird. Die Regeln der Wissensbasis hingegen werden vom Computer nicht direkt, sondern indirekt über die Anweisungen der Inferenzmaschine ausgeführt. Es handelt sich also um eine Verschachtelung – wie sie im Übrigen typisch für die Befehle (Software) in einem Computer sind. Auch die Regeln der Inferenzmaschine werden ja nicht direkt ausgeführt, sondern von tieferen Regeln gelesen, bis hinunter zur Maschinensprache im Kern (Kernel) des Rechners. Im Prinzip sind aber die Regeln der Wissensbasis genauso Rechenregeln wie die Regeln der Inferenzmaschine, nur eben in einer ‹höheren› Programmiersprache. Diese zeichnet sich vorteilhafterweise dadurch aus, dass sie für die Domain-Experten, d.h. für die menschlichen Fachexperten, besonders einfach und sicher les- und handhabbar ist.
Bezüglich des in der Inferenzmaschine verwendeten Logiksystems unterscheiden wir regelbasierte Systeme
– mit statischer Logik (Typ Ontologien / Semantic Web),
– mit dynamischer Logik (Typ Begriffsmoleküle).
Siehe dazu den Beitrag ‹Die drei Neuerung der regelbasierte KI›.
B: Korpusbasierte Systeme
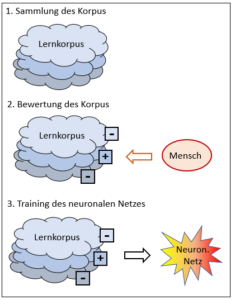
Korpusbasierte Systeme werden in drei Schritten erstellt (Abb. 4). Im ersten Schritt wird ein möglichst grosser Korpus gesammelt. Die Sammlung enthält keine Regeln, sondern Daten. Regeln wären Anweisungen, die Daten des Korpus hingegen sind keine Anweisungen; es handelt sich um reine Datensammlungen, Texte, Bilder, Spielverläufe, etc.
Abb. 4: Erstellen eines korpusbasierten Systems
Diese Daten müssen nun – im zweiten Schritt – bewertet werden. In der Regel macht das ein Mensch.
Im dritten Schritt wird ein sogenanntes neuronales Netz auf Basis des bewerteten Korpus trainiert. Das neuronale Netz ist im Gegensatz zum Datenkorpus wieder eine Regelsammlung, wie es die Wissensbasis der regelbasierten Systeme (Typ A) ist. Im Unterschied zu diesen wird das neuronale Netz aber nicht von einem Menschen trainiert, sondern vom bewerteten Korpus. Das neuronale Netz ist – im Gegensatz zur Wissensbasis – nicht explizit, d.h. nicht so ohne Weiteres einsehbar.
Abb. 5: Anwenden eines korpusbasierten Systems
Bei der Anwendung kommt das neuronale Netz wie das regelbasierte nun ganz ohne Menschen aus. Es braucht nicht einmal mehr den Korpus. Alles Wissen steckt in den Algorithmen des neuronalen Netzes. Zudem ist das neuronale Netz durchaus in der Lage, auch schlecht strukturierten Inhalt, z.B. Pixelhaufen (Bilder) zu interpretieren, bei denen regelbasierte Systeme (Typ B) ganz schnell an ihre Grenzen stossen. Im Gegensatz zu diesen sind die korpusbasierten Systeme aber weniger erfolgreich, was komplexen Output betrifft, d.h. die Zahl der möglichen Output-Resultate darf nicht zu gross sein, da sonst die Trefferschärfe des Systems leidet. Am besten geeignet sind binäre Outputs vom Typ ‹eigener/fremder Panzer› (siehe Vorbeitrag) oder ‹männlicher/weiblicher Autor› bei der Bewertung von Twitter-Texten.
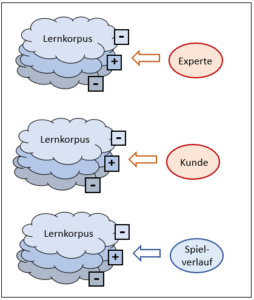
Drei Untertypen der korpusbasierten KI
Die drei Untertypen unterscheiden sich dadurch, wer die Bewertung des Korpus durchführt.
Abb. 6: Die drei Typen der korpusbasierten Systeme
B1: Typ Mustererkennung
Diesen Typ (oberes System in Abb. 6) habe ich im «Panzerbeispiel» beschrieben. Die Bewertung des Korpus erfolgt dabei durch einen menschlichen Experten.
B2: Typ Suchmaschine
Siehe mittleres Schema in Abb. 6. Bei diesem Typ erfolgt die Bewertung des Korpus durch die Kunden. Ein solches System ist im Beitrag Suchmaschine beschrieben.
B3: Typ Deep Learning
Bei diesem Typ (unterstes System in Abb. 6) ist im Gegensatz zu den oberen kein Mensch nötig, um das neuronale Netz zu bewerten. Die Bewertung ergibt sich allein durch den Spielverlauf. Dass Deep Learning aber nur unter sehr restriktiven Bedingungen möglich ist, wird im Beitrag Spiele und Intelligenz erläutert.
C: Hybride Systeme
Selbstverständlich können die oben genannten Methoden (A1 und A2, B1 bis B3) in der Praxis auch verbunden werden.
