Fortsetzung von Paradoxe Logikkerne (2)
Geschichte
Bevor wir die Konsequenzen der Distinction von Georg Spencer-Brown (GSB) auf Logik, Physik, Biologie und Philosophie ansehen, ist es hilfreich, sie mit einer anderen, viel bekannteren Grundform zu vergleichen, nämlich dem Bit. Das ermöglich uns, die Natur von GSB’s distinction und das Revolutionäre seiner Innovation besser zu verstehen.
Bits und Forms können beide als Basis-Bausteine für die Informationsverarbeitung angesehen werden. Software-Strukturen bauen technisch auf Bits auf, doch die Forms von GSB («draw a distinction») sind genauso einfach, grundlegend und dabei verblüffend ähnlich. Trotzdem gibt es charakteristische Unterschiede.
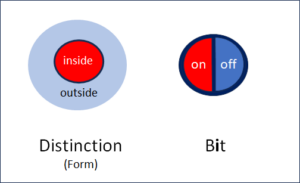
Abb. 1: Form und Bit zeigen Ähnlichkeit und Unterschiede
Sowohl Bit wie die Spencer-Brown Form sind in der Frühphase der Informatik entstanden, also relativ neue Vorstellung. Das Bit wurde von C.A. Shannon 1948 beschrieben, die Distinction von Georg Spencer-Brown (GSB) in seinem Buch «Laws of Form» im Jahr 1969, also nur ca. 20 Jahre später. 1969 fiel in die hohe Zeit der Hippie-Bewegung und GSB wurde in der Tat in Kaliforniens Hippie-Hochburg Esalen hoch willkommen geheissen. Das hat möglicherweise ein schlechtes Licht auf ihn geworfen und den etablierten Wissenschaftsbetrieb von ihm abgehalten. Während das Bit Kaliforniens entstehende Informations-High-Tech-Bewegung beflügelte, wurde Spencer-Browns mathematisch-logische Revolution von der Scientific Community geflissentlich ignoriert. Es ist Zeit, diesen Misstand zu überwinden.
Gemeinsamkeiten von Distinction und Bit
Beide, die Form und das Bit, beziehen sich auf Information. Beide sind elementare Abstraktionen und können deshalb als Grundbausteine von Information gesehen werden.
Diese Gemeinsamkeit zeigt sich darin, dass beide einen einzigen Aktionschritt bezeichnen – wenn auch einen unterschiedlichen – und beide dieser Aktion eine maximal reduzierte Anzahl von Ergebnissen zuordnen, nämlich genau zwei.
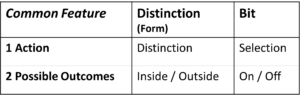
Tabelle 1: Sowohl Bit wie Distinction beinhalten
je eine Aktion und zwei mögliche Resultate (Outcomes)
Genau eine Aktion, genau zwei potentielle Ergebnisse
Die Aktion der Distinction ist die Distinction, also die Unterscheidung, die Aktion des Bits ist die Auswahl, also die Selection. Beide Aktionen sind als Informationshandlungen zu sehen und als solche fundamental, d.h. nicht weiter reduzierbar. Das Bit enthält in sich nicht weitere Bits, die Distinktion enthält in sich nicht weitere Distinktionen. Natürlich gibt es in der Umgebung des Bits weitere Bits und in der Umgebung einer Distinktion weitere Distinktionen. Beide Aktionen sind aber als fundamentale Informationshandlungen zu sehen. Ihre Fundamentalität wird unterstrichen durch die kleinst mögliche Zahl ihrer Ergebnisse, nämlich zwei. Die Zahl der Ergebnisse kann nicht kleiner sein, denn eine Unterscheidung von 1 ist keine Unterscheidung und eine Selektion aus 1 ist keine Selektion. Beides ist erst möglich, wenn es zwei potentielle Ergebnisse gibt.
Sowohl Distinction wie Bit sind somit unteilbare Informationshandlungen von radikaler, nicht zu steigernder Simplizität.
Trotzdem sind sie nicht gleich und auch nicht austauschbar. Sie ergänzen sich.
