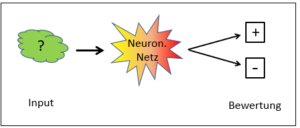
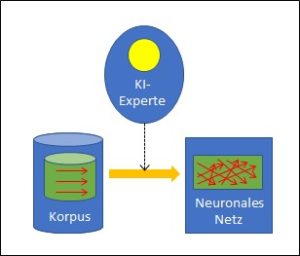
Die Möglichkeiten der neuronalen Netze sind beschränkt
Der unbezweifelbare Erfolg der neuronalen Netze lässt ihre Schwächen in den Hintergrund treten. Als korpusbasierte Systeme sind neuronale Netze völlig von der vorgängig erfolgten Datensammlung, dem Korpus abhängig. Prinzipiell kann nur die Information, die auch im Korpus steckt, vom neuronalen Netz überhaupt gesehen werden. Zudem muss der Korpus bewertet werden, was durch menschliche Experten erfolgt.
Was nicht im Korpus steckt, befindet sich ausserhalb des Horizonts des neuronalen Netzes. Fehler im Korpus oder in seiner Bewertung führen zu Fehlern im neuronalen Netz:
Intransparenz
Welche Datensätze im Korpus zu welchen Schlüssen im neuronalen Netz führen, lässt sich im Nachhinein nicht rekonstruieren. Somit können Fehler im neuronalen Netz nur mit beträchtlichem Aufwand korrigiert werden. Andererseits ist es auch nicht nötig, die Schlussfolgerungen wirklich zu verstehen. So kann ein neuronales Netz ein Lächeln auf einem fotografierten Gesicht sehr gut erkennen, obwohl wir nicht bewusst angeben können, welche Pixelkombinationen nun genau für das Lächeln verantwortlich sind.
Kleiner Differenzierungsgrad
Wie viele Ergebnismöglichkeiten (Outcomes) kann ein neuronales Netz unterscheiden? Jedes mögliche Ergebnis muss in der Lernphase einzeln geschult und abgegrenzt werden. Dafür müssen genügend Fälle im Korpus vorhanden sein. Der Aufwand bezüglich Korpusgrösse steigt dabei nicht proportional, sondern exponentiell. Dies führt dazu, dass Fragen mit wenig Ergebnismöglichkeiten von neuronalen Netzen sehr gut, solche mit vielen unterschiedlichen Antworten nur mit überproportionalem Aufwand gelöst werden können.
Am besten eignen sich deshalb binäre Antworten, z. B. Ist der Twittertext von einer Frau oder einem Mann geschrieben? Zuweisungen mit vielen Outcome-Möglichkeiten hingegen eignen sich schlecht.
(Fortsetzung folgt)
Dies ist Teil 2 aus dem Nachwort des Buches ‹Wie die künstliche Intelligenz zur Intelligenz kommt›. –> zum Buch
Alle bis jetzt untersuchten Systeme, inkl. Deep Learning, lassen sich in ihrem Kern auf zwei Methoden zurückführen, die regel- und die korpusbasierte. Dies gilt auch für die bisher nicht besprochenen Systeme, nämlich den einfachen Automaten und die hybriden Systeme. Letztere kombinieren die beiden Herangehensweisen.
Wenn wir diese Varianten integrieren, gelangen wir zur folgenden Übersicht:
A: Regelbasierte Systeme
Regelbasierte Systeme basieren auf Rechenregeln. Bei diesen Regeln handelt es sich immer um ‚IF-THEN‘ Befehle, also um Anweisungen, die einem bestimmten Input ein bestimmtes Ergebnis zuweisen. Diese Systeme sind immer deterministisch, d.h. ein bestimmter Input führt immer zum gleichen Resultat. Ebenfalls sind diese Systeme immer explizit, d.h. es gibt keine Vorgänge, die nicht sichtbar gemacht werden können und das System ist – mindestens im Prinzip – immer vollständig durchschaubar. Regelbasierte Systeme können allerdings recht komplex werden.
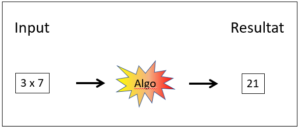
A1: Einfacher Automat (Typ Taschenrechner)
Abb. 1: Einfacher Automat
Regeln werden auch als Algorithmen («Algo» in Abb. 1) bezeichnet. Selbstverständlich können mit einfachen Automaten auch sehr komplexe Berechnungen durchgeführt werden und Input und Output (Resultat) müssen nicht Zahlen sein. Der einfache Automat zeichnet sich vor den anderen Systemen dadurch aus, dass er keine spezielle Wissensbasis und keinen Korpus braucht, sondern mit wenigen Rechenregeln auskommt.