So kann z.B. ein System zur Gesichtsidentifikation so funktionieren, dass ein korpusbasiertes System des Typs B1 in den Bildern einer Überwachungskamera Gesichter als solche erkennt und in den Gesichtern die entscheidenden Formen von Augen, Mund usw. Anschliessend errechnet ein regelbasiertes System des Typs A2 aus den von System B1 markierten Punkten die Grössenverhältnisse von Augen, Nasen, Mund etc., die ein individuelles Gesicht auszeichnen. Durch eine solche Kombination von korpus- und regelbasiertem System können auf den Bildern individuelle Gesichter erkannt werden. Der erste Schritt wäre für ein System A2 nicht möglich, der zweite Schritt für ein System B1 viel zu kompliziert und ungenau. Ein Hybrid macht es möglich.
Im Folgebeitrag beantworte ich die Frage, wo in all diesen Systemen nun die Intelligenz steckt. Aber vermutlich haben Sie die Antwort längst selbst erkannt.
In meinem ersten Beitrag zur KI habe ich die beiden bereits in den 90er-Jahren verwendeten, sehr unterschiedlichen KI-Methoden skizziert. Beide Methoden waren damals nicht in Hochform. Folgende Mängel standen ihnen im weg:
Bei der korpusbasierten waren es:
– Die Intransparenz der Schlussfolgerungs-Wege
– Die Notwendigkeit, einen sehr grossen und korrekten Lernkorpus aufzubauen.
Bei der regelbasierten waren es:
– Die Rigidität der mathematischen Logik
– Die Unschärfe unserer Wörter
– Die Notwendigkeit, sehr grosse Wissensbasen manuell aufzubauen
– Die Notwendigkeit, teure und seltene Fachexperten einzusetzen.
Was wurde seit den 90er-Jahren verbessert?
Wir haben den phänomenalen Aufschwung der korpusbasierten Technik erlebt; praktisch alles, was heute KI genannt wird, funktioniert über die korpusbasierte Methode und ist in der Tat sehr eindrücklich.
Im Gegensatz dazu waren die Hindernisse für die regelbasierte Methode – rigide Logik und vieldeutige Begriffe – nicht so leicht zu überwinden. Sie machten einen Paradigmenwechsel erforderlich, eine grundlegende Änderung der Denkweise: Weg von der Sicherheit der traditionellen Logik hin zu einem offenen System. Diesen Schritt wollten die akademischen Teams nicht gehen, weshalb die traditionelle regelbasierte Methode mehr oder weniger dort blieb, wo sie war. Die Hindernisse sind zwar nicht unüberwindlich, wie der Erfolg z.B. unserer Begriffsmoleküle zeigt, doch diese neue regelbasierte Methoden ist kaum bekannt.
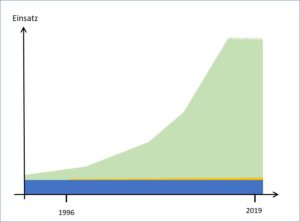
Verbreitung der KI-Methoden im Verlauf der Zeit
Abb 1: Schätzung der Verbreitung der KI-Methoden. Die Vertikalachse ist vertikal gestaucht, d.h. die Grössenverhältnisse sind noch drastischer als dargestellt. Die Kurve ist zudem oben abgeschnitten, da die exponentielle Zunahme der korpusbasierten Methode den Rahmen sprengen würde.
In Abb. 1 habe ich versucht darzustellen, wie sich der Einsatz der Methoden im Verlauf der Zeit verändert hat. Während die korpusbasierten Methoden (grün) ihre Verbreitung exponentiell gesteigert haben, sind die regelbasierten (blau) praktisch stationär geblieben. Die verbesserte regelbasierte Methode der Begriffsmoleküle (gelb) wird zur Zeit erst marginal eingesetzt.
Dies ist ein Beitrag zum Thema künstliche Intelligenz (KI). Aber ist der Name überhaupt korrekt? Sind diese Systeme wirklich intelligent? Schauen wir als erstes die regelbasierte Intelligenz an.
Haben die neuronalen Netze die regelbasierten Systeme abgehängt?
Es ist nicht zu übersehen: Die korpusbasierte KI hat die regelbasierte KI um Längen überholt. Neuronale Netze machen das Rennen, wohin man schaut. Schläft die Konkurrenz? Oder sind regelbasierte Systeme schlicht nicht in der Lage, gleichwertige Ergebnisse wie neuronale Netze zu erzielen?
Meine Antwort ist, dass die beiden Methoden aus Prinzip für sehr unterschiedliche Aufgaben prädisponiert sind. Ein Blick auf die jeweiligen Wirkweisen macht klar, wofür die beiden Methoden sinnvollerweise eingesetzt werden. Je nach Fragestellung ist die eine oder die andere im Vorteil.
Trotzdem bleibt das Bild: Die regelbasierte Variante scheint auf der Verliererspur. Woher kommt das?
In welcher Sackgasse steckt die regelbasierte KI?
Meines Erachtens hat das Hintertreffen der regelbasierten KI damit zu tun, dass sie ihre Altlasten nicht loswerden will. Dabei wäre es so einfach. Es geht darum:
Semantik als eigenständiges Wissensgebiet zu erkennen
Komplexe Begriffsarchitekturen zu verwenden
Eine offene und flexible Logik (NMR) einzubeziehen.