Während das Bit seit 1948 einen technischen Höhenflug angetreten ist, ist seine Voraussetzung, die Unterscheidung (distinction), ungenannt im Hintergrund geblieben. Umso mehr lohnt es sich, sie heute in den Vordergrund zu rücken und so ein neues Licht auf die Grundlagen von Mathematik, Logik, Natur- und Geisteswissenschaften zu werfen.
Unterschiede
Informationsgehalt und die Entropie nach Shannon
Beide, Form und Bit, beziehen sich auf Information. In der Physik wird der quantitative Gehalt an Information als Entropie bezeichnet.
Der Informationsgehalt, wenn ein Bit gesetzt, bzw. eine Unterscheidung getroffen wird, ist auf den ersten Blick in beiden Fällen gleich gross, nämlich die Information, die zwischen zwei Zuständen unterscheidet. Das ist beim Bit ganz klar so. Sein Informationsgehalt ist, wie Shannon gezeigt hat, log2(2) = 1. Shannon hat diesen dimensionslosen Wert als 1 Bit bezeichnet. Das Bit enthält somit – nicht ganz überraschend – die Information von einem Bit. So ist es von Shannon definiert worden.
Das Bit und die Entropie
Das Bit misst nichts anderes als die Entropie. Der Begriff Entropie stammt ursprünglich aus der Wärmelehre und dient dazu, das Verhalten von Wärmemaschinen zu berechnen. Entropie ist der Partnerbegriff der Energie und gilt – wie der Begriff Energie – überall in der Physik, nicht nur in der Wärmelehre.
Was ist Entropie?
Die Entropie misst also – seit Shannon – den Informationsgehalt. Wenn ich etwas nicht weiss und es anschliessend erfahre, fliesst Entropie als Information. Wenn – bevor ich weiss, was gilt – zwei Zustände möglich sind, dann erhalte ich, wenn ich erfahre, welcher der beiden Zustände zutrifft, eine Information mit dem quantitativen Wert 1 Bit.
Wenn mehr als zwei Zustände möglich sind, steigt die Zahl der Bits logarithmisch mit der Zahl der möglichen Zustände; so braucht es drei 2-er Wahlen um aus 8 Möglichkeiten die zutreffende herauszufinden, also genau drei Bits. Die Zahl der Wahlen (Bits) verhält sich zur Zahl der Auswahlmöglichkeiten wie das Beispiel zeigt, logarithmisch.
Zweierwahl = 1 Bit = log2(2).
Viererwahl = 2 Bit = log2(4)
Achterwahl = 3 Bit = log2(8)
Der Informationsgehalt eines einzigen Bits ist stets der Informationsgehalt einer einzigen Zweierwahl, also log2(2) = 1. Das Bit als physikalische Grösse ist dimensionslos, also eine reine Zahl. Das passt, weil die Information über die Wahl neutral ist, und nicht etwa eine Länge, ein Gewicht, eine Energie oder eine Temperatur. So viel zum Bit, der technischen Einheit der des quantitativen Informationsgehaltes. Wie verhält es sich nun bei der anderen Grundeinheit von Information, der Form von Spencer-Brown?
Der Informationsgehalt der Form
Der Informationsgehalt des Bits ist genau 1, wenn die beiden Outcomes der Selektion genau gleich wahrscheinlich sind. Sobald von zwei Zuständen einer unwahrscheinlicher ist, ist die Information grösser, wenn er, trotz der geringeren Vorwahrscheinlichkeit, gewählt wird. Je unwahrscheinlicher er ist, umso grösser wird die Information, wenn die Wahl auf ihn fällt. Nur beim klassischen Bit ist die Wahrscheinlichkeit für beide Zustände per Definition gleich gross.
Das ist ganz anders bei der Form der Unterscheidung von Spencer-Brown. Das Entscheidende dabei ist der ‚unmarked space‘. Die Distinktion unterscheidet etwas vom Rest und markiert es. Der Rest, also alles andere bleibt unmarkiert, Spencer-Brown nennt es den ‚unmarked space‘.