Vielleicht würden Sie den Taschenrechner nicht als KI-System bezeichnen, doch die Unterschiede zu den höher entwickelten Systemen bis hin zum Deep Learning sind nur gradueller Natur – bzw. von genau der Art, wie sie hier auf dieser Seite beschrieben werden. Komplexe Rechenleistungen erscheinen uns schnell einmal als intelligent, besonders dann, wenn wir sie mit unseren menschlichen Gehirnen nicht so einfach nachvollziehen können. Das gilt bereits für einfache Rechenoperationen wie Divisionen und Wurzelziehen, bei denen wir schnell an unsere Grenzen stossen. Gesichtserkennung erscheint uns hingegen vergleichsweise einfach, weil wir das meist auch ohne Computer ganz gut können. Übrigens gehört Mühlespielen auch in die Kategorie A1, es braucht zwar eine gewisse Intelligenz, um es zu spielen, aber es ist vollständig und einfach mit einem KI-Programm vom Typ A1 beherrschbar.
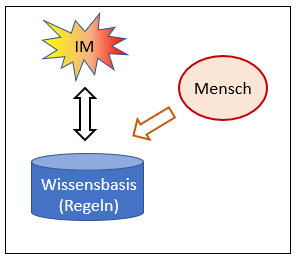
A2: Wissensbasiertes System
Abb. 2: Erstellen einer Wissensbasis
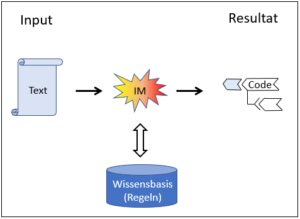
Diese Systeme unterscheiden sich von einfachen Automaten dadurch, dass ein Teil ihrer Regeln in einer Wissensbasis ausgelagert ist. Abb. 2 weist darauf hin, dass diese Wissensbasis von einem Menschen aufgebaut wird; Abb. 3 zeigt, wie sie angewendet wird. Die Intelligenz steckt in den Regeln, sie kommt vom Menschen – bei der Anwendung reicht dann die Wissensbasis allein.
Abb. 3: Anwenden eines wissensbasierten Systems
Die Inferenzmaschine («IM» in Abb. 2 und 3) entspricht den Algorithmen der einfachen Automaten in Abb. 1. Im Prinzip handelt es sich bei den Algorithmen, der Inferenzmaschine und den Regeln der Wissensbasen immer um Regeln, also um explizite ‚IF-THEN‘- Anweisungen. Diese können allerdings unterschiedlich komplex verwoben und verschachtelt sein. Sie können sich auf Zahlen oder auf Begriffe beziehen.
Die Regeln in der Wissensbasis sind nun den Regeln der Inferenzmaschine untergeordnet. Letztere kontrollieren den Fluss der Interpretation, d.h. sie entscheiden, welche Regeln der Wissensbasis anzuwenden und wie sie auszuführen sind. Die Regeln der Inferenzmaschine sind das eigentliche Programm, das vom Computer gelesen und ausgeführt wird. Die Regeln der Wissensbasis hingegen werden vom Computer nicht direkt, sondern indirekt über die Anweisungen der Inferenzmaschine ausgeführt. Es handelt sich also um eine Verschachtelung – wie sie im Übrigen typisch für die Befehle (Software) in einem Computer sind. Auch die Regeln der Inferenzmaschine werden ja nicht direkt ausgeführt, sondern von tieferen Regeln gelesen, bis hinunter zur Maschinensprache im Kern (Kernel) des Rechners. Im Prinzip sind aber die Regeln der Wissensbasis genauso Rechenregeln wie die Regeln der Inferenzmaschine, nur eben in einer ‚höheren‘ Programmiersprache. Diese zeichnet sich vorteilhafterweise dadurch aus, dass sie für die Domain-Experten, d.h. für die menschlichen Fachexperten, besonders einfach und sicher les- und handhabbar ist.
Bezüglich des in der Inferenzmaschine verwendeten Logiksystems unterscheiden wir regelbasierte Systeme
– mit statischer Logik (Typ Ontologien / Semantic Web),
– mit dynamischer Logik (Typ Begriffsmoleküle).