Wir tun dies seit über 20 Jahren mit Erfolg. Andernorts allerdings ist
die Notwendigkeit dieser drei Neuerungen und des damit verbundenen Paradigmenwechsels noch nicht angekommen.
Was bedeuten die drei Punkte nun im Detail?
Punkt 1: Semantik als eigenständiges Wissensgebiet erkennen
Üblicherweise ordnet man die Semantik der Linguistik zu. Dem wäre im Prinzip nichts entgegen zu halten, doch in der Linguistik lauert für die Semantik eine kaum bemerkte Falle: Linguistik beschäftigt sich mit Wörtern und Sätzen. Der Fehler entsteht dadurch, dass man die Bedeutung, d.h. die Semantik, durch den Filter der Sprache sieht und glaubt, ihre Elemente auf die gleiche Weise anordnen zu müssen, wie die Sprache das mit den Wörtern macht. Doch die Sprache unterliegt einer entscheidenden Einschränkung, sie ist linear, d.h. sequenziell: Ein Buchstabe kommt nach dem anderen, ein Wort nach dem anderen. Es ist nicht möglich, Wörter parallel nebeneinander zu setzen. Im Denken können wir das aber. Und wenn wir die Semantik von etwas untersuchen, geht es darum, wie wir denken und nicht, wie wir sprechen.
Wir müssen also Formalismen finden für die Begriffe, wie sie im Denken vorkommen. Die Beschränkung durch die lineare Anordnung der Elemente und die sich daraus ergebende Notwendigkeit, behelfsweise und in jeder Sprache anders mit grammatikalischen Kunstgriffen Klammerungen und komplexe Beziehungsstrukturen nachzubilden, diese Beschränkung gilt im Denken nicht und wir erhalten dadurch auf der semantischen Seite ganz andere Strukturen als auf der sprachlichen Seite.
Wort ≠ Begriff
Was sicher nicht funktioniert, ist eine simple «semantische Annotation» von Wörtern. Ein Wort kann viele, sehr unterschiedliche Bedeutungen haben. Eine Bedeutung (= ein Begriff) kann durch unterschiedliche Wörter ausgedrückt werden. Wenn man Texte analysieren will, darf man nicht die einzelnen Wörter, sondern muss immer den Gesamtkontext ansehen. Nehmen wir das Wort «Kopf». Wir sprechen z.B. vom Kopf eines Briefes oder vom Kopf eines Unternehmens. Wir können nun den Kontext in unseren Begriff hineinnehmen, indem wir den Begriff <Kopf< mit anderen Begriffen verbinden. So gibt es einen <Körperteil<Kopf< und eine <Funktion<Kopf<. Der Begriff links (<Körperteil<) sagt dann aus, von welchem Typ der Begriff rechts (<Kopf<) ist. Wir typisieren also. Wir suchen den semantischen Typ eines Begriffs und setzen ihn vor den Unterbegriff.
Konsequent komposite Datenelemente
Die Verwendung typisierter Begriffe ist nichts Neues. Wir gehen aber weiter und bilden ausgedehnte strukturierte Graphen, diese komplexen Graphen bilden dann die Basis unserer Arbeit. Das ist etwas ganz anderes als die Arbeit mit Wörtern. Die Begriffsmoleküle, die wir verwenden, sind solche Graphen, die eine ganz spezielle Struktur aufweisen, sodass sie sowohl für Menschen wie für Maschinen leicht und schnell lesbar sind. Die komposite Darstellung hat viele Vorteile, einer ist z.B. dass der kombinatorischen Explosion ganz einfach begegnet wird und so die Zahl der atomaren Begriffe und Regeln drastisch gekürzt werden kann. Durch die Typisierung und die Attribute können ähnliche Begriffe beliebig geschärft werden, wir können mit Molekülen dadurch sehr präzis «sprechen». Präzision und Transparenz der Repräsentation haben darüber hinaus viel damit zu tun, dass die spezielle Struktur der Graphen (Moleküle) direkt von der multifokalen Begriffsarchitektur abgeleitet ist (siehe im folgenden Punkt 2).
Punkt 2: Komplexe Begriffsarchitekturen verwenden
Begriffe sind in den Graphen (Begriffsmoleküle) über Relationen verbunden. Die oben genannte Typisierung ist eine solche Relation: Wenn der <Kopf< als ein <Körperteil< gesehen wird, dann ist er vom Typ <Körperteil< und es besteht eine ganz bestimmte Relation zwischen <Kopf< und <Körperteil<, nämlich eine sogenannte hierarchische oder ‹IS-A‹-Relation – letzteres darum, weil man bei hierarchischen Relationen immer ‹IST-EIN› sagen kann, also in unserem Fall: der <Kopf< ist ein <Körperteil<.
Die Typisierung ist eine der beiden grundlegenden Relationen in der Semantik. Wir ordnen eine Anzahl Begriffe einem übergeordneten Begriff, also ihrem Typ zu. Dieser Typ ist natürlich genauso ein Begriff und er kann deshalb selber wieder typisiert werden. Dadurch entstehen hierarchische Ketten von ‹IS-A›-Relationen, mit zunehmender Spezifizierung, z.B. <Gegenstand<Möbel<Tisch<Küchentisch<. Wenn wir alle Ketten der untergeordneten Begriffe, die von einem Typ ausgehen, zusammenbinden, erhalten wir einen Baum. Dieser Baum ist der einfachste der vier Architekturtypen für die Anordnung von Begriffen.
