Wie beeinflusst die Geschichte der KI ihre Zukunft?
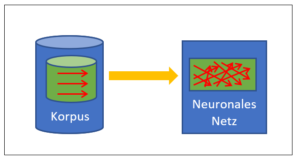
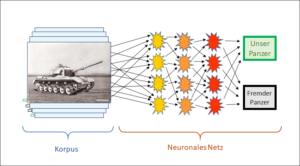
Heute ist mit KI die Methode der Neuronalen Netze gemeint. Dies ist eine ganz spezielle Form der Maschinenintelligenz, die auf der statistische Auswertung von riesigen Datenmengen beruht. Der geschichtliche Blick sieht sich neben dieser sehr erfolgreichen, statistischen Methode die Maschinenintelligenz ganz allgemein. Wie hat sich diese entwickelt? Was sind ihre Wurzlen. Wohin führt sie?
Heutige, offene Denker stellen der ‚traditionellen‘ Vergangenheit gern eine neue ‚originelle‘ Zukunft gegenüber. Doch wir wissen alle nicht, was in der Zukunft wirklich sein wird – auch wenn ich selber darüber gern spekuliere.
Die Tradition ist für die Zukunft nützlich, wenn man sich eingesteht, dass Sie folgende vier unterscheidbare Elemente enthält:
- Ungelöste Fragen, die heute beantwortet werden können und den Boden der Zukunft bilden
- Erkannte Fehler, die in der Zukunft korrigiert werden können
- Verschmähte Perlen, die von der Gegenwart ignoriert, aber in Zukunft wieder Bedeutung erlangen können.
- Bleibendes, das auch in Zukunft gilt
Diese unterschiedlichen Elemente der Tradition zu unterscheiden ist nicht einfach, doch genau darum geht es.
Wissenschaftsgeschichte
Wissenschaftsgeschichte hat mich seit der Schule interessiert. So enthält zum Beispiel die Medizingeschichte viele verblüffende Wendungen, was angewendeten Praktiken und die ihnen zugrundelegenden Erklärungen betrifft. Das ist faszinierend. Im Medizinstudium hat mich die Geschichte der Medizin brennend interessiert, die voll ist von Erneuerungen, Paradigmenwechseln und ideologischen Vorgaben. Sehr spannend, und den Ärzten und der Allgemeinheit kaum bekannt.
Ganz ähnlich steht es um die Geschichte der Informationswissenschaft. Auch hier sind die divergierenden Elemente a) bis d) deutlich zu erkennen, doch auch diese Geschichte ist der Allgemeinheit und den Fachspezialisten kaum bekannt. Die IT-Geschichte wird von den aktuellen Diskussionen um die AI und ihren Einfluss auf unsere Gesellschaft völlig überblendet. Dabei hilft erst der Blick auf die Geschichte, die heutigen Herausforderungen in einem nüchternen Blick zu sehen.
Informationswissenschaft
Die Geschichte der Informationswissenschaft kann bis zu den Syllogismen von Aristoteles zurückverfolgt werden. Rechenmaschinen und ihre Theorie finden sich z.B. im Mittelalter beim missionierenden Franziskaner und Logiker Ramon Lullus und im Barock beim Universalgelehrten Gottfried Wilhelm Leibniz.
In der Mitte des 20. Jahrhundert finden wir dann eine wirkmächtige Entwicklung, eine eigentliche ‚kybernetische Welle‚ mit vielen Facetten und Köpfen, die am Ursprung der heutigen IT-Explosion steht.
Zur Kybernetischen Welle gehört neben vielen anderen der Ingenieur Claude Shannon, der für die Telefongesellschaft Bell das Leibniz’sche Bit aufgegriffen und in die Berechnungen der Telefonsignale eingeführt hat, oder der Praktiker Zuse, der in Berlin den ersten funktionierenden Computer im heutigen Sinn gebaut hat. Zur vielköpfigen ‚kybernetischen Welle‘ gehören unter anderen der Antroposoph und Logiker Gregory Bateson, der Österreich-Amerikaner Heinz von Förster, der Mathematikerschreck George Spencer-Brown, der britische Radarpionier Donald MacKay und die enthusiastische amerikanische Pionierszene der Kybernetik der 50-er und 60-er Jahre, eine bemerkenswerte Kombination von intellektuellen Hippies und an neuen Techniken interessierten Nachrichtenoffizieren, die sich damals z.B. in den Macy-Konferenzen fanden, und die zusammen die gesamte heutige IT inklusive AI recht eigentlich begründet haben.
Zur kybernetischen Welle gehören für mich aber auch Nicht-Informatiker wie der Schriftsteller Stanislaw Lem, der in den «Sterntagebüchern» einen raumfahrenden Baron von Münchhausen auftreten lässt, Ijon Tichy genannt. In den fiktiven Reisebeschreibungen, die zwischen 1957 und 1971 entstanden, werden nicht zuletzt logische Probleme, insbesondere solche der KI, exemplarisch behandelt. Klügere Literatur zu Logik und Auswirkung der KI habe ich nirgendwo gefunden.
Auch der Mathematiker und Physiker Roger Penrose muss erwähnt werden, der zur Kosmologie der Entropie – der physikalischen Dimension von Information – geforscht hat und dessen Buch ‚Emperors New Mind‚ im Jahr 1989 als Kritik an einer überbordenden KI-Gläubigkeit entstand, im Endergebnis aber einen ausführlichen und fundierten Einblick in das physikalische Wissen am Ende des 20. Jahrhunderts ermöglicht.
Die erwähnten Kybernetiker, Philosophen, Naturwissenschaftler und Schriftsteller sind die praktischen Begründer und Vordenker der KI. Sie ringen stets auch um philosophischen Fragen. Sie beschäftigen sich nicht zuletzt intensiv mit der Fragen der Logik – geschlossen oder doch offen? – und der Rolle der KI, also der Frage, wie Intelligenz und Maschinen vereinbar sind.
Was bringt nun die Zukunft?
Wir können die Zukunft gestalten, indem wir auf die oben erwähnten Elemente der Vergangenheit reagieren und versuchen …
- zu antworten: In den ungelösten Fragen der Verganenheit liegt die Zukunft
- zu erkennen: Die blinden Flecken und Tabus der Vergenheit.
- zu schätzen: Nicht alles von früher ist schlecht.
- zu behalten: Was ist der bleibende Kern?