Was ist wirkliche Intelligenz?
Paradoxerweise hilft uns der Erfolg der künstlichen Intelligenz, essenzielle Bedingungen für die echte Intelligenz zu erkennen. Wenn wir nämlich akzeptieren, dass die künstliche Intelligenz an Grenzen stösst und im Vergleich zur echten klar erkennbare Mängel aufweist – und genau das haben wir ja in den Vorbeiträgen erkannt und beschrieben –, dann zeigen uns die Beschreibungen nicht nur, was bei der künstlichen Intelligenz fehlt, sondern auch, was die echte Intelligenz der künstlichen voraus hat. Wir lernen also etwas ganz Entscheidendes zum Thema natürliche Intelligenz.
Was haben wir erkannt? Was sind die essentiellen Unterschiede? Meines Erachtens sind es zwei Eigenschaften, durch die sich echte Intelligenz gegenüber künstlicher auszeichnet:
Die echte Intelligenz
– funktioniert auch in offenen Systemen,
– zeichnet sich durch eine bewusste Absicht aus.
Schach und Go sind geschlossene Systeme
Im Beitrag ‚Jassen und Schach‘ haben wir das Paradox untersucht, dass das Jass-Spiel für uns Menschen weniger Intelligenz zu erfordern scheint als Schach, für künstliche Intelligenz ist es aber genau umgekehrt. Im Schach und GO schlägt uns der Computer, beim Jassen hingegen haben wir durchaus eine Chance.
Weshalb ist das so? – Der Grund liegt in der Geschlossenheit des Schachspiels. Die Geschlossenheit bedeutet, dass nichts geschieht, was nicht vorgesehen ist. Alle Spielregeln sind klar definiert. Die Zahl der Felder und der Figuren, die Anfangspositionen und Spielmöglichkeiten der Figuren, wer wann zieht und wer wann warum gewonnen hat; all dies ist eindeutig festgesetzt. Und alle Regeln sind explizit; was nicht definiert ist, spielt keine Rolle: Wie der König ausschaut? Egal, wichtig ist nur, dass es einen König gibt und dass er für den Sieg matt zu setzen ist, im Notfall reicht, um den König zu symbolisieren, ein Papierfetzchen mit einem ‚K‘ darauf.
Solche geschlossenen Systeme können mathematisch klar beschrieben werden, und sie sind deterministisch. Natürlich braucht es Intelligenz, um zu siegen, doch diese Intelligenz kann völlig mechanisch sein, eben eine künstliche Intelligenz.
Mustererkennung: Offenes oder geschlossenes System?
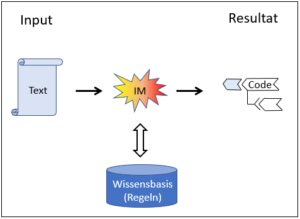
Anders sieht es beim Typus Mustererkennung aus, wenn z.B. auf Bildern bestimmte Gegenstände und ihre Eigenschaften erkannt werden müssen. Hier ist das System im Prinzip offen, denn es können nicht nur Bilder mit ganz neuen Eigenschaften von aussen eingebracht werden, sondern auch die entscheidenden Eigenschaften, die erkannt werden müssen, können variieren. Die Situation ist also nicht so einfach, klar definiert und geschlossen wie bei Schach und GO. Ist das nun ein geschlossenes System?
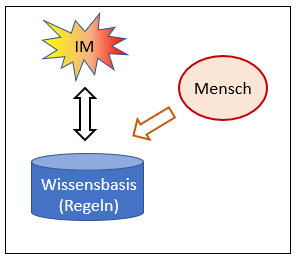
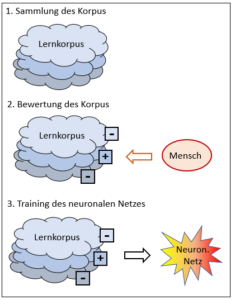
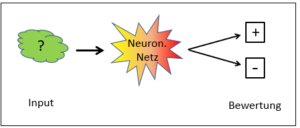
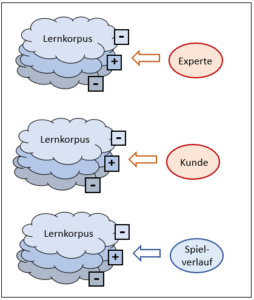
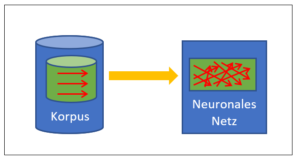
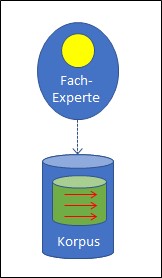
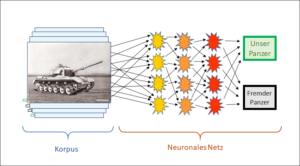
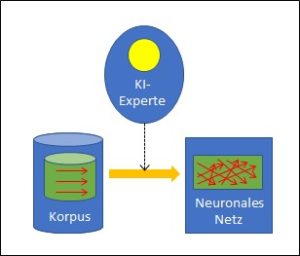
Nein, ist es nicht. Während bei Schach die Spielregeln einen abschliessenden Grenzzaun um die Möglichkeiten und Ziele legen, muss ein solcher Sicherheitszaun aktiv um die Mustererkennung gelegt werden. Der Zweck ist, dabei die Vielfalt der Muster in einer klaren Verteilung zu organisieren. Das können nur Menschen. Sie bewerten den Lernkorpus, der möglichst viele Musterbeispiele erfasst, und jedes Beispiel wird von den Experten entsprechend der gewünschten Unterscheidung zugeordnet. Dieser bewertete Lernkorpus nimmt dann die Rolle der Spielregeln des Schachs ein und er bestimmt, wie ein neuer Input bewertet wird. Mit anderen Worten: Der bewertete Lernkorpus enthält das relevante Wissen, d.h. die Regeln, nach denen ein bisher unbekannter Input bewertet wird. Er entspricht dem Regelwerk des Schachs.