Von dieser Baumstruktur gehen wir aus, müssen aber erkennen, dass eine blosse Baumarchitektur entscheidende Nachteile hat, die es verunmöglichen, damit wirklich präzis greifende Semantiken zu bauen. Wer sich für die verbesserten und komplexerenArchitekturtypen und ihre Vor- und Nachteile interessiert, findet eine ausführliche Darstellung der vier Architekturtypen auf der Website von meditext.ch.
Bei den Begriffsmolekülen haben wir den gesamten Formalismus, d.h. die innere Struktur der Regeln und Moleküle selbst auf die komplexen Architekturen ausgerichtet. Das bietet viele Vorteile, denn die Begriffsmoleküle weisen jetzt in sich genau die gleiche Struktur auf wie die Achsen der multifokalen Begriffsarchitektur. Man kann die komplexen Faltungen der multifokalen Architektur als Gelände auffassen, mit den Dimensionen oder semantischen Freiheitsgraden als komplex verschachtelte Achsen. Die Begriffsmoleküle nun folgen diesen Achsen in ihrer eigenen inneren Struktur. Das macht das Rechnen mit den Molekülen so einfach. Mit simplen Hierarchiebäumen oder multidimensionalen Systemen würde das nicht funktionieren. Und ohne konsequent komposite Datenelemente, deren innere Struktur auf fast selbstverständliche Weise den Verzweigungen der komplexen Architektur folgt, auch nicht.
Punkt 3: Eine offene und flexible Logik (NMR) einbeziehen
Dieser Punkt ist für theoretisch vorbelastete Wissenschaftler möglicherweise der härteste. Denn die klassische Logik erscheint den meisten unverzichtbar und viele kluge Köpfe sind stolz auf ihre Kenntnisse darin. Klassische Logik ist in der Tat unverzichtbar – nur muss sie am richtigen Ort eingesetzt werden. Meine Erfahrung zeigt, dass wir im Bereich des NLP (Natural Language Processing) eine andere Logik brauchen, nämlich eine, die nicht monoton ist. Eine solche nichtmonotone Logik (NMR) erlaubt es, für das gleiche Resultat mit viel weniger Regeln in der Wissensbasis auszukommen. Die Wartung wird dadurch zusätzlich vereinfacht. Auch ist es möglich, das System ständig weiter zu entwickeln, weil es logisch offen bleibt. Ein logisch offenes System mag einen Mathematiker beunruhigen, die Erfahrung aber zeigt, dass ein NMR-System für die regelbasierte Erfassung des Sinns von frei formuliertem Text wesentlich besser funktioniert als ein monotones.
Fazit
Heute scheinen die regelbasierten Systeme im Vergleich zu den korpusbasierten im Hintertreffen zu sein. Dieser Eindruck täuscht aber und rührt daher, dass die meisten regelbasierten Systeme den Sprung in ein modernes System noch nicht vollzogen haben. Dadurch sind sie entweder:
nur für Aufgaben in kleinem und wohldefiniertem Fachgebiet anwendbar oder
sehr rigid und deshalb kaum einsetzbar oder
sie benötigen einen unrealistischen Ressourceneinsatz und werden unwartbar.
Wenn wir aber konsequent komposite Datenelemente und höhergradige Begriffsarchitekturen verwenden und bewusst darauf verzichten, monoton zu schliessen, kommen wir – für die entsprechenden Aufgaben – mit regelbasierten Systemen weiter als mit korpusbasierten.
Regelbasierte und korpusbasierte Systeme sind sehr unterschiedlich und je nach Aufgabe ist das eine oder das andere im Vorteil. Darauf werde ich in einem späteren Beitrag eingehen.
Dies ist ein Beitrag zum Thema künstliche Intelligenz (KI). Ein Folgebeitrag beschäftigt sich mit der aktuellen Verbreitung der beiden KI-Methoden.
Die Unterscheidung zwischen regelbasierter und korpusbasierter KI ist in mehrerer Hinsicht sinnvoll, denn die beiden Methoden funktionieren völlig unterschiedlich. Das bedeutet nicht nur, dass die Herausforderungen ganz andere sind, sondern in der Folge auch die Entwicklungsverläufe zeitlich nicht parallel erfolgen. Wenn heute von KI gesprochen wird, ist eigentlich nur die korpusbasierte gemeint, die regelbasierte scheint deutlich abgehängt zu sein.
Meines Erachtens hat das aber nur damit zu tun, dass die regelbasierte KI in eine Sackgasse gekommen ist, aus der sie erst herausfindet, wenn sie ihre spezifischen Herausforderungen richtig erkennt. Deshalb sollen hier die Herausforderungen genauer beschrieben werden.
Übersicht über die Herausforderungen
Im Vorbeitrag habe ich vier Herausforderungen an die regelbasierte KI genannt. Die ersten beiden lassen sich nicht grundsätzlich verbessern. Es braucht Experten für die Regelerstellung und die müssen sowohl Experten für abstrakte Logik wie auch Experten des jeweiligen Fachgebietes sein. Daran lässt sich nicht viel ändern. Auch die zweite Herausforderung bleibt bestehen, das Finden solcher Experten bleibt ein Problem.