Siehe dazu den Beitrag ‚Die drei Neuerung der regelbasierte KI‘.
B: Korpusbasierte Systeme
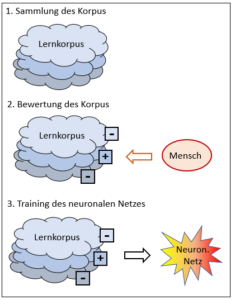
Korpusbasierte Systeme werden in drei Schritten erstellt (Abb. 4). Im ersten Schritt wird ein möglichst grosser Korpus gesammelt. Die Sammlung enthält keine Regeln, sondern Daten. Regeln wären Anweisungen, die Daten des Korpus hingegen sind keine Anweisungen; es handelt sich um reine Datensammlungen, Texte, Bilder, Spielverläufe, etc.
Abb. 4: Erstellen eines korpusbasierten Systems
Diese Daten müssen nun – im zweiten Schritt – bewertet werden. In der Regel macht das ein Mensch.
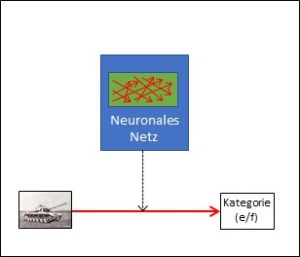
Im dritten Schritt wird ein sogenanntes neuronales Netz auf Basis des bewerteten Korpus trainiert. Das neuronale Netz ist im Gegensatz zum Datenkorpus wieder eine Regelsammlung, wie es die Wissensbasis der regelbasierten Systeme (Typ A) ist. Im Unterschied zu diesen wird das neuronale Netz aber nicht von einem Menschen trainiert, sondern vom bewerteten Korpus. Das neuronale Netz ist – im Gegensatz zur Wissensbasis – nicht explizit, d.h. nicht so ohne Weiteres einsehbar.
Abb. 5: Anwenden eines korpusbasierten Systems
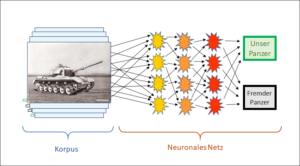
Bei der Anwendung kommt das neuronale Netz wie das regelbasierte nun ganz ohne Menschen aus. Es braucht nicht einmal mehr den Korpus. Alles Wissen steckt in den Algorithmen des neuronalen Netzes. Zudem ist das neuronale Netz durchaus in der Lage, auch schlecht strukturierten Inhalt, z.B. Pixelhaufen (Bilder) zu interpretieren, bei denen regelbasierte Systeme (Typ B) ganz schnell an ihre Grenzen stossen. Im Gegensatz zu diesen sind die korpusbasierten Systeme aber weniger erfolgreich, was komplexen Output betrifft, d.h. die Zahl der möglichen Output-Resultate darf nicht zu gross sein, da sonst die Trefferschärfe des Systems leidet. Am besten geeignet sind binäre Outputs vom Typ ‚eigener/fremder Panzer‘ (siehe Vorbeitrag) oder ‚männlicher/weiblicher Autor‘ bei der Bewertung von Twitter-Texten.
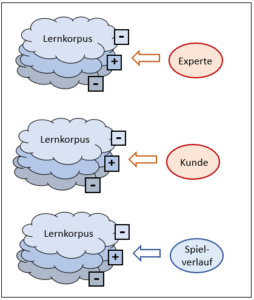
Drei Untertypen der korpusbasierten KI
Die drei Untertypen unterscheiden sich dadurch, wer die Bewertung des Korpus durchführt.
Abb. 6: Die drei Typen der korpusbasierten Systeme
B1: Typ Mustererkennung
Diesen Typ (oberes System in Abb. 6) habe ich im «Panzerbeispiel» beschrieben. Die Bewertung des Korpus erfolgt dabei durch einen menschlichen Experten.
B2: Typ Suchmaschine
Siehe mittleres Schema in Abb. 6. Bei diesem Typ erfolgt die Bewertung des Korpus durch die Kunden. Ein solches System ist im Beitrag Suchmaschine beschrieben.
B3: Typ Deep Learning
Bei diesem Typ (unterstes System in Abb. 6) ist im Gegensatz zu den oberen kein Mensch nötig, um das neuronale Netz zu bewerten. Die Bewertung ergibt sich allein durch den Spielverlauf. Dass Deep Learning aber nur unter sehr restriktiven Bedingungen möglich ist, wird im Beitrag Spiele und Intelligenz erläutert.
