Welche fünf Vorurteile teilen Sie?
- Entropie ist für Nerds
- Entropie ist unverständlich
- Entropie ist Wärmelehre
- Entropie ist Rauschen
- Entropie ist absolut
Korrekturen im Detail
1. Entropie ist die Grundlage unseres Alltags
Nerds interessieren sich gern für entlegene Themen. Da passt Entropie gut hinein, nicht wahr? Blutleere Nerds stellen sich damit als intellektuell überlegen dar. Dieses Spiel wollen Sie nicht mitmachen und Sie denken, dass es keinen wirklichen oder gar praktischen Grund gibt, sich mit Entropie zu beschäftigen. Diese Haltung ist sehr verbreitet und ziemlich falsch. Entropie ist kein nerdiges Thema, sondern bestimmt ganz grundlegend unser Leben, von der elementaren Physik bis in den praktischen Alltag hinein.
Beispiele (nach W. Salm1)
- Eine heisse Kaffeetasse kühlt sich mit der Zeit ab
- Wasser verdunstet in einem offenen Gefäss
- Angestossene Pendel bleiben nach einiger Zeit stehen
- Eisen rostet
- Magnete werden nach einigen Jahren schwächer
- Gelerntes wird vergessen
- Gekämmte Haare zerzausen sich
- Weisse Hemden werden fleckig
- Felsen zerbröckeln
- radioaktive Elemente zerfallen
Es gäbe also genug Grund, sich mit dem überall im Alltag anzutreffenden Phänomen Entropie zu beschäftigen. Doch die meisten Leuten machen einen Bogen um den Begriff. Weshalb? Das hat vor allem mit dem zweiten Vorurteil zu tun.
2. Entropie ist ein durchaus verständlicher und unverzichtbarer Grundbegriff
Entropie erscheint auf den ersten Blick ziemlich verwirrlich, doch schwierig zu verstehen ist Entropie nur wegen den hartnäckigen Vorurteilen 4 und 5. Diese beiden weit verbreiteten Vorurteile sind die Schwelle, die den Begriff Entropie unverständlich erscheinen lassen. Die Schwelle zu überwinden lohnt sich und hilft nicht nur, viele reale und praktische Phänomene zu verstehen, sondern wirf auch ein Licht auf die Grundlagen, welche unsere Welt zusammenhalten.
3. Entropie spielt überall in der Natur eine Rolle
Der Begriff Entropie zwar stammt aus der Wärmelehre. Doch davon sollten wir uns nicht täuschen lassen. In Wrklichkeit ist Entropie etwas, was es überall in der Physik, in der Chemie, der Biologie und auch in der Kunst, z.B. der Musik gibt. Es ist ein allgemeiner und abstrakter Begriff und er bezieht sich ganz direkt auf die Struktur von Dingen und auf die Information, die in ihnen steckt.
Historisch gesehen wurde der Begriff vor ca. 200 Jahren in der Wärmelehre eingeführt und mit der Möglchkeit, Wärme (Energie) fliessen zu lassen, verbunden. Er half, die Wirkweise von Maschinen (Otto-Motoren, Kühlschränke, Wärmepumpen, etc.) zu verstehen. So wird der Begriff heute noch an den Gymnasien unterrichtet.
Doch die Wärmelehre zeigt nur einen Ausschnitt von dem, was Entropie ist. Seine allgemeine Natur wurde erst 1948 von C.E. Shannon2 beschrieben. Die allgemeine Form von Entropie, auch als Shannon- oder Informationsentropie bezeichnet, ist die eigentliche, d.h. die grundsätzliche Form. Die Wärmeentropie ist ein Spezialfall.
Durch ihre Anwendung auf Wärmeflüsse In der Thermodynamik bekam die Entropie als Wärmeentropie eine konkrete physikalische Dimension, nämlich J/K, d.h. Energie/Temperatur. Doch das ist der Spezialfall Wärmelehre, in der es um Energien (Wärme) und Temperatur geht. Wenn die Entropie ganz allgemein und abstrakt verstanden wird, ist sie dimensionslos, eine reine Zahl.