Besser steht es um die Herausforderungen drei und vier, nämlich um die grosse Zahl der nötigen Regeln und ihre Komplexität. Obwohl gerade diese beiden Herausforderungen scheinbar unveränderliche Hürden von beträchtlicher Höhe darstellen, können sie mit den nötigen Erkenntnissen einiges an Schrecken verlieren. Allerdings müssen beide Herausforderungen konsequent angegangen werden, und das heisst, dass wir einige liebgewordenen Gewohnheiten und Denkmuster über Bord werfen müssen. Das sehen wir uns jetzt genauer an.
Für die Regeln braucht es einen Raum und einen Kalkulus
Regelbasierte KI besteht aus zwei Dingen:
den Regeln, die eine Domain (Fachgebiet) in einem bestimmten Format beschreiben und
einem Algorithmus, der bestimmt, wann welche Regeln ausgeführt werden.
Um die Regeln zu bauen, brauchen wir einen Raum, der festlegt, aus welchen Elementen die Regeln bestehen können und dadurch auch, was innerhalb des Systems überhaupt ausgesagt werden kann. Ein solcher Raum besteht nicht von selber, sondern muss bewusst gestaltet werden. Und zweitens brauchen wir ein Kalkulus, d.h. einen Algorithmus, der festlegt, wie die so gebauten Regeln angewendet werden. Selbstverständlich können sowohl der Raum als auch der Kalkulus ganz unterschiedlich angelegt sein, und diese Unterschiede «machen den Unterschied», d.h. sie erlauben eine entscheidende Verbesserung der regelbasierten KI, allerdings um den Preis, dass liebgewordene Gewohnheiten über Bord geworfen werden müssen.
Drei Neuerungen
In den 90er Jahren haben wir in unserem Projekt Semfinder deshalb in Beides investiert, sowohl in die grundlegende Gestaltung des Begriffsraums wie auch in den Kalkulus. Wir haben unser regelbasiertes System auf der Grundlage folgender drei Neuerungen erstellt:
Diese drei Neuerungen wirken zusammen und erlauben es , mit weniger Datenelementen und Regeln mehr Situationen präziser abzufangen. Durch die multifokale Architektur kann besser, d.h. situationsgerechter und detaillierter modelliert werden. Da gleichzeitig die Zahl der Elemente und Regeln abnimmt, verbessert sich die Übersicht und Wartbarkeit. Durch die drei Neuerungen gelingt es, die Grenzen zu sprengen, die regelbasierten Systemen bisher bezüglich Umfang, Präzision und Wartbarkeit gesetzt waren.
Dies ist ein Beitrag zum Thema künstliche Intelligenz (KI). Im Folgebeitrag werden wir untersuchen, wie die drei oben genannten Neuerungen wirken.
Die korpusbasierte KI (Typus «Panzer», siehe KI-Einstiegsbeitrag) konnte ihre Schwächen erfolgreich überwinden (siehe Vorbeitrag). Dafür reichte eine Kombination von «Brute Force» (verbesserte Hardware) und einem idealen Opportunitätsfenster, als nämlich während der superheissen Expansionsphase des Internets Firmen wie Google, Amazon, Facebook und viele andere grosse Datenmengen sammeln und damit ihre Datenkorpora füttern konnten. Und mit einem ausreichend grossen Datenkorpus steht und fällt die korpusbasierte KI.
für die regelbasierte KI aber reichte «Brute Force» nicht aus. Es nützte auch nichts, viele Daten zu sammeln, da für den Regelbau die Daten auch organisiert werden müssen – und zwar grossenteils von Hand, also durch menschliche Fachexperten.
Herausforderung 1: Unterschiedliche Mentalitäten
Nicht alle Menschen sind gleichermassen davon fasziniert, Algorithmen zu bauen. Es braucht dazu eine besondere Art Abstraktionsfähigkeit, gepaart mit einer sehr gewissenhaften Ader – jedenfalls was die Abstraktionen betrifft. Jeder noch so kleine Fehler im Regelbau wird sich unweigerlich auswirken. Mathematiker verfügen sehr ausgeprägt über diese hier gefragte konsequent-gewissenhafte Mentalität, aber auch Naturwissenschaftler und Ingenieure zeichnen sich vorteilhaft dadurch aus. Natürlich müssen auch Buchhalter gewissenhaft sein, für den Regelbau der KI ist aber zusätzlich noch Kreativität gefragt.
Verkäufer, Künstler und Ärzte hingegen arbeiten in anderen Bereichen. Oft ist Abstraktion eher nebensächlich, und das Konkrete ist wichtig. Auch das Einfühlungsvermögen in andere Menschen kann sehr wichtig sein. Oder man muss schnell und präzis handeln können, z.B. als Chirurg. Diese Eigenschaften sind alle sehr wertvoll, für den Algorithmenbau aber weniger wichtig.