C: Hybride Systeme
Selbstverständlich können die oben genannten Methoden (A1 und A2, B1 bis B3) in der Praxis auch verbunden werden.
So kann z.B. ein System zur Gesichtsidentifikation so funktionieren, dass ein korpusbasiertes System des Typs B1 in den Bildern einer Überwachungskamera Gesichter als solche erkennt und in den Gesichtern die entscheidenden Formen von Augen, Mund usw. Anschliessend errechnet ein regelbasiertes System des Typs A2 aus den von System B1 markierten Punkten die Grössenverhältnisse von Augen, Nasen, Mund etc., die ein individuelles Gesicht auszeichnen. Durch eine solche Kombination von korpus- und regelbasiertem System können auf den Bildern individuelle Gesichter erkannt werden. Der erste Schritt wäre für ein System A2 nicht möglich, der zweite Schritt für ein System B1 viel zu kompliziert und ungenau. Ein Hybrid macht es möglich.
Im Folgebeitrag beantworte ich die Frage, wo in all diesen Systemen nun die Intelligenz steckt. Aber vermutlich haben Sie die Antwort längst selbst erkannt.
Im Vorbeitrag haben wir gesehen, dass bei der regelbasierten KI die Intelligenz in den Regeln steckt. Diese Regeln sind menschengemacht und das System ist so intelligent wie die Menschen, die die Regeln geschrieben haben. Wie sieht das nun bei der korpusbasierten Intelligenz aus?
Die Antwort ist etwas komplizierter als bei den regelbasierten Systemen. Schauen wir deshalb den Aufbau eines solchen korpusbasierten Systems genauer an. Er geschieht in drei Schritten:
Erstellen einer möglichst grossen Datensammlung (Korpus)
Bewertung dieser Datensammlung
Training des neuronalen Netzes (Lernphase)
Sobald das Netz erstellt ist, kann es angewendet werden:
Anwendung des neuronalen Netzes
Schauen wir die vier Schritte genauer an und überlegen wir uns dabei, worauf es ankommt und wo die Intelligenz in das korpusbasierte System hineinkommt.
Schritt 1: Erstellung der Datensammlung
In unserem Panzerbeispiel besteht der Korpus (die Datensammlung) aus Photographien von Panzern. Bilder sind typisch für korpusbasierte Intelligenz, aber die Sammlung kann natürlich auch andere Informationen enthalten, z.B. Suchanfragen von Kunden einer Suchmaschine oder GPS-Daten von Handys. Typisch ist, dass die Daten von jedem einzelnen Eintrag aus so vielen Einzelelementen (z.B. Pixeln) bestehen, dass Ihre Auswertung mit bewusst von Menschen konstruierten Regeln zu aufwendig wird. Dann lohnt sich ein regelbasiertes System nicht mehr.
Die Sammlung der Daten reicht aber nicht aus. Sie müssen jetzt auch bewertet werden.
Schritt 2: Bewertung des Korpus
Abb. 1: Korpusbasiertes System
Abb. 1 zeigt das bereits bekannte Bild aus unserem Panzerbeispiel. Auf der linken Seiten sehen Sie den Korpus. Dieser ist in der Abbildung bereits bewertet, die Bewertung ist symbolisiert durch die kleinen schwarzen und grünen Fähnchen (Flags) links an jedem Panzerbild.
Man kann sich den bewerteten Korpus vereinfacht als eine zweispaltige Tabelle vorstellen. In der linken Spalte sitzt die Bildinformation, in der rechten die Bewertung und der Pfeil dazwischen ist die Zuordnung, die somit ein wesentlicher Teil des Korpus wird, sie sagt nämlich, zu welcher Kategorie (e oder f) das jeweilige Bild gehört, wie es also bewertet wird.
Tabelle 1: Korpus mit Bewertungen (e=eigen, f=fremd)
Typischerweise sind die Informationsmengen in den beiden Spalten von sehr unterschiedlicher Grösse. Während die Bewertung in der rechten Spalte in unserem Panzerbeispiel aus genau einem Bit besteht, enthält das Bild der linken Spalte alle Pixel der Photographie; zu jedem Pixel sind Lage, Farbe usw. abgespeichert, also eine ziemlich grosse Datenmenge. Dieser Unterschied im Grössenverhältnis ist typisch für korpusbasierte Systeme – und falls Sie philosophisch interessiert sind, möchte ich auf den Bezug zum Thema Informationsreduktion und Entropie hinweisen . Im Moment geht es uns aber um die Intelligenz in den korpusbasierten KI-Systemen und wir halten dazu fest, dass im Korpus zu jedem Bild seine korrekte Zielkategorie fest zugeordnet wird.
