Wie kommt die Intelligenz in die Suchmaschine?
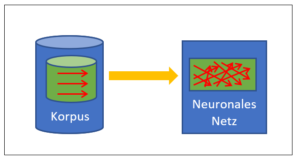
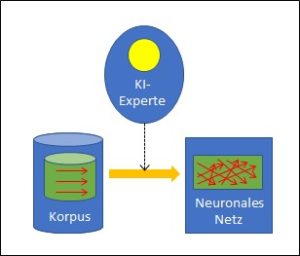
Nehmen wir an, Sie bauen eine Suchmaschine. Sie wollen dabei möglichst keine teuren und nicht immer fehlerfreien menschlichen Fachexperten (domain experts) einsetzen, sondern die Suchmaschine nur mit ausreichend Datenservern (der Hardware für den Korpus) und einer ausgeklügelten Software bauen. Wieder verwenden Sie im Prinzip ein neuronales Netz mit einem Korpus. Wie bringen Sie nun die Intelligenz in Ihr System?
Trick 1: Lass die Kunden den Korpus trainieren
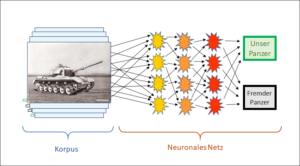
Bei einer Suchmaschine geht es wie bei der Panzer-KI der Vorbeiträge um Zuordnungen, diesmal von einem Eingabetext (Suchstring) eines Kunden zu einer Liste von Webadressen, die für seine Suche interessant sein könnten. Um die relevanten Adressen zu finden, basiert Ihr System wiederum auf einem Lernkorpus, der diesmal aus der Liste aller Sucheingaben von allen Ihren bisherigen Kunden besteht. Die Webadressen, die die früheren Kunden aus den ihnen angebotenen auch tatsächlich angeklickt haben, sind im Korpus als positive Hits vermerkt. Also geben Sie bei neuen Anfragen – auch von anderen Kunden – einfach die Adressen an, die bisher am meisten Klicks erhalten haben. So schlecht können die ja nicht sein, und mit jeder Anfrage und dem darauf folgenden Klick verfeinert sich das System. Und dann gilt: Je grösser der Korpus, umso präziser.
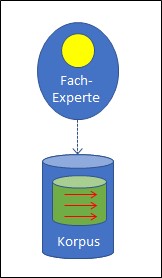
Wieder stammen diese Zuordnungen von aussen, nämlich von den Menschen, die die Auswahl, die Ihre Suchmaschine ihnen angeboten hat, mit ihren Klicks entsprechend bewertet haben. Die Menschen haben das getan:
- mit ihrer menschlichen Intelligenz und
- entsprechend ihren jeweiligen Interessen.
Besonders der zweite Punkt ist interessant. Wir könnten später noch etwas detaillierter darauf eingehen.
Trick 2: Bewerte die Kunden dabei mit
Nicht jede Zuordnung von jedem Kunden ist gleich relevant. Als Suchmaschinenbetreiber können Sie hier an zwei Punkten optimieren:
- Bewerten Sie die Bewerter:
Sie kennen ja alle Eingaben Ihrer Kunden. So können Sie leicht herausfinden, wie verlässlich die von ihnen gemachten Zuordnungen (die angeklickte Webadressen zu den eingegebenen Suchstrings) sind. Nicht alle Ihre Kunden sind in dieser Hinsicht gleich gut. Je mehr andere Kunden für den gleichen Suchstring die gleiche Webadresse anwählen, umso sicherer wird die Zuordnung auch für zukünftige Anfragen sein. Verwenden Sie nun diese Information, um die Kunden zu gewichten: Der Kunde, der bisher die verlässlichsten Zuordnungen hatte, d.h. derjenige, der am meisten das wählte, was die anderen auch wählten, wird am höchsten gewichtet. Einer, dem die anderen weniger folgten, gilt als etwas weniger verlässlich. Durch die Gewichtung erhöhen Sie die Wahrscheinlichkeit, dass die zukünftigen Suchergebnisse die Websites höher bewerten, die die meisten Kunden interessieren. - Bewerten Sie die Sucher:
Nicht jeder Suchmaschinenbenutzer hat die gleichen Interessen. Das können Sie berücksichtigen, denn Sie kennen ja bereits alle früheren Eingaben von ihm. Diese können Sie verwenden, um ein Profil von ihm zu erstellen. Das dient natürlich dazu, die Suchergebnisse für ihn entsprechend auszuwählen. Bewerter mit einem ähnlichen Profil wie der Sucher werden die potenziellen Adressen auch ähnlich gewichten, und sie können so die Suchergebnisse noch mehr im Interesse des Kunden personalisieren.
Es lohnt sich für Sie als Suchmaschinenbetreiber auf jeden Fall, von allen Ihren Kunden ein Profil zu erstellen, nur schon zur Verbesserung der Qualität der Suchvorschläge.
Konsequenzen
- Suchmaschinen werden durch den Gebrauch immer präziser.
Das gilt für alle korpusbasierten Systeme, also für alle Technologien mit neuronalen Netzen: Je grösser ihr Korpus ist, desto besser ist ihre Präzision. Sie können zu erstaunlichen Leistungen fähig sein. - In diesem Zusammenhang lässt sich ein bemerkenswerter Rückkopplungseffekt feststellen: Je grösser ihr Korpus ist, umso besser ist die Qualität einer Suchmaschine und deshalb wird sie häufiger benützt, was wiederum ihren Korpus vergrössert und so ihre Attraktivität gegenüber der Konkurrenz steigert. Dieser Effekt führt unweigerlich zu den Monopolen, wie sie typisch sind für alle Anwendungen von korpusbasierter Software.
- Alle Bewertungen sind primär von Menschen erstellt worden.
Die Basis der Intelligenz – die zuordnenden Eingaben im Korpus – erfolgen weiterhin durch Menschen. Bei den Suchmaschinen ist das jeder einzelne Benutzer, der so sein Wissen in den Korpus eingibt. So künstlich ist die Intelligenz in dieser KI also gar nicht. - Korpusbasierte Systeme tragen die Tendenz zur Blasenbildung in sich: Wenn Suchmaschinen von ihren Kunden Profile anlegen, können sie diese mit besseren Suchergebnissen bedienen. Das führt aber in einem selbstreferenziellen Prozess unweigerlich zu einer Blasenbildung: Anwender mit ähnlichen Ansichten werden von den Suchmaschinen immer näher zusammen gebracht, da sie auf diese Weise die Suchergebnisse erhalten, die ihren jeweiligen Interessen und Ansichten am besten entsprechen. Abweichende Ansichten bekommen sie immer weniger zu Gesicht.
Dies ist ein Beitrag zum Thema künstliche Intelligenz. Im nächsten Beitrag geht es um einen weiteren wichtigen Aspekt der korpusbasierten Systeme, nämlich um die Rolle der Wahrscheinlichkeit.