Das ist für die regelbasierte KI ein Problem. Denn für den Regelbau braucht es sowohl die Fähigkeiten des einen und als auch das Wissen des anderen Lagers: Es braucht die Mentalität, die einen guten Algorithmiker ausmacht, gepaart mit der Denkweise und dem Wissen des Fachgebiets, auf das sich die Regeln beziehen. Eine solche Kombination des Fachgebietswissens mit dem Talent zur Abstraktion ist selten zu finden. In den Krankenhäusern, in denen ich gearbeitet habe, waren die beiden Kulturen in ihrer Getrenntheit ganz klar ersichtlich. Hier die Ärzte, die Computer höchstens für die Rechnungsstellung oder für gewisse teure technische Apparate akzeptierten, die Informatik allgemein aber gering schätzten, und dort die Informatiker, die keine Ahnung davon hatten, was die Ärzte taten und wovon sie überhaupt sprachen. Die beiden Lager gingen sich meist einfach aus dem Weg. Selbstverständlich war es da nihct verwunderlich, dass die für die Medizin gebauten Expertensysteme meist nur für ganz kleine Teilgebiete funktionierten, wenn sie nicht im blossen Experimentierstadium verharrten.
Herausforderung 2: Wo finde ich die Experten?
Experten, die kreativ und in den beiden Mentalitätslagern gleichermassen zuhause sind, sind selbstverständlich schwer zu finden. Erschwerend kommt hinzu: Es gibt kaum Ausbildungsstätten für diese Art Experten. Realistisch sind auch folgende Fragen: Wo sind die Ausbildner, die sich mit den aktuellen Herausforderungen auskennen? Welche Diplome gelten wofür? Und wie evaluiert ein Geldgeber auf diesem neuen Gebiet, ob die eingesetzten Experten taugen und die Projektrichtung stimmt?
Herausforderung 3: Schiere Menge an nötigen Detailregeln
Dass eine grosse Menge an Detailwissen nötig ist, um in einer Realsituation sinnvolle Schlüsse zu ziehen, war schon für die korpusbasierte KI eine Herausforderung. Denn erst mit wirklich grossen Korpora, d.h. dank des Internets und gesteigerter Computerleistung gelang es ihr, die riesige Menge an Detailwissen zu erfassen, das für jedes realistische Expertensystem eine der Basisvoraussetzungen ist.
Für die regelbasierte KI ist es aber besonders schwierig, die grosse Wissensmenge bereitzustellen, denn sie braucht für die Wissenserstellung Menschen, welche die grosse Wissensmenge von Hand in computergängige Regeln fassen. Das ist eine sehr zeitraubende Arbeit, die zudem die schwierig zu findenden menschlichen Fachexperten erfordert, die den oben genannten Herausforderungen 1 und 2 genügen.
In dieser Situation stellt sich die Frage, wie grössere und funktionierende Regelsysteme überhaupt gebaut werden können? Gibt es eventuell Möglichkeiten, den Bau der Regelsysteme zu vereinfachen?
Herausforderung 4: Komplexität
Wer je versucht hat, ein Fachgebiet wirklich mit Regeln zu unterfüttern, merkt, dass er schnell an komplexe Fragen stösst, für die er in der Literatur keine Lösungen findet. In meinem Gebiet des Natural Language Processing (NLP) ist das offensichtlich. Die Komplexität ist hier nicht zu übersehen. Deshalb muss unbedingt auf sie eingegangen werden. Mit anderen Worten: Das Prinzip Hoffnung reicht nicht, sondern die Komplexität muss thematisiert und intensiv studiert werden.
Was Komplexität bedeutet, und wie man ihr begegnen kann, darauf möchte ich in einem weiteren Beitrag eingehen. Selbstverständlich darf dabei die Komplexität nicht zu einer übermässigen Regelvermehrung führen (siehe Herausforderung 3). Die Frage, die sich für die regelbasierte KI stellt, ist deshalb: Wie kann ein Regelsystem gebaut werden, das Detailhaltigkeit und Komplexität berücksichtigt, dabei aber einfach und übersichtlich bleibt?
Die gute Botschaft ist: Auf diese Frage gibt es durchaus Antworten.
Die in den Vorbeiträgen erwähnten beiden KI-Varianten sind auch heute noch aktuell, und beide haben bemerkenswerte Erfolge zu verbuchen. Sie unterscheiden sich nicht zuletzt darin, wo genau bei ihnen die Intelligenz sitzt. Schauen wir zuerst das regelbasierte System an:
Aufbau eines regelbasierten Systems
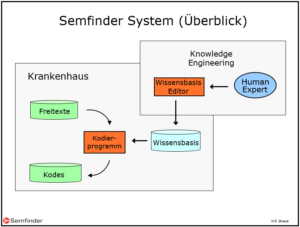
Bei der Firma Semfinder verwendeten wir ein regelbasiertes System. Ich zeichnete 1999 dafür folgende Skizze:
Grün: Daten Braun: Software Hellblau: Knowledge Ware Dunkelblau: Knowledge Engineer
Die Skizze besteht aus zwei Rechtecken, die zwei verschiedene Orte bezeichnen. Das Rechteck links unten zeigt, was im Krankenhaus geschieht, das Rechteck rechts oben, was zusätzlich im Knowledge Engineering abläuft.