Bei dieser Zuordnung wissen wir nicht, wie sie geschieht, denn sie wird durch einen Menschen durchgeführt, mit den Neuronen in seinem eigenen Kopf, deren genaues Verhalten ihm wohl kaum bewusst ist. Er könnte also nicht Regeln dafür angeben. Hingegen weiss er, was die Bilder darstellen, und vermerkt das im Korpus, eben mit der Zuordnung der entsprechenden Kategorie. Diese Zuordnung kommt von aussen durch den Menschen in den Korpus, sie ist zu hundert Prozent menschengemacht. Gleichzeitig ist diese Bewertung eine absolute Bedingung und die Grundlage für den Aufbau des neuronalen Netzes. Auch später, wenn das fertig trainierte neuronale Netz den Korpus mit den von aussen eingebrachten Zuordnungen nicht mehr braucht, war er doch vorher notwendig, damit das Netz überhaupt entsteht und arbeiten kann.
Woher stammt also die Intelligenz bei der Zuordnung der Kategorien e) und f)? Es ist letztlich ein Mensch, der diese Zuordnung macht und auch falsch machen kann; es handelt sich um seine Intelligenz. Sobald die Zuordnung im Korpus einmal notiert ist, handelt es sich nicht mehr um aktive Intelligenz, sondern um fixiertes Wissen.
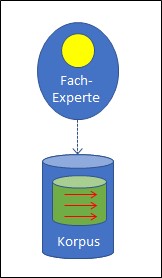
Abb. 2: Bewertung des Korpus
Die Bewertung des Korpus ist eine entscheidende Phase, und Intelligenz ist dabei zweifellos nötig. Die zusammen getragene Datensammlung muss bewertet werden und der Fachexperte, der diese Bewertung durchführt, muss garantieren, dass sie korrekt ist. In Abb. 2 ist die Intelligenz des Fachexperten durch den gelben Kreis repräsentiert. Der Korpus erhält das so erstellte Wissen über die Zuordnungen; die Zuordnungen selber sind in Abb. 2 als rote Pfeile dargestellt.
Wissen ist etwas anderes als die Intelligenz. Es ist einem gewissen Sinn passiv. In diesem Sinn handelt es sich bei den im Korpus festgehaltenen Informationen um Wissensobjekte, d.h. um Zuordnungen, die formuliert sind und nicht mehr bearbeitet werden müssen. Intelligenz hingegen ist ein aktives Prinzip, das selber Wertungen vornehmen kann, so wie es der menschliche Experte tut. Bei den Elementen im Korpus aber handelt es sich um Daten oder dann bei den erwähnten Zuordnungen um Resultate der Intelligenz von Experten – also um fest formuliertes Wissen.
Um dieses Wissen von der Intelligenz zu unterscheiden, habe ich es in Abb. 2 nicht gelb, sondern grün markiert.
Wir unterscheiden somit sinnvollerweise drei Dinge:
– Daten (die Datensammlung im Korpus)
– Wissen (die durchgeführte Bewertung dieser Daten)
– Intelligenz (die Fähigkeit, diese Bewertung durchzuführen).
Schritt 3: Training des neuronalen Netzes
Abb. 3: Das neuronale Netz lernt das Wissen des Korpus
In der Trainingsphase wird auf Basis des Lernkorpus das neuronale Netz aufgebaut. Damit das funktioniert, ist wieder eine beträchtliche Intelligenz notwendig, diesmal kommt sie vom KI-Experten, der das Funktionieren der Lernphase ermöglicht und steuert. Dabei spielen Algorithmen eine Rolle, die dafür verantwortlich sind, dass das Wissen im Korpus korrekt ausgewertet wird und das neuronale Netz genau die Form erhält, die bewirkt, dass alle im Korpus festgehaltenen Zuordnungen auch durch das Netz nachvollzogen werden können.
