Zu dieser Website
Ich beschäftige mich beruflich mit Algorithmen und Semantik, also mit verschiedenen Aspekten unseres Umgangs mit Information.
Das Thema Information
Obwohl IT eine grosse praktische Bedeutung in unserer Gesellschaft hat, sind es nur ganz bestimmte Aspekte davon, die ausgiebig thematisiert werden. Informationen spielen in Technik und Wissenschaft eine grosse Rolle und können dort technisch-wissenschaftlich verarbeitet werden. Informationen spielen aber auch in ganz anderen Gebieten eine Rolle, z.B. in der Kunst und in der Philosophie. Welche Information ist z.B. in der Musik vorhanden. Was sagt die Philosophie zum Thema? Was die Sprache? Gibt es hier Verbindungen? Und wie sehen diese aus? Die Rolle von Information in Kunst und Geisteswissenschaften ist faszinierend und interessiert mich ganz besonders.
Auf dieser Website möchte ich grundsätzliche und verbindende Aspekte des Themas «Information» diskutieren. Im Hintergrund steht dabei mein Interesse an einer integralen Weltsicht. Meine These ist, dass alle diese Gebiete – Technik und Wissenschaft auf der einen und Kunst und Philosophie auf der anderen Seite – immer mit Information zu tun haben. Ein Generalist kann nicht alles gleichzeitig verstehen, aber er kann auf allen Gebieten das verstehen, was die Gebiete gemeinsam haben: ihren Umgang mit Information.
Dabei spielen gewisse Schlüsselbegriffe für mich eine wichtige Rolle:
Information und Künstliche Intelligenz
Die einen versprechen sich den entscheidenden Technologiesprung, die anderen fürchten, dass eine unfehlbare künstliche Intelligenz die Menschheit unterjochen könnte. Ich arbeite seit einem Vierteljahrhundert auf dem Gebiet wissensbasierter Systeme und wundere mich vor allem über eines: Dass wir diesen – zugegebenermassen sehr leistungsfähigen – Systemen überhaupt echte Intelligenz zubilligen.
Wo steckt denn die Intelligenz in der sogenannten KI wirklich? – Darüber schrieb ich eine Beitragsserie, welche die beiden grundsätzlichen Herangehensweisen an eine ‚künstliche‘ Intelligenz, die nämlich die regelbasierte und die korpusbasierte, vorstellt und ihre Unterschiede und Möglichkeiten beleuchtet.
Die Beitragsserie ist auch als Buch im ZIM-Verlag erschienen:
«Wie die Künstliche Intelligenz zur Intelligenz kommt»
Eine Übersicht über die Blogserie zur künstlichen Intelligenz finden Sie immer im Menu.
Drei-Welten-Theorie – mit Beispiel Tonleitern in der Musik
Zu diesen Überlegungen bin ich durch Roger Penrose inspiriert worden. Nach Sir Roger spielen für unsere Existenz drei auf den ersten Blick unabhängige Welten eine Rolle: die physikalische, die mathematisch und die subjektiv-mentale. Besonders spannend ist für mich dabei das Zusammenwirken der drei Welten, das ich mit Beispielen aus der Musiktheorie und von Ihnen selber nachvollziehbaren Experimenten erläutere.
Logodynamik
Viele denken, dass unsere abendländische Logik perfekt sei. Sie hat sich über viele Jahrhunderte um das Beweisen bemüht, angefangen von den Syllogismen des Aristoteles über die Gottesbeweisen der mittelalterlichen Scholastik bis hin zur First-Order-Logic der Mathematik in jüngerer Zeit. Diese Systeme sind trotz ihres reifen Entwicklungsgrades nicht ausreichend, um die dynamischen Prozesse des Denkens abzubilden.
Dies fängt bereits mit dem einfachen IF-THEN an, das in den Syllogismen und der First-Order-Logic aus Prinzip statisch ist. Eine dynamische Logik ist jedoch unabdingbar, um Denkprozesse präzis zu beschreiben.
Informationsreduktion
Für ein reales System – also einen Menschen oder eine reale logische Maschine (Computer) – ist es nicht möglich, die Gesamtheit der relevanten Umgebungsinformation zu speichern. Die Gesamtmenge der Information muss deshalb notwendigerweise reduziert werden. Informationsreduktion ist für reale Systeme nicht nur unvermeidlich, sondern ein typisches Charakteristikum, das alle alle reifen Informationssysteme auszeichnet, seien sie nun organisch (Biologie), technisch (KI) oder kulturell (Kunst und Gesellschaft).