Im Krankenhaus liest unser Kodierprogramm die Freitexteder Ärzte, interpretiert sie zu Begriffsmolekülen und weist diesen mit Hilfe einer Wissensbasis die entsprechenden Kodes zu. Die Wissensbasis enthält die Regeln, mit denen die Texte interpretiert werden. Diese Regeln werden bei uns in der Entwicklerfirma von Menschen (Human Experts) erstellt. Die Regeln sind vergleichbar mit den Algorithmen eines Software-Programms, nur dass sie in einer «höheren» Programmiersprache geschrieben sind, sodass auch Nicht-Informatiker, nämlich die Domain-Experten, die in unserem Fall Ärzte sind, sie einfach bauen und sicher warten können. Dazu verwenden sie den Wissensbasis-Editor, eine weitere Software, welche es erlaubt, die Regeln zu sichten, zu testen, zu modifizieren oder auch ganz neu zu bauen.
Wo sitzt nun die Intelligenz?
Sie steckt in der Wissensbasis. Aber es handelt sich nicht um wirkliche Intelligenz. Die Wissensbasis kann nicht selbstständig denken, sie führt nur aus, was ein Mensch ihr vorgegeben hat. Ich habe deshalb unser System nie als ein intelligentes bezeichnet. Intelligenz bedeutet im mindesten, dass man neue Dinge lernen kann. Die Wissensbasis lernt aber nichts. Wenn ein neues Wort auftaucht oder ein neuer Aspekt der Kodierung eingebaut wird, dann macht dies nicht die Wissensbasis, sondern der Knowledge Engineerjj, also der Mensch. Der Rest (Hardware, Software, Wissensbasis) führt nur aus, was der Mensch vorgibt. Die Intelligenz in unserem System war immer und ausschliesslich Sache der Menschen – also eine natürliche und keine künstliche.
Ist das bei der korpusbasierten Methode anders? Im Folgebeitrag schauen wir dazu ein solches korpusbasiertes System genauer an.
KI ist heute ein grosses Schlagwort, war aber bereits in den 80er und 90er Jahren des letzten Jahrhunderts ein Thema, das für mich auf meinem Gebiet des Natural Language Processing interessant war. Es gab damals zwei Methoden, die gelegentlich als KI bezeichnet wurden und die unterschiedlicher nicht hätten sein können. Das Spannende daran ist, dass diese beiden unterschiedlichen Methoden heute noch existieren und sich weiterhin essenziell voneinander unterscheiden.
KI-1: Schnaps
Die erste, d.h. die Methode, die bereits die allerersten Computerpioniere verwendeten, war eine rein algorithmische, d.h. eine regelbasierte. Beispielhaft für diese Art Regelsysteme sind die Syllogismen des Aristoteles:
Prämisse 1: Alle Menschen sind sterblich.
Prämisse 2: Sokrates ist ein Mensch.
Schlussfolgerung: Sokrates ist sterblich.
Der Experte gibt Prämisse 1 und 2 ein, und das System zieht dann selbstständig die Schlussfolgerung. Solche Systeme lassen sich mathematisch untermauern. Mengenlehre und First-Order-Logic (Aussagelogik ersten Grades) gelten oft als sichere mathematische Grundlage. Theoretisch waren diese Systeme somit wasserdicht abgesichert. In der Praxis sah die Geschichte allerdings etwas anders aus. Probleme ergaben sich durch die Tatsache, dass auch die kleinsten Details in das Regelsystem aufgenommen werden mussten, da sonst das Gesamtsystem «abstürzte», d.h. total abstruse Schlüsse zog. Die Korrektur dieser Details nahm mit der Grösse des abgedeckten Wissens überproportional zu. Die Systeme funktionierten allenfalls für kleine Spezialgebiete, für die klare Regeln gefunden werden konnten, für ausgedehntere Gebiete wurden die Regelbasen aber zu gross und waren nicht mehr wartbar. Ein weiteres gravierendes Problem war die Unschärfe, die vielen Ausdrücken eigen ist, und die mit solchen hart-kodierten Systemen schwer in den Griff zu bekommen ist.
Diese Art KI geriet also zunehmend in die Kritik. Kolportiert wurde z.B. folgender Übersetzungsversuch: Ein NLP-Programm übersetzte Sätze vom Englischen ins Russische und wieder zurück, dabei ergab die Eingabe:
«Das Fleisch ist willig, aber der Geist ist schwach» die Übersetzung:
«Das Steak ist kräftig, aber der Schnaps ist lahm.»
Die Geschichte hat sich vermutlich nicht genau so zugetragen, aber das Beispiel zeigt die Schwierigkeiten, wenn man versucht, Sprache mit regelbasierten Systemen einzufangen. Die Anfangseuphorie, die seit den 50er Jahren mit dem «Elektronenhirn» und seiner «maschinellen Intelligenz» verbunden worden war, verblasste, der Ausdruck «Künstliche Intelligenz» wurde obsolet und durch den Ausdruck «Expertensystem» ersetzt, der weniger hochgestochen klang.
Später, d.h. um 2000, gewannen die Anhänger der regelbasierten KI allerdings wieder Auftrieb. Tim Berners-Lee, Pionier des WWW, lancierte zur besseren Benutzbarkeit des Internets die Initiative Semantic Web. Die Experten der regelbasierten KI, ausgebildet an den besten technischen Hochschulen der Welt, waren gern bereit, ihm dafür Wissensbasen zu bauen, die sie nun Ontologien nannten. Bei allem Respekt vor Berners-Lee und seinem Bestreben, Semantik ins Netz zu bringen, muss festgestellt werden, dass die Initiative Semantic Web nach bald 20 Jahren das Internet nicht wesentlich verändert hat. Meines Erachtens gibt es gute Gründe dafür: Die Methoden der klassischen mathematischen Logik sind zu rigid, die komplexen Vorgänge des Denkens nachzuvollziehen – mehr dazu in meinen anderen Beiträgen, insbesondere zur statischen und dynamischen Logik. Jedenfalls haben weder die klassischen regelbasierten Expertensysteme des 20. Jahrhunderts noch die Initiative «Semantic Web» die hoch gesteckten Erwartungen erfüllt.