Die Wissensextraktion und die dabei verwendeten Algorithmen sind durch den braunen Pfeil zwischen Korpus und Netz symbolisiert. Wenn man will, kann man ihnen durchaus eine gewisse Intelligenz zubilligen, doch sie tun nichts, was nicht vom IT-Experten bzw. vom Wissen im Korpus vorgegeben wird. Das entstehende neuronale Netz selber hat keine eigene Intelligenz, sondern ist das Ergebnis dieses Prozesses und somit der Intelligenz der Experten. Es enthält aber beträchtliches Wissen und ist deshalb in Abb. 3 grün dargestellt, wie das Wissen im Korpus in Abb. 2. Im Gegensatz zum Korpus sind die Zuweisungen (rote Pfeile) aber jetzt wesentlich komplexer, genau so, wie es in einem neuronalen Netz eben komplexer zu und her geht als in einer einfachen zweispaltigen Tabelle (Tabelle 1).
Und noch etwas unterscheidet das Wissen im Netz vom Wissen im Korpus: Im Korpus handelt es sich um Wissen über Einzelfälle, im Netz hingegen ist das Wissen abstrakt. Es kann deshalb auch auf bisher unbekannte Fälle angewendet werden.
Schritt 4: Anwendung
Abb. 4: Anwendung eines neuronalen Netzes
In Abb. 4 wird ein bisher unbekanntes Bild vom neuronalen Netz bewertet und entsprechend dem im Netz gespeicherten Wissen kategorisiert. Dabei ist kein Korpus und auch kein Experte mehr nötig, es reichen die ‚geschulten‘, aber jetzt feststehenden Verdrahtungen im neuronalen Netz. Das Netz ist in diesem Moment nicht mehr in der Lage, etwas dazuzulernen. Es ist aber fähig zu durchaus eindrücklichen Leistungen mit ganz neuem Input. Diese Leistungen werden ermöglicht durch die vorgängigen Arbeiten, also den Aufbau des Korpus, die in ihm enthaltenen, (hoffentlich) korrekten Bewertungen und den Algorithmen der Lernphase. Hinter dem Lernkorpus steckt die menschliche Intelligenz des Fachexperten, hinter den Algorithmen der Trainingsphase die menschliche Intelligenz des IT-Experten.
Fazit
Was uns als künstliche Intelligenz erscheint, ist das Resultat der durchaus menschlichen, d.h. natürlichen Intelligenz der Fachexperten und IT-Spezialisten.
Dies ist ein Beitrag zum Thema künstliche Intelligenz. Im nächsten Beitrag schauen wir noch genauer hin. Wir schauen, was für Wissen in einem Korpus wirklich steckt. Und was die KI aus dem Korpus herausholen kann und was nicht.
Haben die neuronalen Netze die regelbasierten Systeme abgehängt?
Es ist nicht zu übersehen: Die korpusbasierte KI hat die regelbasierte KI um Längen überholt. Neuronale Netze machen das Rennen, wohin man schaut. Schläft die Konkurrenz? Oder sind regelbasierte Systeme schlicht nicht in der Lage, gleichwertige Ergebnisse wie neuronale Netze zu erzielen?
Meine Antwort ist, dass die beiden Methoden aus Prinzip für sehr unterschiedliche Aufgaben prädisponiert sind. Ein Blick auf die jeweiligen Wirkweisen macht klar, wofür die beiden Methoden sinnvollerweise eingesetzt werden. Je nach Fragestellung ist die eine oder die andere im Vorteil.
Trotzdem bleibt das Bild: Die regelbasierte Variante scheint auf der Verliererspur. Woher kommt das?
In welcher Sackgasse steckt die regelbasierte KI?
Meines Erachtens hat das Hintertreffen der regelbasierten KI damit zu tun, dass sie ihre Altlasten nicht loswerden will. Dabei wäre es so einfach. Es geht darum:
Semantik als eigenständiges Wissensgebiet zu erkennen
Komplexe Begriffsarchitekturen zu verwenden
Eine offene und flexible Logik (NMR) einzubeziehen.
Wir tun dies seit über 20 Jahren mit Erfolg. Andernorts allerdings ist
die Notwendigkeit dieser drei Neuerungen und des damit verbundenen Paradigmenwechsels noch nicht angekommen.
Was bedeuten die drei Punkte nun im Detail?