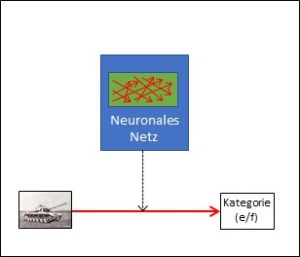
Das KI-System für eine Mustererkennung ist in diesem Sinn offen, wenn der Lernkorpus noch nicht einbezogen ist, mit dem bewerteten Korpus jedoch wird ein solches System ein geschlossenes. Genauso wie das Schachprogramm durch die Spielregeln klare Grenzen hat, bekommt auch die Mustererkennung ein klares Korsett, das letztlich das Outcome deterministisch definiert. Sobald die Bewertung erfolgt ist, kann eine rein mechanische Intelligenz das Verhalten innerhalb der getroffenen Grenzen optimieren – und dies letztlich in einem Perfektionsgrad, der mir als Mensch nie möglich sein wird.
Wer aber bestimmt den Inhalt des Lernkorpus, der das Mustererkennungsprogramm zu einem (technisch) geschlossenen System macht? Es sind immer menschliche Experten, die die Musterinputs bewerten. Der Mensch also macht die im Prinzip offene Aufgabe der Mustererkennung mittels des von ihm bewerteten Korpus zu einer geschlossenen Aufgabe, die ein mechanischer Algorithmus lösen kann.
In beiden Fällen – dem primär geschlossenen Spielprogramm (Schach und Go), wie auch dem sekundär geschlossenen Mustererkennungsprogramm – findet der Algorithmus eine geschlossene Situation vor; und das ist die Voraussetzung dafür, dass eine künstliche, d.h. mechanische Intelligenz überhaupt funktionieren kann.
Fazit 1:
Die KI-Algorithmen können nur in geschlossenen Räumen arbeiten.
Bei der Mustererkennung liefert der von Menschen geschaffene Lernkorpus diesen geschlossenen Raum.
Fazit 2:
Echte Intelligenz funktioniert auch in offenen Situationen.
Gibt es Intelligenz ohne Absicht?
Warum kann die künstliche Intelligenz im offenen Raum ohne Bewertungen von aussen nicht funktionieren? Weil die Bewertungen von aussen erst die Resultate der künstlichen Intelligenz ermöglichen. Und die Bewertungen können nicht mechanisch (algorithmisch) von der KI gegeben werden, sondern haben stets mit den An- und Absichten der Bewerter zu tun.
Neben der Unterscheidung zwischen offenen und geschlossenen Systemen, kann uns die Analyse von KI-Systemen somit noch mehr über die wirkliche Intelligenz zeigen. Künstliche und natürliche Intelligenz unterscheiden sich nämlich auch darin, wie weit bei ihnen für ihre Entscheidungen die jeweilige Absicht eine Rolle spielt.
Bei Schachprogrammen ist das Ziel klar, der gegnerische König soll schachmatt gesetzt werden. Das Ziel, das die Bewertung der Züge bestimmt, nämlich die Absicht zu siegen, muss nicht vom Programm selber mühsam erkannt werden, sondern ist von vornherein gegeben.
Auch bei der Mustererkennung ist die Rolle der Bewertungsabsicht entscheidend, denn welche Arten von Mustern sollen überhaupt unterschieden werden? Fremde Panzer versus eigene Panzer? Radpanzer versus Kettenpanzer? Funktionsfähige versus defekte? Alle diese Unterscheidungen machen Sinn, die KI muss aber anhand des Korpus auf ein bestimmtes Ziel, auf eine bestimmte Absicht eingestellt und justiert werden. Ist der Korpus einmal in einer bestimmten Richtung bewertet, kann nicht plötzlich ein anderes Merkmal daraus abgeleitet werden.
Wie beim Schachprogramm ist die künstliche Intelligenz nicht imstande, das Ziel selbständig herauszufinden, beim Schachprogramm versteht sich das Ziel (Schachmatt) von selber, bei der Mustererkennung müssen sich die beteiligten Bewerter über das Ziel (fremde/eigene, Rad-/Kettenpanzer) vorgängig einig sein. In beiden Fällen kommen Ziel und Absicht von aussen.
Natürliche Intelligenz hingegen kann sich selber darüber klar werden, was wichtig und was unwichtig ist und welche Ziele sie verfolgt. Die aktive Absicht ist m.E. eine unverzichtbare Eigenschaft der natürlichen Intelligenz und kann nicht künstlich konstruiert werden.
Fazit 3:
Im Gegensatz zur künstlichen zeichnet sich die natürliche Intelligenz dadurch aus, dass sie die eigenen Absichten beurteilen und bewusst ausrichten kann.
Dies ist ein Beitrag zum Thema künstliche Intelligenz. Weitere Beiträge finden Sie über die Übersichtsseite zum Thema KI.