KI-2: Panzer
In den 90er Jahren gab es aber durchaus auch schon Alternativen, die versuchten, die Schwächen der rigiden Aussagenlogik zu korrigieren. Dazu wurde das mathematische Instrumentarium erweitert.
Ein solcher Versuch war die Fuzzy Logic. Eine Aussage oder eine Schlussfolgerung war nun nicht mehr eindeutig wahr oder falsch, sondern der Wahrheitsgehalt konnte gewichtet werden. Neben Mengenlehre und Prädikatenlogik hielt nun auch die Wahrscheinlichkeitstheorie Einzug ins mathematische Instrumentarium der Expertensysteme. Doch einige Probleme blieben: Wieder musste genau und aufwendig beschrieben werden, welche Regeln gelten. Die Fuzzy Logic gehört also ebenfalls zur regelbasierten KI, wenn auch mit Wahrscheinlichkeiten versehen. Heute funktionieren solche Programme in kleinen, wohlabgegrenzten technischen Nischen perfekt, haben aber darüberhinaus keine Bedeutung.
Eine andere Alternative waren damals die Neuronalen Netze. Sie galten als interessant, allerdings wurden ihre praktischen Anwendungen eher etwas belächelt. Folgende Geschichte wurde dazu herum
gereicht:
Die amerikanische Armee – seit jeher ein wesentlicher Treiber der Computertechnologie – soll ein neuronales Netz zur Erkennung von eigenen und fremden Panzern gebaut haben. Ein neuronales Netz funktioniert so, dass die Schlussfolgerungen über mehrere Schichten von Folgerungen vom System selber gefunden werden. Der Mensch muss also keine Regeln mehr eingeben, diese werden vom System selber erstellt.
Wie kann das System das? Es braucht dazu einen Lernkorpus. Bei der Panzererkennung war das eine Serie von Fotos von amerikanischen und russischen Panzern. Für jedes Foto war also bekannt, ob amerikanisch oder russisch, und das System wurde nun so lange trainiert, bis es die geforderten Zuordnungen selbstständig erstellten konnte. Die Experten nahmen auf das Programm nur indirekt Einfluss, indem sie den Lernkorpus aufbauten; das Programm stellte die Folgerungen im neuronalen Netz selbstständig zusammen – ohne dass die Experten genau wussten, aus welchen Details das System mit welchen Regeln welche Schlüsse zog. Nur das Resultat musste natürlich stimmen. Wenn das System nun den Lernkorpus vollkommen integriert hatte, konnte man es testen, indem man ihm einen neuen Input zeigte, z.B. ein neues Panzerfoto, und es wurde erwartet, dass es mit den aus dem Lernkorpus gefundenen Regeln das neue Bild korrekt zuordnete. Die Zuordnung geschah, wie gesagt, selbständig durch das System, ohne dass der Experte weiteren Einfluss nahm und ohne dass er genau wusste, wie im konkreten Fall die Schlüsse gezogen wurden.
Das funktionierte, so wurde erzählt, bei dem Panzererkennungsprogramm perfekt. So viele Fotos dem Programm auch gezeigt wurden, stets erfolgte die korrekte Zuordnung. Die Experten konnten selber kaum glauben, dass sie wirklich ein Programm mit einer hundertprozentigen Erkennungsrate erstellt hatten. Wie konnte so etwas sein? Schliesslich fanden sie den Grund: Die Fotos der amerikanischen Panzer waren in Farbe, diejenigen der russischen schwarzweiss. Das Programm musste also nur die Farbe erkennen, die Silhouetten der Panzer waren irrelevant.
Regelbasiert versus korpusbasiert
Die beiden Anekdoten zeigen, welche Probleme damals auf die regelbasierte und die korpusbasierte KI warteten.
Bei der regelbasierten KI waren es:
– die Rigidität der mathematischen Logik
– die Unschärfe unserer Wörter
– die Notwendigkeit, sehr grosse Wissenbasen aufzubauen
– die Notwendigkeit, Fachexperten für die Wissensbasen einzusetzen
Bei der korpusbasierten KI waren es:
– die Intransparenz der Schlussfolgerungs-Wege
– die Notwendigkeit, einen sehr grossen und relevanten Lernkorpus aufzubauen
Ich hoffe, dass ich mit den beiden oben beschriebenen, zugegebenermassen etwas unfairen Beispielen den Charakter und die Wirkweise der beiden KI-Typen habe darstellen können, mitsamt den Schwächen, die die beiden Typen jeweils kennzeichnen.
Die Herausforderungen bestehen selbstverständlich weiterhin. In den folgenden Beiträgen werde ich darstellen, wie die beiden KI-Typen darauf reagiert haben und wo bei den beiden Systemen nun wirklich die Intelligenz sitzt. Als Erstes schauen wir die korpusbasierte KI an.