Punkt 1: Semantik als eigenständiges Wissensgebiet erkennen
Üblicherweise ordnet man die Semantik der Linguistik zu. Dem wäre im Prinzip nichts entgegen zu halten, doch in der Linguistik lauert für die Semantik eine kaum bemerkte Falle: Linguistik beschäftigt sich mit Wörtern und Sätzen. Der Fehler entsteht dadurch, dass man die Bedeutung, d.h. die Semantik, durch den Filter der Sprache sieht und glaubt, ihre Elemente auf die gleiche Weise anordnen zu müssen, wie die Sprache das mit den Wörtern macht. Doch die Sprache unterliegt einer entscheidenden Einschränkung, sie ist linear, d.h. sequenziell: Ein Buchstabe kommt nach dem anderen, ein Wort nach dem anderen. Es ist nicht möglich, Wörter parallel nebeneinander zu setzen. Im Denken können wir das aber. Und wenn wir die Semantik von etwas untersuchen, geht es darum, wie wir denken und nicht, wie wir sprechen.
Wir müssen also Formalismen finden für die Begriffe, wie sie im Denken vorkommen. Die Beschränkung durch die lineare Anordnung der Elemente und die sich daraus ergebende Notwendigkeit, behelfsweise und in jeder Sprache anders mit grammatikalischen Kunstgriffen Klammerungen und komplexe Beziehungsstrukturen nachzubilden, diese Beschränkung gilt im Denken nicht und wir erhalten dadurch auf der semantischen Seite ganz andere Strukturen als auf der sprachlichen Seite.
Wort ≠ Begriff
Was sicher nicht funktioniert, ist eine simple «semantische Annotation» von Wörtern. Ein Wort kann viele, sehr unterschiedliche Bedeutungen haben. Eine Bedeutung (= ein Begriff) kann durch unterschiedliche Wörter ausgedrückt werden. Wenn man Texte analysieren will, darf man nicht die einzelnen Wörter, sondern muss immer den Gesamtkontext ansehen. Nehmen wir das Wort «Kopf». Wir sprechen z.B. vom Kopf eines Briefes oder vom Kopf eines Unternehmens. Wir können nun den Kontext in unseren Begriff hineinnehmen, indem wir den Begriff <Kopf< mit anderen Begriffen verbinden. So gibt es einen <Körperteil<Kopf< und eine <Funktion<Kopf<. Der Begriff links (<Körperteil<) sagt dann aus, von welchem Typ der Begriff rechts (<Kopf<) ist. Wir typisieren also. Wir suchen den semantischen Typ eines Begriffs und setzen ihn vor den Unterbegriff.
Konsequent komposite Datenelemente
Die Verwendung typisierter Begriffe ist nichts Neues. Wir gehen aber weiter und bilden ausgedehnte strukturierte Graphen, diese komplexen Graphen bilden dann die Basis unserer Arbeit. Das ist etwas ganz anderes als die Arbeit mit Wörtern. Die Begriffsmoleküle, die wir verwenden, sind solche Graphen, die eine ganz spezielle Struktur aufweisen, sodass sie sowohl für Menschen wie für Maschinen leicht und schnell lesbar sind. Die komposite Darstellung hat viele Vorteile, einer ist z.B. dass der kombinatorischen Explosion ganz einfach begegnet wird und so die Zahl der atomaren Begriffe und Regeln drastisch gekürzt werden kann. Durch die Typisierung und die Attribute können ähnliche Begriffe beliebig geschärft werden, wir können mit Molekülen dadurch sehr präzis «sprechen». Präzision und Transparenz der Repräsentation haben darüber hinaus viel damit zu tun, dass die spezielle Struktur der Graphen (Moleküle) direkt von der multifokalen Begriffsarchitektur abgeleitet ist (siehe im folgenden Punkt 2).
Punkt 2: Komplexe Begriffsarchitekturen verwenden
Begriffe sind in den Graphen (Begriffsmoleküle) über Relationen verbunden. Die oben genannte Typisierung ist eine solche Relation: Wenn der <Kopf< als ein <Körperteil< gesehen wird, dann ist er vom Typ <Körperteil< und es besteht eine ganz bestimmte Relation zwischen <Kopf< und <Körperteil<, nämlich eine sogenannte hierarchische oder ‚IS-A‚-Relation – letzteres darum, weil man bei hierarchischen Relationen immer ‚IST-EIN‘ sagen kann, also in unserem Fall: der <Kopf< ist ein <Körperteil<.