Dieser Zahl hat Shannon als Entdecker der abstrakten und allgemeinen Informationsentropie einen Namen gegeben, das «Bit». Mit dem dimensionslosen Bit konnte Shannon als Ingenieur der Telefongesellschaft Bell den Informationsfluss in den Telefondrähten berechnen. Seine Informationsentropie ist dimensionslos und gilt nicht nur in der Wärmelehre, sondern überall, wo Information und Flüsse eine Rolle spielen.
4. Entropie ist die Differenz zwischen Nichtwissen und Wissen
Viele von uns haben in der Schule gelernt, dass Entropie ein Mass für das Rauschen und das Chaos ist. Der zweite Hauptsatz der Physik sagt uns zudem, dass Entropie stets nur zunehmen kann. Doch das Identifizieren von Entropie mit Rauschen oder gar Chaos ist irreführend.
Dabei gibt es gute Gründe dafür: Wenn ich einen Würfelzucker in den Kaffee werfe, löst sich seine wohldefinierte Kristallstruktur auf, die Moleküle verteilen sich ungeordnet in der Flüssigkeit und der Zucker zeigt einen Übergang von geordnet zu ungeordnet. Dieser Zerfall von Ordnung lässt sich überall in der Natur beobachten. Physikalisch gesehen ist es die Entropie, die gemäss dem zweiten Hauptsatz den Zerfall von Ordnung antreibt. Und Zerfall und Chaos sind wohl kaum mit Shannons Informationsbegriff gleichzusetzen. So dachten auch viele Wissenschaftler und setzten deshalb Information mit Negentropie (Entropie mit negativem Vorzeichen) gleich. Das passt auf den ersten Blick nicht schlecht. Entropie ist in dieser Sichtweise Rauschen und Abwesenheit von Rauschen, d.h. Negentropie, wäre dann die Information. Eigentlich logisch, nicht wahr?
Nicht ganz, denn Information steckt sowohl im Würfelzucker wie in den aufgelösten, im Kaffee schwimmenden Zuckermolekülen. In den einzel schwimmenden Molekülen steckt in gewisser Weise sogar mehr Information, weil sie sich unabhängig voneinander bewegen. Diese Bewegung ist Information. Das Problem ist unsere konventionelle Vorstellung von Information. Unsere Vorstellung ist zu statisch. Ich schlage vor, dass wir uns davon lösen und Entropie als etwas ansehen, was einen Fluss bezeichnet, nämlich den Fluss zwischen Nichtwissen und Wissen. Diese Dynamik ist kennzeichnend für das Lernen, für das Aufnehmen von neuer Information.
Jede Sekunde geschieht im Kosmos unglaublich vieles, was man wissen könnte. Die Information in der Gesamtwelt kann nur zunehmen. Das sagt auch der zweite Hauptsatz, und was zunimmt ist die Entropie, nicht die Negentropie. Wäre es da nicht viel naheliegender, Information mit Entropie und nicht mit Negentropie parallel zu setzen? Mehr Entropie würde dann mehr Information bedeuten und nicht mehr Chaos.
Wo steckt nun die Information? Im Rauschen oder in der Abwesenheit von Rauschen? In der Entropie oder in der Negentropie?
Zwei Levels
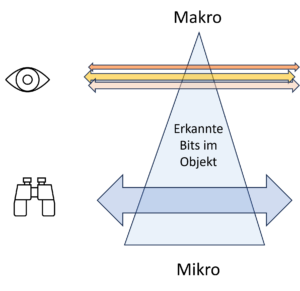
Nun, das Dilemma lässt sich lösen. Der entscheidende Schritt ist, zu akzeptieren, dass Entropie die Spannung zwischen zwei Zuständen ist, dem Übersichts- und dem Detailzustand. Der Übersichts-Blick benötigt die Details nicht, sondern sieht nur die grossen Linien. C.F. Weizsäcker spricht vom Makrolevel. Die grossen Linien sind die Informationen, die uns interessieren. Details hingegen erscheinen uns als unwichtiges Rauschen. In den Details, d.h. im Mikrolevel, steckt aber mehr Information, meist eine ganze Menge mehr, man nehme nur die Bewegungen der Wassermoleküle in der Kaffeetasse (Mikrolevel), in deren chaotischem Gewusel mehr Information steckt als in der einen Angabe der Temperatur des Kaffees (Makrolevel). Beide Levels sind verbunden und ihre Informationen hängen auf komplexe Weise voneinander ab. Die Entropie ist nun die Differenz zwischen den beiden Informationsmengen. Diese ist auf dem Detaillevel (Mikrolevel) stets grösser, denn es gibt in den Details stets mehr zu wissen als in den grossen Linien und deshalb auch mehr Information
Weil die beiden Level sich aber auf das gleiche Objekt beziehen, kann ich als Beobachter die Details oder das grosse Ganze anschauen. Beides gehört zusammen. Der Informationsgewinn an Details bezeichnet den Übergang vom Makro- zum Mikrolevel, der Informationsgewinn an Übersicht die umgekehrte Richtung.