Das Thema ‚Informationsreduktion‘ irritiert viele, doch wir befinden uns damit auf den Spuren von zwei bekannten Philosophen, nämlich Wilhelm von Ockham (Ockham’s Razor) und Sokrates (Ich weiss, dass ich nichts weiss).
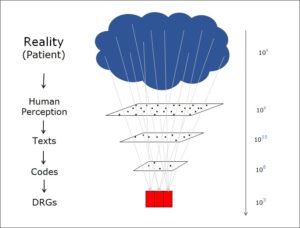
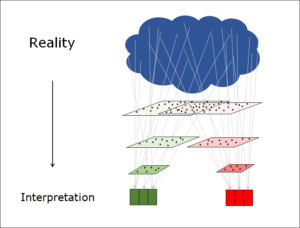
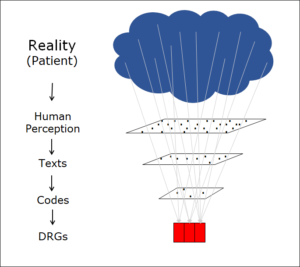
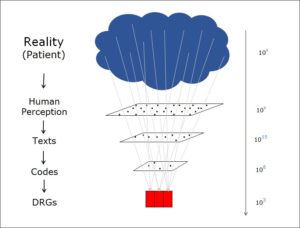
Interpretierendes System
Die Theorie des interpretierenden Systems beschreibt die Art und Weise, wie ein System in seinem Innenraum Signale von aussen interpretiert. Die Theorie hält fest, dass Informationsverarbeitung in der Realwelt immer innerhalb eines strukturierten Systems geschieht. Dieses System interpretiert die Informationen der Umgebung (Input) nach Regeln, die es in seinem Innenraum vorfindet. Natürlich muss das System dabei die Menge an Informationen, die es aus der Umgebung aufnimmt, immer wieder reduzieren und sich sinnvollerweise auf die Informationen, die für seine Ziele wichtig sind, konzentrieren. Diese Informationsreduktion ist ein aktiver Prozess innerhalb des interpretierenden Systems.
Buch: «Das Interpretierende System»
In den 90-er Jahren habe habe ich die Methode der Begriffsmoleküle entwickelt und sie anschliessend in einem Buch beschrieben. Begriffsmoleküle sind eine Methode, um Semantik formal darzustellen und Computerprogramme Freitexte interpretieren zu lassen. Aber auch wir Menschen interpretieren unsere Umwelt. Die Begriffsmoleküle versuchen, möglichst viel von diesem natürlichen Interpretationsvorgang in die formale Welt der Computer zu übertragen.
Das Buch besteht aus vier Teilen. Der erste beschreibt die Begriffsmoleküle, der zweite bringt eine Übersicht über einfache und komplexere Klassifikationssysteme (Begriffsarchitekturen), der dritte skizziert knapp die Vorgänge bei der semantischen Interpretation und der vierte und umfangreichste beschäftigt sich eingehend mit den Verhältnissen rund um das semiotische Dreieck.
Das Buch ist 2001 im ZIM-Verlag von Wolfram Fischer erschienen.
→ Mehr zum Buch
Semfinder AG
Hugo Mosimann und ich haben bei einem Lunch im Jahr 1997 beschlossen, eine Firma für semantische Expertensysteme zu gründen. Das Ziel war, die neue Methode der Begriffsmoleküle in einem NLP-Programm anzuwenden und als semantisches Interpretationsprogramm für die Kodierung von medizinischen Texten einzusetzen. Mit Maurus Duelli bekamen wir die kompetente unternehmerische Verstärkung, die es möglich machte, die Firma auch durch finanziell schwierige Zeiten zu steuern und unser Programm schliesslich in vielen hundert Krankenhäusern in Deutschland, der Schweiz, Österreich und Spanien einzusetzen. Im September 2016 haben wir das erfolgreiche Unternehmen an die Firma 3M übergeben, die den Standort, das Team und die Produkte weiterführt.
Danke
Bei der Gestaltung der Website hat mich Wolfram Fischer kompetent beraten und tatkräftig unterstützt!
Die englischen Übersetzungen stammen von Rachel Waddington, Tony Häfliger and Vivien Blandford.
Vielen Dank allen, die mir bei der Gestaltung der Website so gut geholfen haben!