Die Typisierung ist eine der beiden grundlegenden Relationen in der Semantik. Wir ordnen eine Anzahl Begriffe einem übergeordneten Begriff, also ihrem Typ zu. Dieser Typ ist natürlich genauso ein Begriff und er kann deshalb selber wieder typisiert werden. Dadurch entstehen hierarchische Ketten von ‚IS-A‘-Relationen, mit zunehmender Spezifizierung, z.B. <Gegenstand<Möbel<Tisch<Küchentisch<. Wenn wir alle Ketten der untergeordneten Begriffe, die von einem Typ ausgehen, zusammenbinden, erhalten wir einen Baum. Dieser Baum ist der einfachste der vier Architekturtypen für die Anordnung von Begriffen.
Von dieser Baumstruktur gehen wir aus, müssen aber erkennen, dass eine blosse Baumarchitektur entscheidende Nachteile hat, die es verunmöglichen, damit wirklich präzis greifende Semantiken zu bauen. Wer sich für die verbesserten und komplexerenArchitekturtypen und ihre Vor- und Nachteile interessiert, findet eine ausführliche Darstellung der vier Architekturtypen auf der Website von meditext.ch.
Bei den Begriffsmolekülen haben wir den gesamten Formalismus, d.h. die innere Struktur der Regeln und Moleküle selbst auf die komplexen Architekturen ausgerichtet. Das bietet viele Vorteile, denn die Begriffsmoleküle weisen jetzt in sich genau die gleiche Struktur auf wie die Achsen der multifokalen Begriffsarchitektur. Man kann die komplexen Faltungen der multifokalen Architektur als Gelände auffassen, mit den Dimensionen oder semantischen Freiheitsgraden als komplex verschachtelte Achsen. Die Begriffsmoleküle nun folgen diesen Achsen in ihrer eigenen inneren Struktur. Das macht das Rechnen mit den Molekülen so einfach. Mit simplen Hierarchiebäumen oder multidimensionalen Systemen würde das nicht funktionieren. Und ohne konsequent komposite Datenelemente, deren innere Struktur auf fast selbstverständliche Weise den Verzweigungen der komplexen Architektur folgt, auch nicht.
Punkt 3: Eine offene und flexible Logik (NMR) einbeziehen
Dieser Punkt ist für theoretisch vorbelastete Wissenschaftler möglicherweise der härteste. Denn die klassische Logik erscheint den meisten unverzichtbar und viele kluge Köpfe sind stolz auf ihre Kenntnisse darin. Klassische Logik ist in der Tat unverzichtbar – nur muss sie am richtigen Ort eingesetzt werden. Meine Erfahrung zeigt, dass wir im Bereich des NLP (Natural Language Processing) eine andere Logik brauchen, nämlich eine, die nicht monoton ist. Eine solche nichtmonotone Logik (NMR) erlaubt es, für das gleiche Resultat mit viel weniger Regeln in der Wissensbasis auszukommen. Die Wartung wird dadurch zusätzlich vereinfacht. Auch ist es möglich, das System ständig weiter zu entwickeln, weil es logisch offen bleibt. Ein logisch offenes System mag einen Mathematiker beunruhigen, die Erfahrung aber zeigt, dass ein NMR-System für die regelbasierte Erfassung des Sinns von frei formuliertem Text wesentlich besser funktioniert als ein monotones.
Fazit
Heute scheinen die regelbasierten Systeme im Vergleich zu den korpusbasierten im Hintertreffen zu sein. Dieser Eindruck täuscht aber und rührt daher, dass die meisten regelbasierten Systeme den Sprung in ein modernes System noch nicht vollzogen haben. Dadurch sind sie entweder:
nur für Aufgaben in kleinem und wohldefiniertem Fachgebiet anwendbar oder
sehr rigid und deshalb kaum einsetzbar oder
sie benötigen einen unrealistischen Ressourceneinsatz und werden unwartbar.
Wenn wir aber konsequent komposite Datenelemente und höhergradige Begriffsarchitekturen verwenden und bewusst darauf verzichten, monoton zu schliessen, kommen wir – für die entsprechenden Aufgaben – mit regelbasierten Systemen weiter als mit korpusbasierten.
Regelbasierte und korpusbasierte Systeme sind sehr unterschiedlich und je nach Aufgabe ist das eine oder das andere im Vorteil. Darauf werde ich in einem späteren Beitrag eingehen.
Dies ist ein Beitrag zum Thema künstliche Intelligenz (KI). Ein Folgebeitrag beschäftigt sich mit der aktuellen Verbreitung der beiden KI-Methoden.