Wo liegt nun die wirkliche Information? Auf dem Detaillevel, wo ganz viele Details beschreibbar sind, oder auf dem Übersichtslevel, wo die Informationen so zusammengefasst und so vereinfacht sind, wie sie uns wirklich interesseren?
Die Antwort ist einfach: Information enthält beides, sowohl das Makro- wie das Mikrolevel. Die Entropie ist der Übergang zwischen den beiden Levels und je nachdem, was uns interessiert, können wir den Übergang der Blickrichtung in die eine oder in die andere Richtung vornehmen.
Beispiel Kaffeetasse
Klassisch zeigt sich das in der Wärmelehre. Die Temperatur meines Kaffees kann gesehen werden als Mass für die durchschnittliche Bewegungsenergie der einzelnen Flüssigkeitsmoleküle in der Kaffeetasse. Die Information, die in den vielen Molekülen steckt ist der Mikrozustand, die Temperatur der Makrozustand. Entropie ist das Wissen, das im Makrozustand fehlt, im Mikrozustand aber vorhanden ist. Aber für mich als Kaffeetrinker ist nur das Wissens des Makrozustandes, der Temperatur des Kaffees, relevant. Dieses ist im Mikrozustand insofern nicht vorhanden, als es nicht an einem einzelnen Molekül hängt, sondern statistisch an der Gesamtheit aller Moleküle. Erst im Makrozustand wird das Wissen über die Temperatur erfahrbar.
Für uns zeigt nur der Makrozustand eine relevante Information. Doch auch im Rauschen steckt Information. Wie genau sich die Moleküle bewegen, ist ganz klar eine Menge an Information, doch diese Details spielen für mich keine Rolle, wenn ich Kaffee trinke, nur ihre durchschnittliche Geschwindigkeit macht die Temperatur des Kaffees aus, auf die es für mich ankommt.
Der informationsreichere und sich stetig ändernde Mikrozustand steht mit der einfachen Makroinformation der Temperatur aber in einer komplexen Beziehung. Auch der Makrozustand beeinflusst den Mikrozustand, nicht nur umgekehrt, denn die Moleküle müssen sich im statistischen Rahmen bewegen, den die Temperatur vorgibt. Beide Informationen hängen voneinander ab und sind gleichzeitig im Objekt objektiv vorhanden. Nur das Betrachtungslevel ist unterschiedlich. Die Differenz der Informationsmenge in der Beschreibung der beiden Levels bestimmt die Entropie und ist ein Mass für die Information.
Diese Verhältnisse sind spätestens seit Shannon2 und C.F. Weizsäcker bestens bekannt. In den Schulen wird aber meist noch gelehrt, dass Entropie ein Mass für Rauschen ist. Das ist falsch. Entropie ist immer als Delta zu verstehen, als einen Differenz (Abstand) zwischen der Information in der Übersicht (Makrozustand) und der Information in den Details (Mikrozustand).
5. Entropie ist ein relativer Wert
Aus der Tatsache, dass Entropie immer ein Abstand, ein Delta, d.h. mathematisch eine Differenz ist, folgt auch die Tatsache, dass Entropie kein absoluter, sondern stest ein relativer Wert ist.
Beispiel Kaffeetasse
Als Beispiel nehmen wir die Kaffeetasse. Wieviel Entropie steckt da drin? Wenn wir nur die Temperatur anschauen, dann entspricht der Mikrozustand der durchschnittlichen Bewegungsenergie der Moleküle. Doch die Kaffeetasse enthält noch mehr Information: Wie stark ist der Kaffee? Wie stark gesüsst? Wie stark ist die Säure? Welche Geschmacksnoten enthält er?