Wir können und müssen nun davon ausgehen, dass der Rest, das Unmarkierte, viel grösser ist, und die Wahrscheinlichkeit seines Eintretens viel grösser ist, als die Wahrscheinlichkeit, dass das Markierte eintrifft. Der Informationsgehalt des Markierten ist deshalb immer grösser als 1.
Natürlich geht es bei der Unterscheidung um das Markierte. Deshalb wird für den Informationsgehalt der Unterscheidung das Markierte und nicht das Unmarkierte gerechnet. Wie gross ist nun der Raum des Unmarkierten? Wir tun gut daran, davon ausgehen, dass er unendlich ist. Ich kann nie wissen, was ich alles nicht weiss.
Der Unterschied im Informationsgehalt, gemessen als Entropie, ist der erste Unterschied zwischen Bit und Unterscheidung. Beim Bit ist der Informationsgehalt, d.h. die Entropie genau 1, bei der Unterscheidung kommt es darauf an, wie gross der Unmarkierte Raum gesehen wird, er ist aber stets grösser als der markierte und die Entropie der Unterscheidung ist deshalb aus mathematischen Gründen stets grösser als 1.
Geschlossenheit und Offenheit
Die Abb. 1 oben zeigt den wichtigsten Unterschied von Distinktion und Bit, nämlich ihre Grenzen gegen aussen. Diese ist beim Bit klar definiert.
Die Bedeutungen im einem Bit
Das Bit enthält zwei Zustände, von denen einer aktiviert ist, der andere nicht. Ausser diesen beiden Zuständen ist nichts im Bit zu sehen und alle andere Information befindet sich ausserhalb des Bits. Nicht einmal die Bedeutungen der beiden Zustände sind definiert. Sie können 0 und 1, Wahr undd Falsch, Positiv und Negativ oder jedes andere Paar bedeuten, das sich gegenseitig ausschliesst. Das Bit selber enthält diese Bedeutungen nicht, nur die Information, welcher der beiden Zustände gewählt wurde. Die Bedeutung der beiden Zuständen wird ausserhalb des Bits geregelt und von ausserhalb zugewiesen. Diese Neutralität des Bits ist seine Stärke. Es kann jede Bedeutung annehmen und ist deshalb überall einsetzbar, wo Information technisch prozessiert wird.
Die Bedeutung in einer Unterscheidung
Ganz anders ist das bei der Unterscheidung. Hier wird die Bedeutung markiert. Dazu wird das Innere der Unterscheidung vom Äusseren unterschieden. Das Äussere aber ist offen und es gibt nichts, was nicht dazu gehört. Der ‚unmarked space‘ ist im Prinzip unendlich. Eine Grenze wird definiert, doch sie ist die Unterscheidung selber. Deshalb kann sich die Unterscheidung nicht wirklich gegen aussen abgrenzen, im Gegensatz zum Bit.
Mit anderen Worten:
→ Das Bit ist geschlossen, die Unterscheidung nicht.
Unterschiede zwischen Unterscheidung und Bit
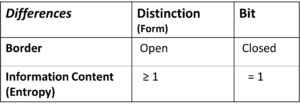
Tabelle 2: Unterschiede ziwschen Distinction (Form) und Bit
Die Unterschiede haben nun einige interessante Konsequenzen.
Konsequenzen
Bits und Offenheit in einer Software (Beispiel NLP)
Das Bit hat durch seine definierte und simple Entropie den technologischen Vorteil der einfachen Handhabbarkeit, was wir uns in der Software-Industrie zu Nutze machen. Die Forms hingegen sind durch ihre Offenheit realitätsgerechter. Für unsere konkrete Aufgabe der Interpretation von medizinischen Texten stiessen wir deshalb auf die Notwendigket, die Offenheit auch in der Bitwelt der technischen Software durch bestimmte Prinzipien einzuführen. Stichworte dazu sind:
- Einführung eines handelnden Subjekts, das den Input nach eigenen Internen Regeln bewertet,
- Arbeiten mit wechselnden Ontologien und Klassifikationen,
- Abkehr von der klassischen, d.h. statischen und monotonen Logik zu einer nicht-monotonen Logik,
- Integration der Zeit als Logikelement (nicht nur als Variable).
Mehr zum Thema Information -> Übersichtsseite Informationstheorie