Beispiel Schulhaus
Salm1 bringt das Beispiel einer Haarspange, die eine Schülerin in der Schule sucht. Wenn ich weiss, in welchem Schulzimmer die Spange ist, habe ich sie dann schon gefunden? Der Mikrozustand benennt in diesem Moment nur das Zimmer. Wo im Zimmer liegt die Spange? Vielleicht in einem Gestell? In welchem? In welcher Höhe? In welcher Schublade, welchem Karton? Der Mikrozustand lässt sich variabel präzis einstellen.
Weil die Informationsentropie stets eine Differenz ist, ist die Entropie, d.h. die Spanne zwischen Übersicht und Details stets erweiterbar auf noch mehr Details.
Die Entropie ist ein relativer Wert. Wenn wir sie absolut angeben, setzen wir – ohne das explizit zu deklarien – ein tiefstes Level (Klassenzimmer, Regal oder Schublade) fest. Das ist legal, solange wir uns bewusst sind, dass der scheinbar absolute Wert nur den Abstand zum angenommenen Mikrolevel darstellt.
Statik und Dynamik
Energie und Entropie sind zwei komplementäre Grössen, welche die ganze Naturbeschreibung (Physik, Chemie, Biologie) durchziehen. Die beiden Hauptsätze der Physik enthalten je einen der beiden allgemeinen Grössen E (Energie) und S (Entropie):
- Satz: ∆E = 0
- Satz: ∆S ≥ 0
Die Energie bleibt im Lauf der Zeit (im geschlossenen System) konstant, die Entropie kann nur zunehmen. Mit anderen Worten: Energie ist ein statischer Wert und zeigt, was sich nicht ändert, während Entropie essentiell dynamisch ist und Flüsse anzeigt, z.B. in den Wärmemaschinen, in Shannons Strom in Telefondrähten und immer dann, wenn unsere Gedanken fliessen und wir lernen und denken.
Entropie und Zeit
Entropie ist durch den zweiten Hauptsatz (∆S ≥ 0) essentiell mit dem Phänomen Zeit verbunden. Während die Energie im geschlossenen System konstant bleibt (Noethers Theorem), ändert sich in der Zeit die Entropie und nimmt im geschlossenen System zu. Entropie kennt also die Zeit, nicht nur die Wärmeentropie im Speziellen, sondern auch die viel allgemeinere Informationsentropie.
Fazit
- Entropie ist ein Schlüsselbegriff. Er verbindet Physik und Information.
- Entropie stammt aus der Wärmelehre, bezieht sich aber auf Information im Allgemeinen.
- Die Wärmeentropie ist der Spezialfall, die Informationsentropie ist der allgemeine Begriff.
- Alles, was physikalisch, chemisch und in der Informationsverarbeitung, ob technisch oder biologisch, geschieht, hat mit Entropie zu tun. Insbesondere alles, was mit Informationsflüssen und -strukturen zu tun hat. Mit anderen Worten: Alles, was uns wirklich interessiert.
- Entropie ist immer relativ und bezieht sich auf den Abstand zwischen dem Makro- und dem Mikrolevel.
- Das Makrolevel enthält weniger Information als das Mikrolevel
- Das Makrolevel enthält die Information, die interessiert.
- Beides ist nicht absolut: Das Mikrolevel kann immer noch detaillierter geschildert werden. Das Makrolevel wird von aussen definiert: Was interessiert? Die Temperatur des Kaffees? Die Konzentration der Zuckermoleküle? Die Säure? Der Koffeingehalt …
- Erst die Definition der beiden Zustände erlaubt es, die Entropie scheinbar absolut anzugeben. Doch was für die Entropie zählt, ist der relative Wert, das heisst das Delta zwischen den beiden Zuständen. Dieses Delta, die Entropie, bestimmt den Fluss.
- Der Fluss geschieht in der Zeit.
1 Salm, W: Entropie und Information – naturwissenschaftliche Schlüsselbegriffe, Aulis Verlag Deubner, Köln, 1997
2 Shannon, C.E. und Weaver W: The Mathematical Theory of Communication, Illinois Press, Chicago, 1949
Das ist ein Beitrag zum Thema Entropie. Siehe -> Übersichtsseite Entropie